캡스톤 디자인 프로젝트, 위험소리 감지 기계학습 모델
창원대학교 이수균 신동명 권용진
일상생활속에서 발생할 수 있는 수많은 위험상황에 대해 인체의 감각은 발달해왔다.
뜨거운 것을 만지면 고통을 느끼고 그것이 위험하다는 것을 학습하거나, 누군가 교통사고를 통해 다치거나 사망하는 사건을 보고 들으면서, 달려오는 차 소리를 듣고 시선을 돌려 위험을 감지하는 것은 비장애인에게는 당연한 일이다.
그러한만큼, 선척적 또는 후천적 요인으로 인해 주요 감각을 소실한 장애인은 위험 상황을 인지하지 못하고 사고를 피하지 못하는 경우가 많다.
통계청이 발표한 '장애인삶패널조사'에 따르면, 장애인이 겪는 사고경험의 45.8% 가 교통사고로, 운전자의 실수에 감각적인 대처가 필요한 상황에 감각 또는 판단력의 소실이 큰 영향을 미친다는 사실을 유추할 수 있다.
교통사고 뿐 아니라, 다양한 상황에서 눈으로 보지 못하지만 소리를 듣고 몸을 피하는 경우가 많다. 그리고, 비장애인은 본능적으로 더 긴급한 소리에 대해 더 빠른 대처를 할 수 있다. 예를 들어, 멀리서 다가오는 자전거 소리보다 바로 뒤에서 들린 비명소리에 더 빠르게 반응한다.
위의 문제인식에 대하여, 주변소리의 구분과 위험을 알리는 소리에 대한 피드백을 다른 감각에 의존할 수 밖에 없는 청각장애인에게 얼마나 위험한 소리인지,
어디서 들리는 소리인지를 모니터링 할 수 있게 한다면, 신속한 대처와 사고방지에 도움을 줄 수 있을 것이라 기대한다.
-
인간은 최대 20kHz 에 달하는 소리를 구분해 낼 수 있으며, 컴퓨터에서는 Nyquist의 샘플링 정리에 따라 두 배이상의 44100Hz로 샘플링된 PCM 데이터를 사용한다.
-
일반적인 소리는 신호로서, 스펙트럼 분석을 통해 어떤소리가 존재하는지 분석할 수 있다. 분할정복 고속 푸리에변환(Fast-FT)알고리즘은 인간의 인지특성에 맞게, 근사(近似) 이산 푸리에변환(Discrete-FT)을 사용하여 보다 빠르게 실시간 스펙트럼을 얻을 수 있다.
-
인간의 청각인지는 저주파보다 고주파에 더 민감하다. 낮게 울리는 북소리보다, 높은 비명소리나 칠판 긁는소리에 청각이 훨씬 예민하게 반응한다.




- 멜 단위는 높은 주파수에 대한 인지특성을 반영한다. 스펙트럼 계산시, 멜 스케일링을 적용시키는것은 보다 인간의 인지특성에 가깝게 데이터를 조정하는 것이 된다.


- 가설 : 인간은 특정 주파수 성분의 소리에 위험신호라고 반응할 것이다.
모든 학습에서, 1초간의 음성 PCM 만을 사용하는 것은 44100Hz 샘플 주파수를 가진 wav파일의 44100개의 특성을 사용. 따라서, 데이터 특성에 맞는 적절한 전처리가 필요함.
- MFCC : 주파수 영역으로 푸리에 변환된 데이터의 전력에서 특정 주파수의 고조파 성분을 사람의 인지특성을 반영한 Mel-Scale Filter 로 Cepstral 분석
def mfcc(signal, samplerate=44100):
nfft = calculate_nfft(samplerate, 0.025)
print('nfft', nfft)
# 0.025 (winlen: 분석 길이 0.025), 0.01 (winstep), nfilter (26)
feat, energy = fbank(signal, samplerate, 0.025, 0.01, 26, nfft, 0, None, 0.97, lambda x: np.ones((x,)))
feat = np.log(feat)
# 로그가 취해진 Filter Bank 에너지에 DCT를 계산한다. 이유는 두가지 Filter Bank는 모두 Overlapping 되어 있기 때문에 Filter Bank
# 에너지들 사이에 상관관계가 존재하기 때문이다. DCT는 에너지들 사이에 이러한 상관관계를 분리 해주는 역할을 하며, 따라서 Diagonal Covariance Matrice
# 를 사용할 수 있게 된다.(HMM Classifier와 유사함)
feat = dct(feat, type=2, axis=1, norm='ortho')[:, :13]
feat = lifter(feat)
feat[:, 0] = np.log(energy)
return feat- PCA : 1초 wav(44100Hz)의 0.025배 Windowed된 MFCC는 (99, 13) 총, 1287 차원을 가지게 된다. 해당 차원을 모두 사용하는 것은 "차원의 저주"로 인한 모델의 불필요한 복잡성을 증가시키게 된다. 데이터에 대한 선형대수적 접근에서 유도되는 PCA 분석을 통해 재구성 오차 10%의 차원압축을 진행하면 약 100개의 차원으로 수렴한다. (다음 사진은 왼쪽:데이터 오른쪽:PCA의 inv-PCA)

