The initial release of this project focuses on the Bradley-Terry reward modeling and pairwise preference model. Since then, we have included more advanced techniques to construct a preference model. The structure of this project is
bradley-terry-rmto train the classic Bradley-Terry reward model;pair-pmto train the pairwise preference model, which takes a prompt and two responses as the input and directly predicts the probability of the first response being preferred. We formulate the problem as a chat between the user and the model to leverage the next-token prediction ability of the model, which is referred to as generative RM in the subsequent literature.SSRM: the code of the paper Semi-Supervised Reward Modeling via Iterative Self-TrainingRRM: to leverage causal inference to augment the preference dataset and mitigate the reward hacking. See https://arxiv.org/pdf/2409.13156v1
armo-rmto train the ArmoRM, which starts with a multi-objective reward model, and the reward vector is aggregated by a mixture-of-expert approach in a context-dependent way. See our technical report [ArmoRM] Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts for details.odin-rmto disentangle the reward modeling from length bias. See https://arxiv.org/pdf/2402.07319math-rm: the code to train process-supervised reward (PRM) and outcome-supervised reward (ORM) using the next-token prediction. We open-source the data, code, hyper-parameter, and model for a robust recipe that is easy to reproduce.
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
🚀 [Nov 2024] PRM and ORM training codes are released under the math-rm/ folder!
