使用whisper通过python程序实现文件夹下(及子文件夹)所有音频文件转换为.lrc字幕文件,若已存在lrc字幕文件,则自动跳过
它可以使用openai发布的whisper语音转文字模型,由用户制定需要处理的音频文件夹,程序将自动递归搜索所有文件夹音频文件,并且将其转录为lrc格式的字幕文件。
适合有大量音频文件需要转录为字幕的用户。
后续将加入自动翻译。
首先安装python,已经在python3.10.11上测试
然后根据whisper的要求安装python依赖库openai/whisper:
pip install git+https://github.com/openai/whisper.git 拉取该repo,并且安装Python依赖项:
git clone https://github.com/bai0012/Whisper_auto2lrc
cd Whisper_auto2lrcpip install -r requirements.txt 使终端处于项目文件夹的基础上,运行
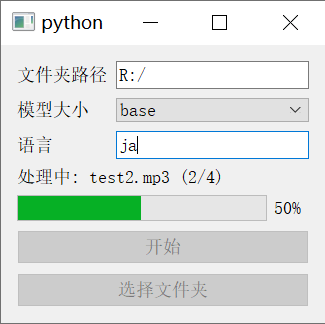
python main.py在窗口中选择文件夹路径,选择要使用的模型大小,输入要处理的音频文件语言,点击开始即可
Whisper可以调用支持CUDA的GPU,如果你确认GPU已经正确安装并且支持CUDA,请尝试以下步骤:
pip uninstall torchpip cache purge然后在PyTorch官网使用命令安装最新的PyTorch
如:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118应该就可以正常调用显卡了
可以尝试以下步骤重新安装ffmpeg:
pip uninstall ffmpegpip uninstall ffmpeg-pythonpip install ffmpeg-python| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en |
tiny |
~1 GB | ~32x |
| base | 74 M | base.en |
base |
~1 GB | ~16x |
| small | 244 M | small.en |
small |
~2 GB | ~6x |
| medium | 769 M | medium.en |
medium |
~5 GB | ~2x |
| large | 1550 M | N/A | large |
~10 GB | 1x |
请根据你所拥有GPU的显存大小选择模型,一般来说,越大的模型速度越快,错误率越低。
(例如,你拥有RTX3060 12G,那你就可以选择large模型,而你拥有的是GTX 1050ti 4G,那你就只能使用small模型了)
whsiper支持多种语言的语音转文字,常用的有:
| 语言 | 代码 |
|---|---|
| 汉语 | zh |
| 英语 | en |
| 俄语 | ru |
| 日语 | ja |
| 韩语 | ko |
| 德语 | de |
| 意大利语 | it |
更多语言,请参考:whisper/tokenizer.py
(本程序在GPT 4指导下完成)