-
Imbalanced 해소 : 데이터의 레이블 비율이 1:1이 아님. 이는 프로젝트 기간이 짧고, 데이터 수집에 한계가 있었던 만큼 아쉬운 부분이지만, 충분히 존재할 수 있는 경우의 수. 이를 해결하기 위한 다양한 방법이 있음.
-
Class Weight : Classifier 의 오차 패널티를 각각의 레이블마다 다르게 적용한다. SVC에서 오차 패널티는 C이며, 이에 열세한 레이블에 큰 가중치를, 우세한 레이블에 작은 가중치를 부여한다.
-
Under-Over Sampling : 언더 샘플링은 열세한 데이터의 수 만큼, 우세한 레이블에 해당하는 데이터를 Drop, 오버 샘플링은 우세한 데이터의 수만큼 열세한 레이블의 데이터를 Replacement.
-
"""
두 클래스간 데이터 수가 일치하지 않음, 확률에 의존하는 영향을 배제하기 위해,
1) 클래스 별 패널티 계수 차별화 휴리스틱 적용
(The “balanced” heuristic is inspired by Logistic Regression in Rare Events Data, King, Zen, 2001.)
2) 언더샘플링 - 우세한 클래스의 데이터를 무작위로 제거
3) 오버샘플링 - 열등한 클래스의 데이터를 중복
"""
parameter_cases = [
# 1)
dict(
class_weight=dict(np.ndenumerate(
compute_class_weight(class_weight='balanced', classes=[0, 1], y=y_origin))),
sampling=None
),
# 2)
dict(
class_weight=None,
sampling='under'
),
# 3)
dict(
class_weight=None,
sampling='over'
)
]
MFCC 및 PCA 된 데이터의 모든 특성을 가지고 위험 또는 안전 소리로 이진 분류기를 설계함.
사용한 데이터는 urban_sound의 1287차원의 MFCC이다. 내부적으로 PCA를 적용하고 있으며, PCA로 인한
재구성 오차는 10%이다.
predictor = ReduceImbalancedPredictor(n_components=0.9, sampling=clf_params['sampling'], random_state=999)C와 gamma에 대하여 그리드 서치를 진행했으며, 범위는 아래와 같다.
# 아래 범위에 대한 그리드 서치를 진행
C_range = np.logspace(-2, 10, 13)
gamma_range = np.logspace(-9, 3, 13)
param_grid = dict(gamma=gamma_range, C=C_range)K-Fold 교차검증을 통해 Validation Accuracy를 계산하며, K는 5이다.
# 모든 그리드 서치의 밸리데이션은 K-Fold 로 진행
cv = KFold(5, shuffle=True, random_state=777)Class Weight 방식, Under-Sampling 방식, Over-Sampling 방식의 경우에 대해 반복을 진행했으며, 이에 그리드서치 결과와 최고점수 파라미터 모델의 러닝커브를 출력하였다.
Class Weight:0.918976