🚀 [Sep 2024] ArmoRM training code is released under the armo-rm/ folder!
🚀 [Sep 2024] Code for Semi-Supervised Reward Modeling via Iterative Self-Training is released under the pair-pm/ folder
🚀 [Jun 2024] Our ArmoRM is the Rank #1 8B model on RewardBench!
🚀 [May 2024] The top-3 open-source 8B reward models on RewardBench (ArmoRM, Pair Pref. Model, BT RM) are all trained with this repo!
🚀 [May 2024] The pairwise preference model training code is available (pair-pm/)!
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
-
Tech Report
-
Models:
- Absolute-Rating Multi-Objective Reward Model (ArmoRM): ArmoRM-Llama3-8B-v0.1
- Pairwise Preference Reward Model: pair-preference-model-LLaMA3-8B
- Bradley-Terry Reward Model: FsfairX-LLaMA3-RM-v0.1
-
Architectures
- Bradley-Terry (BT) Reward Model and Pairwise Preference Model

- Absolute-Rating Multi-Objective Reward Model (ArmoRM)

- Bradley-Terry (BT) Reward Model and Pairwise Preference Model
-

Model Base Model Method Score Chat Chat Hard Safety Reasoning Prior Sets (0.5 weight) ArmoRM-Llama3-8B-v0.1 (Ours) Llama-3 8B ArmoRM + MoE 89.0 96.9 76.8 92.2 97.3 74.3 Cohere May 2024 Unknown Unknown 88.2 96.4 71.3 92.7 97.7 78.2 pair-preference-model (Ours) Llama-3 8B SliC-HF 85.7 98.3 65.8 89.7 94.7 74.6 GPT-4 Turbo (0125 version) GPT-4 Turbo LLM-as-a-Judge 84.3 95.3 74.3 87.2 86.9 70.9 FsfairX-LLaMA3-RM-v0.1 (Ours) Llama-3 8B Bradley-Terry 83.6 99.4 65.1 87.8 86.4 74.9 Starling-RM-34B Yi-34B Bradley-Terry 81.4 96.9 57.2 88.2 88.5 71.4 -
Evaluation Results (from RLHF Workflow)

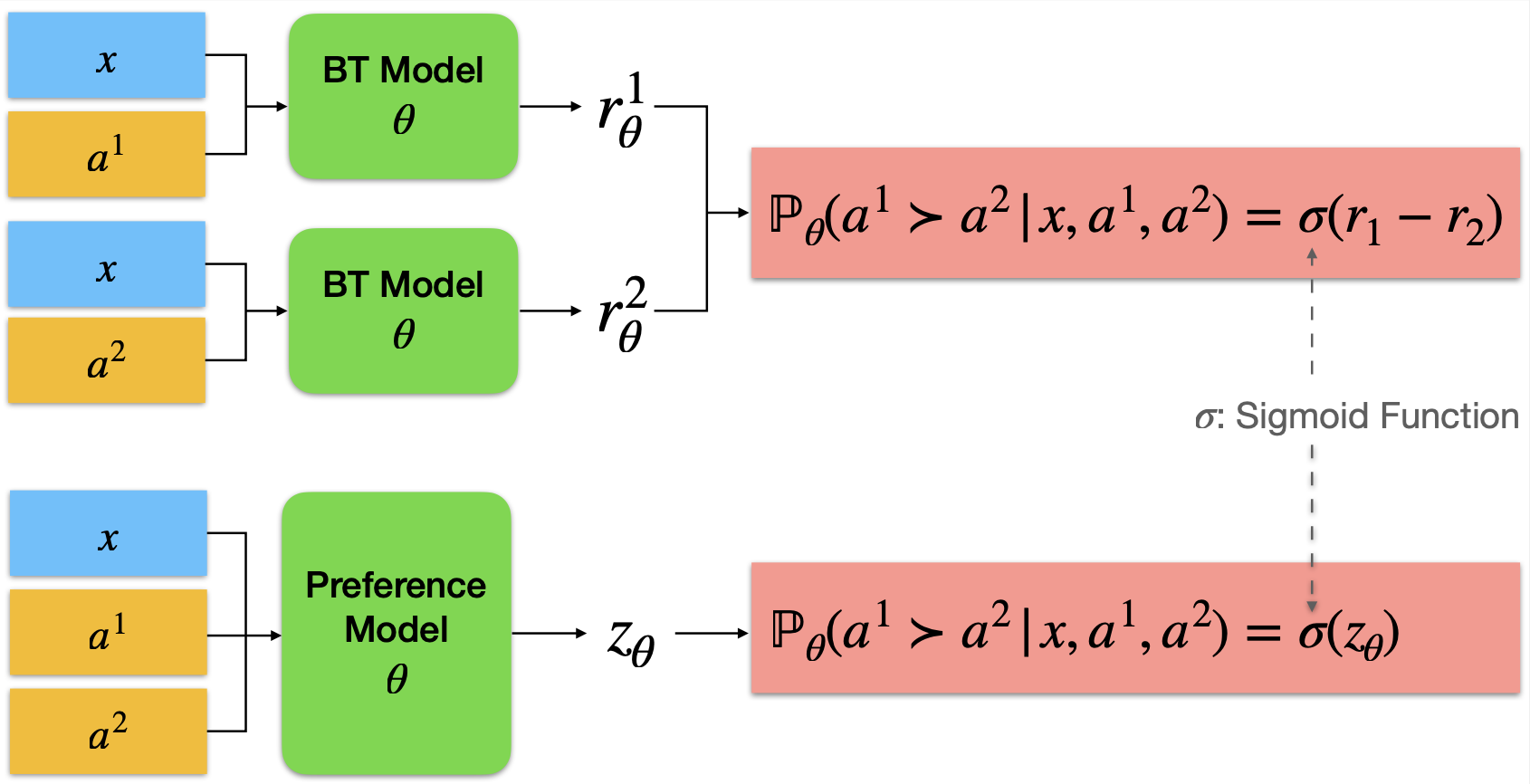
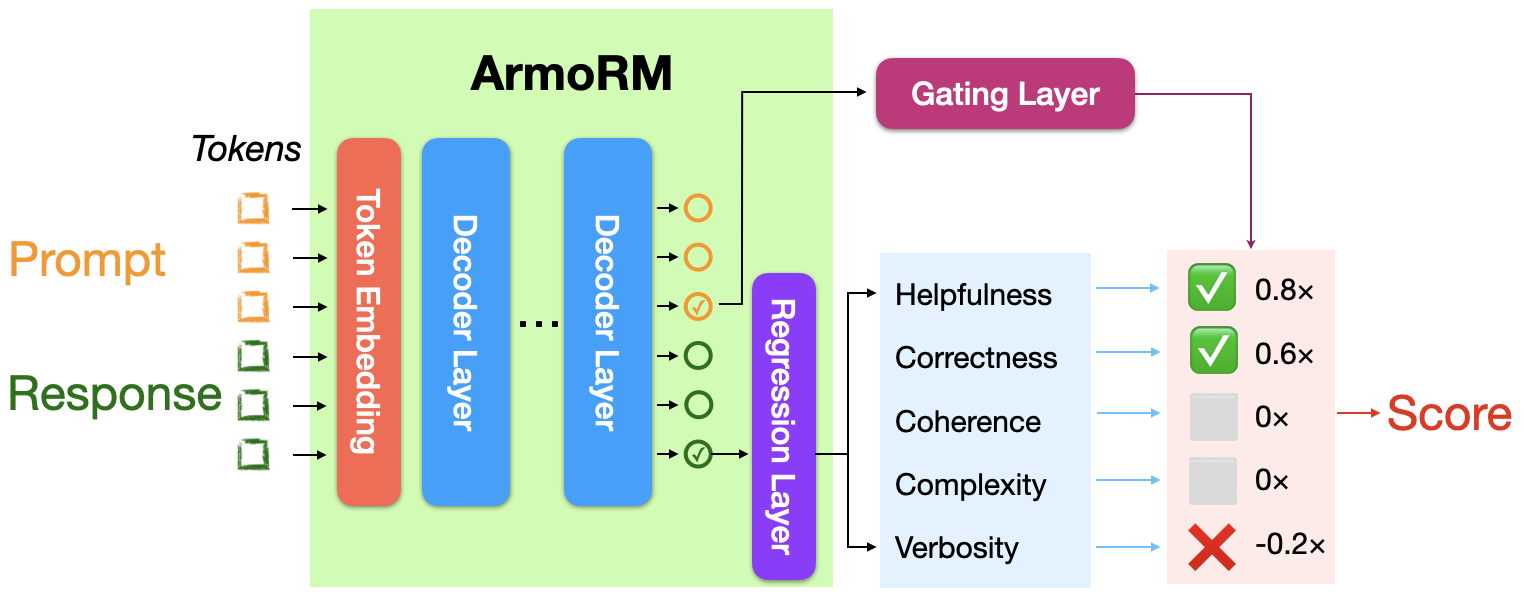
