Github:https://github.com/RWLinno/RMRB/
Author: @rwlinno
输入时间的起始终止范围,或指定年份 / 日期列表 ,找寻日报中带有图片的报道,存成网页、图片、文稿以及汇总表的格式。
-
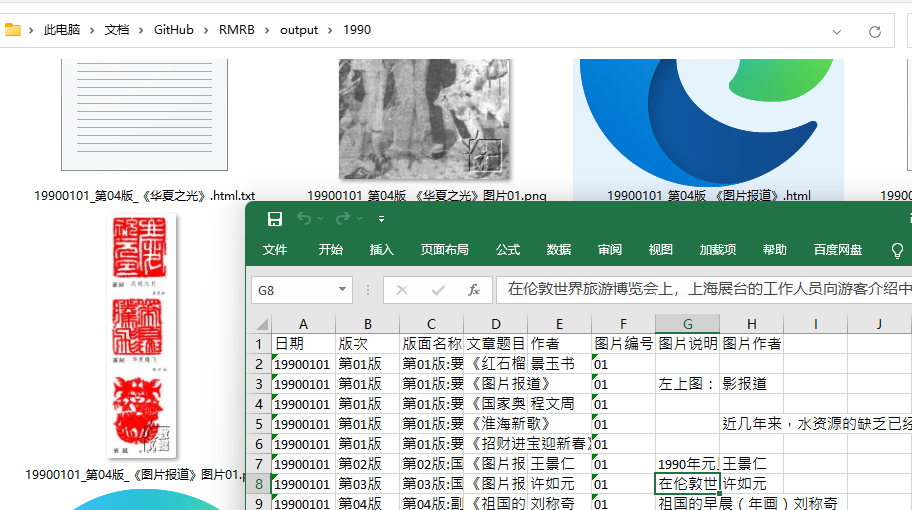
保存网页
- 网页命名格式:
日期_版次_文章题目_文章作者姓名_ - 例:
20091218_第01版_《温家宝会见巴西总统卢拉》_庞兴雷&韦冬泽
- 网页命名格式:
-
保存图片
- 图片命名格式:
日期_版次_文章题目_文章作者姓名_图片+No. - 例:
20091218_第01版_《温家宝会见巴西总统卢拉》_庞兴雷&韦冬泽_图片01
- 图片命名格式:
-
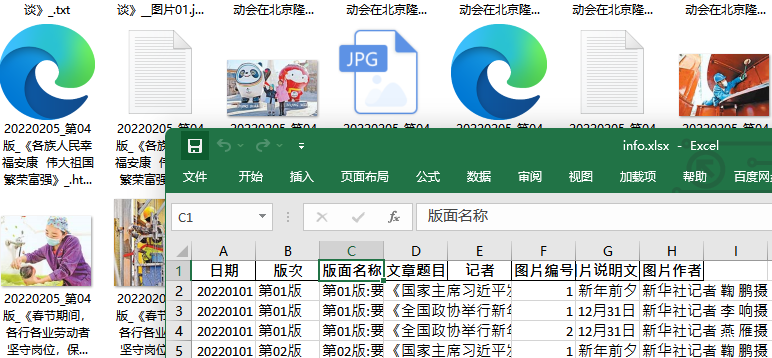
保存Excel
*日期 版次 版面名称 文章题目 文章作者姓名 图片编号. 图片说明文字 图片作者*
日期:20030512
版次:01 02 03 …….
版面名称:(如有)01:要闻
文章题目:《xxxxxxxx》
文章作者姓名: 张三 张三&李四
图片编号:图片在文章内的编号 01 02 03
图片说明文字:(如能捕捉到)文字格式
图片作者:(如能捕捉到) 张三 张三&李四
RMRB/
│───README.md
└───output/
│ │───年份/
│ │ │ 文稿.txt
│ │ │ 网页.html
│ │ │ 图片1.jpg
│ │ │ 图片2.jpg
│ │ ...
│ ...
│ new_people.py
│ old_people.py
│ utils.py
│ requirements.txt
│ ...
支持爬取新人民日报网(例如:http://paper.people.com.cn/rmrb/html/2023-12/15/nbs.D110000renmrb_01.htm)的数据,成功率高。
支持爬1946-2023年的人民日报,会面临验证,拒绝访问,封IP等一系列问题,需要谨慎运行。
使用新增的ddddocr库解决通用认证问题,重构了new_people.py中的代码。
对以前格式杂乱的新闻报道进行了许多分类处理。
用来存放爬虫常用或其他实用方法。
下面直接在命令行里创建虚拟环境->激活->安装依赖包->运行程序
conda create -n RMRB python=3.8
conda activate RMRB
pip install -r requirements.txt
python new_people.py #打开程序先调整好日期

修改下图所示参数,直接在IDE里运行爬虫程序即可。
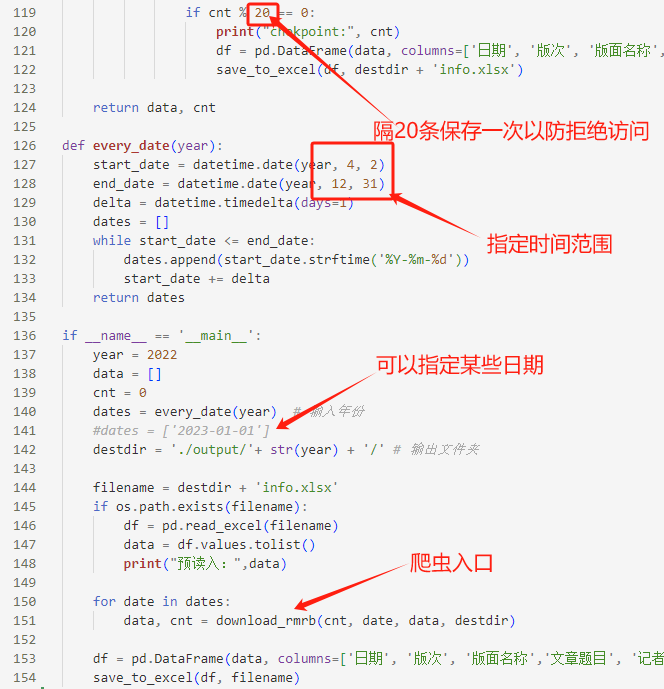
建议按月份分批次爬取数据。
通用支持指定日期、时间范围以及整一年的爬取方式。也是直接运行程序就可以了。
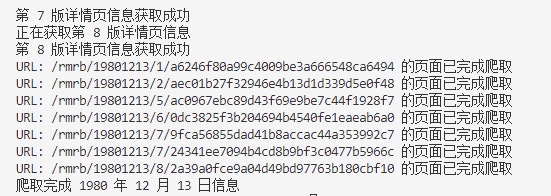
IP被封会有语句提示,通常是一次性爬取太多导致的,可以稍微修改sleep.time()以及,不需要太过担心。

在页面点开F12,查看网络一栏,找到页面的cookie的请求头,并替换掉代码中的Cookie。

