-
Our efforts
截至中期答辩我们已经完成了yolo的训练,对于给定照片我们已经可以以较高的准确率裁剪出ROI
中期之后我们又做了
-
计算并得到ROI区域
-
用Yolo获得谷点,python可以利用ctypes库方便地调用darknet,利用前人封装好的库,我们只需要几行代码就调用darknet
import python.darknet as dn dn.set_gpu(0) net = dn.load_net(str.encode("cfg/tiny-yolo.cfg"), str.encode("weights/tiny-yolo.weights"), 0) meta = dn.load_meta(str.encode("cfg/coco.data")) r = dn.detect(net, meta, str.encode("data/dog.jpg")) print(r)
调用结果:
结果
r是一个数组,其中每一个tuple是一个可能的object,tuple的第一项是object的名字,第二项是置信度,第三项是代表object位置的一个tuple检测的结果中可能会有很多的误检和漏检,我们的trick是,降低阈值(我们选择0.1),使所有指缝尽可能的都能被检测出来,然后再用以下原则排除误检:
1. 当两个检出点比较接近时,只保留置信度较大的一个 2. 当检出多个大指缝时,只保留置信度最大的一个 3. 经过以上两条筛选后,若最终的结果不是一个大指缝,三个小指缝,则判定此图识别失败使用以上小trick大多数的手掌照片都可以成功找到所有谷点,效果远远好于只是简单的设置一个threshold
-
找到与大指缝p0最接近的小指缝p1和最远的小指缝p2,并以此建立坐标系,并使用
向量p0p1和向量p1p2的夹角关系判断是左手还是右手,以及手掌的朝向,从而计算出ROI区域的两个端点p_origin和p_top -
将ROI区域裁剪成一个160*160*3的图片
我们知道将ROI区域映射到一个160*160的图片是一个相似变换,有四个自由度
通过两个点(p_origin和p_top)就可以求解以上变换矩阵
t1 = p_origin[0] t2 = p_origin[1] theta = acos(np.dot((1, 1), p_top - p_origin) / np.linalg.norm((1, 1)) / np.linalg.norm(p_top - p_origin)) v = p_top - p_origin if v[1] < v[0]: theta = - theta s = (p_top[0] - p_origin[0]) / (cos(theta) * 160 - sin(theta) * 160) trans_matrix = np.array([[s * cos(theta), -s * sin(theta), t1], [s * sin(theta), s * cos(theta), t2], [0, 0, 1]])
-
最后通过插值的方法得到最终结果
裁剪前:
裁剪后:
-
-
使用已有的ROI直接训练FaceNet模型,效果很差,同一类的间的差距有时会很大,不同类之间的差距有时又很小
我们分析的原因:现有的ROI数据集的裁剪方式可能与我们的裁剪方式有出入,所以使用现有数据集训练出来的模型直接用于我们自己的ROI的verification上,可能效果并不理想
-
用自己训练出来的Yolo模型,自己裁剪手掌图片,以保证训练集和实测集同分布。效果没有明显变化,任然忽大忽小
两次训练的损失变化曲线如上图,我们发现两次训练,损失都非常快得降到接近0
-
再次改进,我们考虑到之所以FaceNet返回的特征之间的距离忽大忽小很不稳定,通过观察我们的训练集,我们发现训练集中的掌纹虽然忽明忽暗,但是同一个人的掌纹一般色调是一致的,不同的人拍摄的掌纹才会有较大的明暗差别,所以有可能是因为同一个人的手掌在不同光照条件下提取到的特征会有较大出入。
# 通常的标准化,将灰度值映射[-1, 1]之间 image = (tf.cast(image, tf.float32) - 127.5) / 128.0 # 我们考虑到光照变化后,做一个去中心化的操作 image = (tf.cast(image, tf.float32) - tf.reduce_mean(tf.cast(image, tf.float32))) / 128.0
我们也有考虑试着做一个直方图均衡化,但是直方图均衡化并非均匀的改变图片的灰度值,也许会破坏图像的特征,同时也受时间限制,我们没有做这方面的尝试
通过去中心化,效果得到了比较明显的改善,特征之间的欧氏距离比较稳定,不会出现忽大忽小,类内距离比较小,类间距离比较大
-
-
Our results
我们成品是一个网页版的掌纹支付系统,因为时间关系我们只做了注册和登录功能,这两个功能足以体现我们的verfication效果
考虑到FaceNet是基于python的,python也可以非常方便地调用darknet,我们的后端选择使用flask框架。
业务流程:(璐璐画一下流程图)
注册:用户ID、密码、拍摄或上传手掌照片=>将数据发送给后端=>后端用Yolo检测谷点并尝试提取ROI并保存下来=>后端返回相应注册结果,如果ROI提取失败则返回第一步,成功则可以尝试登录
登录:用户输入ID,拍摄或上传手掌照片=>将数据发送给后端=>后端使用Yolo检测谷点,并提取ROI,将ROI临时保存,如果检测失败则返回第一步=>后端找到该用户保存的ROI,将保存的ROI和这次提取所得的ROI输入到FaceNet,获得他们的特征向量=>计算两个特征向量的距离,若小于给定阈值则判定为同一个人,登录成功,否则登录失败,返回第一步
Yolo和FaceNet模型都是提前加载好的,后端接收到前端的数据不需要加载模型,只需要计算就好了,不过因为没有GPU,计算过程还是要好几秒的时间
-
Look in to the future.
我们有待改进的地方:
-
前端界面太简陋,业务逻辑也过于简单
-
ROI匹配的效果还有待改进
-
数据量太少,对于FaceNet要求的数据量比较大
我们只用了5800+张图,600个类,而官方训练的最好的模型是约3.3M张图,约9000类
-
可能是掌纹的特征还是比较难提取,我们做的是粗粒度的掌纹识别,也许可以对提取出来的ROI做一个滤波,使用一些边缘检测算子提取边缘(也就是生命线、智慧线、感情线什么的。。),并加深这些边缘以使得提取更加简单
-
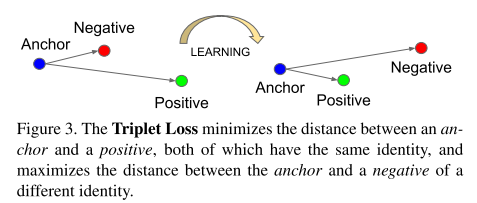
FaceNet使用的是三联子(triplets)loss,简单的说三联子损失的目的就是将图片映射打一个新的欧式空间中,并使得在该向量空间内,最小化类内差距最小化,最大化类间差距。
但是我们的训练集中,同一类明暗程度基本一致,不同类的明暗程度会有较大差别,这样的训练集可能使得损失函数轻易的变得很小,达不到提取特征的效果。
我们的训练集:
-
-