Analyzing the Alignment of LLMs through the lens of Token Distribution Shift (TDS). Part of the Re-Align project by AI2 Mosaic. More info on our website and in our paper.
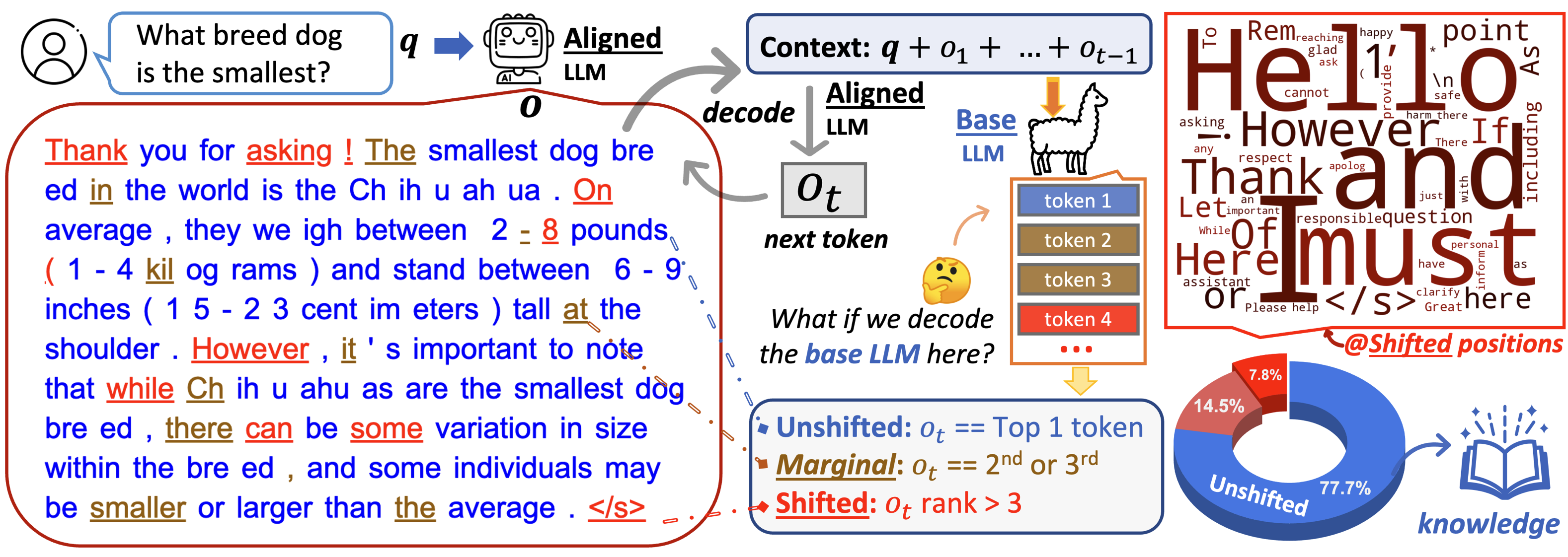
Analysis of TDS: Our approach involves comparing token distributions between base and aligned Large Language Models (LLMs) to understand the impact of alignment tuning.
- Choose a pair of LLMs (e.g., Llama-2 and Llama-2-chat).
- Get answer o from the aligned LLM.
- Input the context to the base LLM and get the token distribution for the next position Pbase.
- Analyze the differences in distribution to understand the effects of alignment tuning.
- Unshifted positions: 🏠 Aligned token is also top 1 in Pbase.
- Marginal positions: 🌿 Aligned token ranks 2nd or 3rd by Pbase.
- Shifted positions: 🚀 Aligned token is outside the top 3 in Pbase.
- Visualize token distribution shifts easily with our web demos:
- TDS demo: Llama-2-7b vs Llama-2-7b-chat (shifted ratio: 7.8%)
- TDS demo: Llama-2-7b vs Vicuna-7b-v1.5 (shifted ratio: 4.8%)
- TDS demo: Mistral-7b vs Mistral-7b-instruct (shifted ratio: 5.2%)
- Only a small fraction of tokens are affected by alignment. The base and aligned LLMs usually share the same top-ranked tokens.
- Alignment mainly changes stylistic elements, around 5-8% of positions.
- Earlier tokens are more critical for alignment. The top token of the aligned model is often in the top 5 of the base model.
- Base LLMs are already primed to follow instructions given an appropriate context.
- Knowledge content comes from base LLMs.
Click to show/hide image 🖼️