Under Sampling:0.866984


Over Sampling:0.969781


Random Prediction



나이브 베이즈는 특정 자료가 여러 가지 속성을 가지고 있을 때 그 속성들 사이의 독립을 가정하는 베이즈 정리를 기반으로 한다.
-
1740년대 토마스 베이즈(Thomas Bayes)가 정립한 조건부 확률에 대한 수학적 정리
- 베이즈 정리는 베이즈 룰(Bayes Rule), 베이즈 법칙(Bayes Law)으로도 불림
-
두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리
- 사전 확률의 정보를 이용해 사후 확률을 추정
-
사전 확률(Prior probabilty): 가지고 있는 정보를 기초로 정한 초기 확률
-
사후 확률(Posterior probabilty): 결과가 발생했다는 조건에서 어떤 원인이 발생했을 확률
-
우도(Likelihood): 원인이 발생했다는 조건에서 결과가 발생했을 확률
-
베이즈 정리의 공식
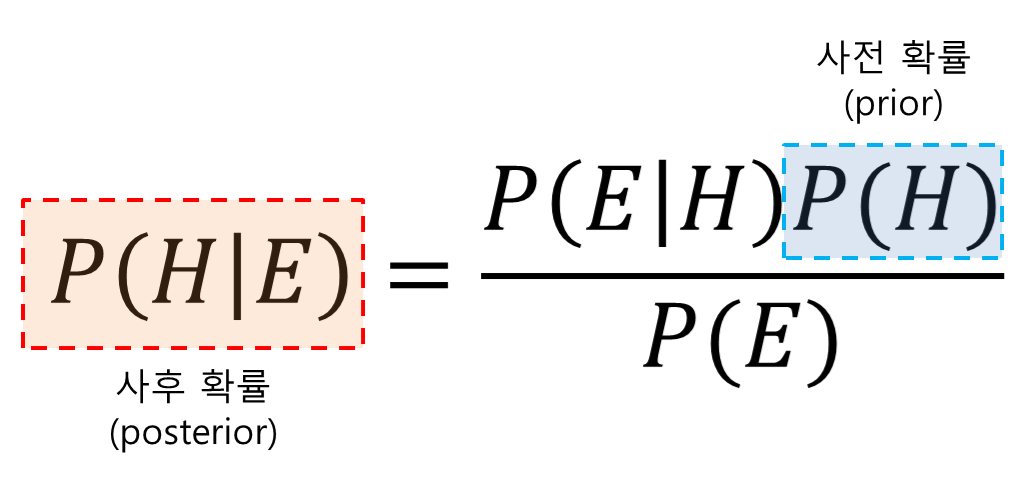
H를 사건의 원인, E를 결과로 가정했을 경우에 P(H)는 원인이 발생할 확률인 원인의 사전확률을 의미하고, P(E)는 결과가 발생할 확률인 결과의 사전확률을 의미한다. P(E|H)는 원인이 발생했다는 조건에서 결과가 발생할 확률로 우도를 의미합니다. 반대로 P(H|E)는 결과가 발생했다는 조건에서 원인이 발생했을 확률로서 이것이 사후 확률이다.
MFCC 및 PCA 된 데이터의 모든 특성을 가지고 위험 또는 안전 소리로 이진 분류기를 설계함.
사용한 데이터는 urban_sound의 1287차원의 MFCC이다. 내부적으로 PCA를 적용하고 있으며, PCA로 인한
재구성 오차는 10%이다.
PCA_N_COMPONENTS_RATE = 0.9
...
pca = PCA(n_components=PCA_N_COMPONENTS_RATE)
X = pca.fit_transform(X)Var_smoothing에 대하여 Validation Curve를 진행했으며, 범위는 아래와 같다.
# 아래 범위에 대한 Validation Curve를 진행
Var_smoothing = np.logspace(-9, 3, 13)K-Fold 교차검증을 통해 Validation Accuracy를 계산하며, K는 10이다.
# 모든 Validation Curve의 밸리데이션은 K-Fold 로 진행
skf = StratifiedKFold(n_splits=10)Default ,Under-Sampling 방식, Over-Sampling 방식의 경우에 대해 반복을 진행했으며, 이에 최고점수 파라미터 모델의 러닝커브를 출력하였다.
Default

Under Sampling

Over Sampling

pyaudio의 마이크 스트림을 사용하여, 0.5초마다 지난 0.5와 합하여 1초의 데이터를 만들어 사용.
def generator(self, out_size):
prev_chuck = np.empty(self._chunk, dtype=np.int16)
while not self.closed:
current_chunk = self._buff.get()
if current_chunk is None:
continue
current_chunk = np.frombuffer(current_chunk, dtype=np.int16)
appended = np.append(prev_chuck, current_chunk)
if len(appended) >= out_size:
yield appended[:out_size]
prev_chuck = appended[self._chunk:]
else:
prev_chuck = appended
...
with MicStream(44100, 22050) as stream:
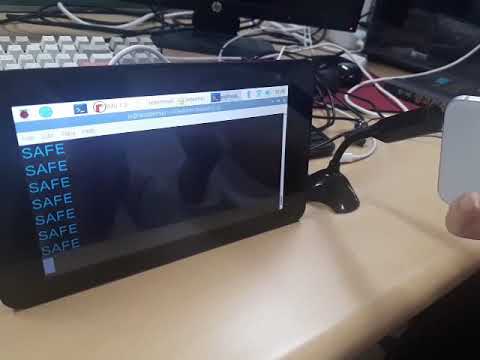
audio_generator = stream.generator(out_size=44100)최고점수 모델인 SVC, 오버샘플링과 C:10, gamma:0.001, score:0.97을 load하여 사용.
예측을 통해, DANGER 또는 SAFE 를 출력함.
predictor: ReduceImbalancedPredictor = load('weighted@none-C@10.000000-gamma@0.001000-score@0.969781.joblib')
with MicStream(44100, 22050) as stream:
audio_generator = stream.generator(out_size=44100)
for x in audio_generator:
data = np.ravel(mfcc(x, 44100)).reshape(1, 1287)
data = predictor.data_transform(data)
pred = predictor.predict(data)
if pred[0] == 1:
print('SAFE')
else:
print('DANGER', file=sys.stderr)