TL;DL: this is a repo for training the reward/preference model for DRL-based RLHF (PPO), Iterative SFT (Rejection sampling fine-tuning), and iterative DPO.
- 4 x A40 48G: we can train Gemma-7B-it with max_length 4096 by Deepspeed Zero-3 + gradient checkpoint;
- 4 x A100 80G: we can train Gemma-7B-it with max_length 4096 by gradient checkpoint;
- The resulting reward models achieve SOTA performance as open-source RMs in the leaderboard of RewardBench.
- Check out our blog post!
It is recommended to create separate environments for the Bradley-Terry reward model and pair-wise preference model. The installation instructions are provided in the corresponding folders.
The dataset should be preprocessed in the standard format, where each of the samples consists of two conversations 'chosen' and 'rejected' and they share the same prompt. Here is an example of the rejected sample in the comparison pair.
[
{ "content": "Please identify the top 5 rarest animals in the world.", "role": "user" },
{ "content": "Do you mean animals that are really rare, or rare relative to the size of the human population?", "role": "assistant" },
{ "content": "The ones that are really rare.", "role": "user" },
{ "content": "Alright, here’s what I found:", "role": "assistant" },
]We preprocess many open-source preference datasets into the standard format and upload them to the hugginface hub. You can find them HERE. We have also searched and found that some of the following mixture of preference dataset useful.
- hendrydong/preference_700K
- RLHFlow/UltraFeedback-preference-standard where the details can be found in the dataset card.
You can evaluate the resulting reward model with the dataset provided by benchmark by the following command.