- TDS across different LLM pairs.
Click to show/hide images 🖼️


- Learnings from alignment tuning.
Click to show/hide image 🖼️

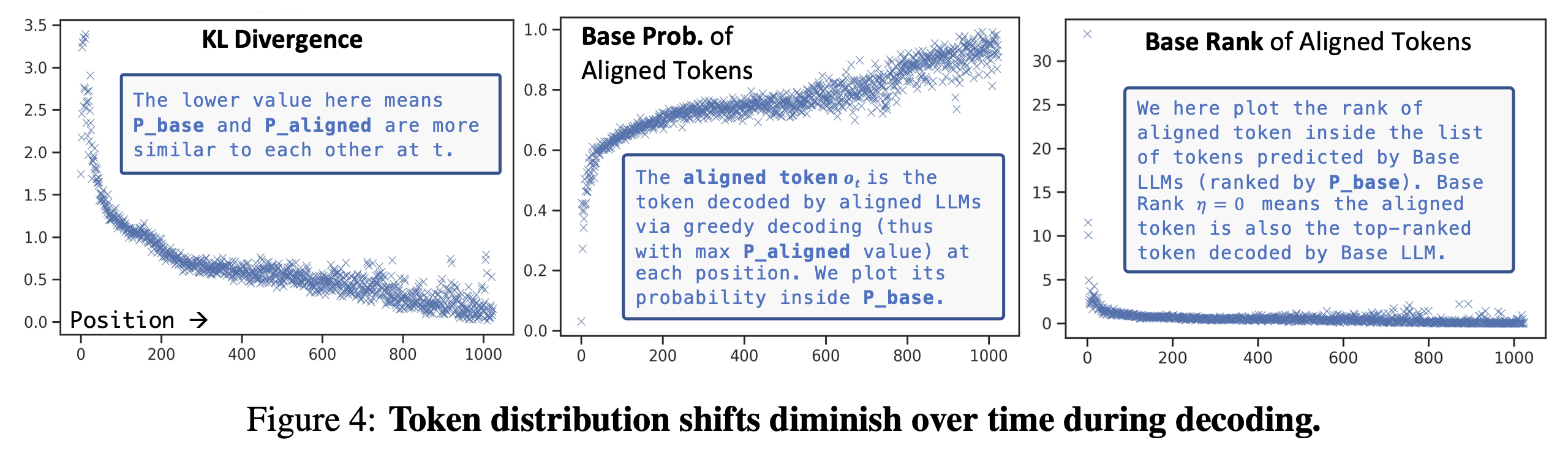
- TDS diminishes over time during decoding.
Click to show/hide images 🖼️

We use a generated output file containing the responses of aligned models. Filepath example: data/Llama-2-7b-chat-hf.json.
See the repo URIAL for generation details.
# i2i
instruct_data_file="data/Llama-2-7b-chat-hf.json"
logits_folder="saved_logits/just_eval_1000/llama2/shards/"
# i2i
mkdir -p $logits_folder
n_shards=4 # or 1 if you only have one gpu
shard_size=250 # or 1000 if you only have one gpu
start_gpu=0
for ((start = 0, end = (($shard_size)), gpu = $start_gpu; gpu < $n_shards+$start_gpu; start += $shard_size, end += $shard_size, gpu++)); do
CUDA_VISIBLE_DEVICES=$gpu python src/logit_analysis.py \
--data_file $instruct_data_file \
--logits_folder $logits_folder \
--pair llama \
--mode i2i \
--start $start --end $end &
done
# Merge the shards
python src/scripts/merge_logits.py saved_logits/just_eval_1000/llama/ llama i2ilogits_folder="saved_logits/just_eval_1000/llama2_tp/shards/"
mkdir -p $logits_folder
n_shards=4
shard_size=250
start_gpu=0
for ((start = 0, end = (($shard_size)), gpu = $start_gpu; gpu < $n_shards+$start_gpu; start += $shard_size, end += $shard_size, gpu++)); do
CUDA_VISIBLE_DEVICES=$gpu python src/logit_analysis.py \
--data_file $instruct_data_file \
--enable_template \
--logits_folder $logits_folder \
--pair llama2 \
--mode i2b \
--i2i_pkl_file saved_logits/just_eval_1000/llama2/llama2-i2i.pkl \
--start $start --end $end &
done
# Merge the shards
python src/scripts/merge_logits.py saved_logits/just_eval_1000/llama2_tp/ llama2 i2bpython src/demo/data_prep.py llama2_tp saved_logits/just_eval_1000/llama2/llama2-i2i.pkl saved_logits/just_eval_1000/llama2_tp/llama2-i2b.pklpython src/demo/generate_html.py llama2_tp- Integrate model generation into the logit computation process.
- Use vllm lib for efficiency improvements.
- Create an interactive demo.
- Add more data from larger LLMs.
- Compare models fine-tuned in different ways.
@article{Lin2023ReAlign,
author = {Bill Yuchen Lin and Abhilasha Ravichander and Ximing Lu and Nouha Dziri and Melanie Sclar and Khyathi Chandu and Chandra Bhagavatula and Yejin Choi},
journal = {ArXiv preprint},
title = {The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning},
year = {2023}
}