CUDA_VISIBLE_DEVICES=1 python ./useful_code/eval_reward_bench_bt.py --reward_name_or_path ./models/gemma_2b_mixture2_last_checkpoint --record_dir ./bench_mark_eval.txt- Bradley-Terry Reward Model
- Preference model
- Multi-Objective Reward Model
- LLM-as-a-judge
Our models and codes have contributed to many academic research projects, e.g.,
- Xu Zhangchen, et al. "Magpie: Alignment Data Synthesis from Scratch by Prompting Aligned LLMs with Nothing."
- Chen, Lichang, et al. "OPTune: Efficient Online Preference Tuning."
- Xie, Tengyang, et al. "Exploratory Preference Optimization: Harnessing Implicit Q*-Approximation for Sample-Efficient RLHF." arXiv preprint arXiv:2405.21046 (2024).
- Zhong, Han, et al. "Dpo meets ppo: Reinforced token optimization for rlhf." arXiv preprint arXiv:2404.18922 (2024).
- Zheng, Chujie, et al. "Weak-to-strong extrapolation expedites alignment." arXiv preprint arXiv:2404.16792 (2024).
- Ye, Chenlu, et al. "A theoretical analysis of Nash learning from human feedback under general kl-regularized preference." arXiv preprint arXiv:2402.07314 (2024).
- Chen, Ruijun, et al. "Self-Evolution Fine-Tuning for Policy Optimization"
- Li Bolian, et al., Cascade Reward Sampling for Efficient Decoding-Time Alignment
- Zhang, Yuheng, et al. "Iterative Nash Policy Optimization: Aligning LLMs with General Preferences via No-Regret Learning"
- Lin Tzu-Han, et al., "DogeRM: Equipping Reward Models with Domain Knowledge through Model Merging",
- Yang Rui, et al., "Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs"
- Junsoo Park, et al., "OffsetBias: Leveraging Debiased Data for Tuning Evaluators"
- Meng Yu, et al., "SimPO: Simple Preference Optimization with a Reference-Free Reward"
- Song Yifan, et al., "The Good, The Bad, and The Greedy: Evaluation of LLMs Should Not Ignore Non-Determinism"
- Wenxuan Zhou et al., "WPO: Enhancing RLHF with Weighted Preference Optimization"
- Han Xia et al., "Inverse-Q*: Token Level Reinforcement Learning for Aligning Large Language Models Without Preference Data"
- Wang Haoyu et al., "Probing the Safety Response Boundary of Large Language Models via Unsafe Decoding Path Generation"
- He Yifei et al., "Semi-Supervised Reward Modeling via Iterative Self-Training"
- Tao leitian et al., "Your Weak LLM is Secretly a Strong Teacher for Alignment"
- Guijin Son et al., "LLM-as-a-Judge & Reward Model: What They Can and Cannot Do"
- Nicolai Dorka et al., "Quantile Regression for Distributional Reward Models in RLHF"
- Zhaolin Gao et al., "Rebel: Reinforcement learning via regressing relative rewards"
Thanks to all of our contributors to date (Made with contrib.rocks).
If you find the content of this repo useful in your work, please consider citing:
@article{dong2024rlhf,
title={RLHF Workflow: From Reward Modeling to Online RLHF},
author={Dong, Hanze and Xiong, Wei and Pang, Bo and Wang, Haoxiang and Zhao, Han and Zhou, Yingbo and Jiang, Nan and Sahoo, Doyen and Xiong, Caiming and Zhang, Tong},
journal={arXiv preprint arXiv:2405.07863},
year={2024}
}
@inproceedings{ArmoRM,
title={Interpretable Preferences via Multi-Objective Reward Modeling and Mixture-of-Experts},
author={Haoxiang Wang and Wei Xiong and Tengyang Xie and Han Zhao and Tong Zhang},
booktitle={The 2024 Conference on Empirical Methods in Natural Language Processing},
year={2024}
}
@article{xiong2024iterative,
title={Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint},
author={Wei Xiong and Hanze Dong and Chenlu Ye and Ziqi Wang and Han Zhong and Heng Ji and Nan Jiang and Tong Zhang},
year={2024},
journal={ICML}
}