-
- requirements.txt에 cmake==3.26.1 와 pydub를 추가하였습니다.
- 배치파일에서 ffmpeg를 설치하는 코드를 추가하였습니다.
- 기존 처리 방식인 '음성 파일 -> faster-whisper' 에서 '음성 파일 -> 음성 파일 손상 여부 검사 -> 음성 파일 길이 검사 -> 음성 파일 리샘플링 -> faster-whisper' 순서로 변경하였습니다.
- 기존 모든 음성의 대본을 작성하는 방식에서 1초에서 10초 사이의 음성 파일만 대본을 작성하도록 변경하였습니다.
- 음성 파일에 대한 예외 처리를 추가하였습니다.
- 기존의 filelists/SP와 filelists/MP 폴더에 넣어 처리하는 방식에서 audio/SP와 audio/MP 폴더에 넣어 처리하는 방식으로 변경했습니다.
- audio/SP 폴더에 파일을 넣은 경우 음성 파일을 검사한 후 리샘플링하여 filelists/SP 폴더에 저장한 뒤 대본을 작성합니다.
-
- 4초 이상의 음성 파일의 경우 대본이 정상적으로 작성되지 않는 문제를 해결했습니다.
- 음성 파일의 길이가 짧아 대본이 정상적으로 작성되지 않는 문제를 해결했습니다.
git clone https://github.com/Roista57/vits-webui.git
- setup.bat 파일을 실행할 때 pyopenjtalk==0.2.0 부분에서 오류가 발생한 다면 아래의 프로그램을 확인해주세요.
- visual studio build tools 2019: https://visualstudio.microsoft.com/ko/vs/older-downloads/
- 단일 화자의 음성을 준비한 경우 SP폴더에 다음과 같이 넣습니다.
-
audio/SP ├─audio1.wav ├─audio2.wav ├─audio3.wav ├─audio4.wav └─...
-
- 다중 화자의 음성을 준비한 경우에는 MP폴더에 다음과 같이 넣습니다.
-
audio/MP ├─speaker_1 │ ├─audio1.wav │ ├─audio2.wav │ └─... └─speaker_2 ├─audio1.wav ├─audio2.wav └─...
-
- 단일 화자인 경우 Single, 다중 화자인 경우 Multi를 선택한 뒤 음성 파일의 언어를 선택한 후 대사 추출 버튼을 실행합니다.
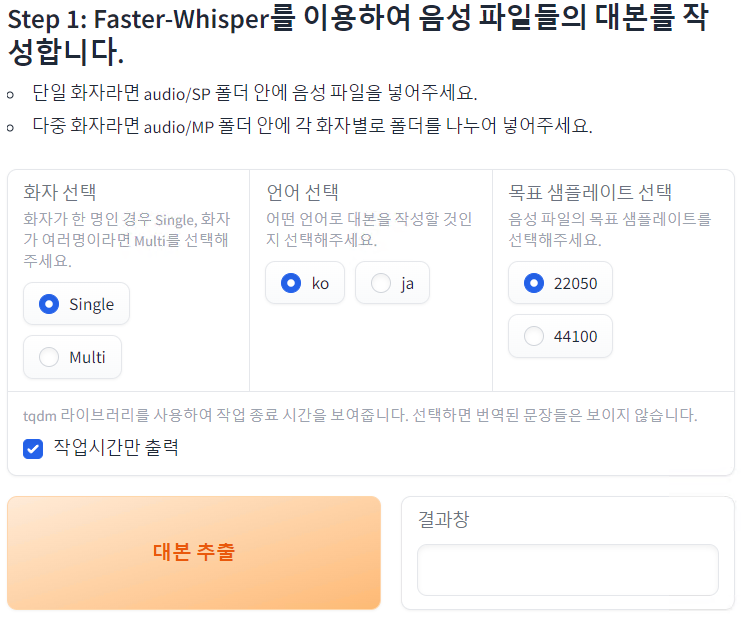

- 화자, 언어를 Step 1에서 했던 값과 동일하게 설정한 뒤 Preprocess 실행 버튼을 실행합니다.
- 대사 추출 기능을 사용하지 않고 자신이 가지고 있는 대본 파일을 사용하는 경우 filelists.txt 경로에 자신의 대본 텍스트 파일의 경로를 입력한 뒤 화자, 언어를 선택한 뒤 Preprocess 실행 버튼을 실행합니다.
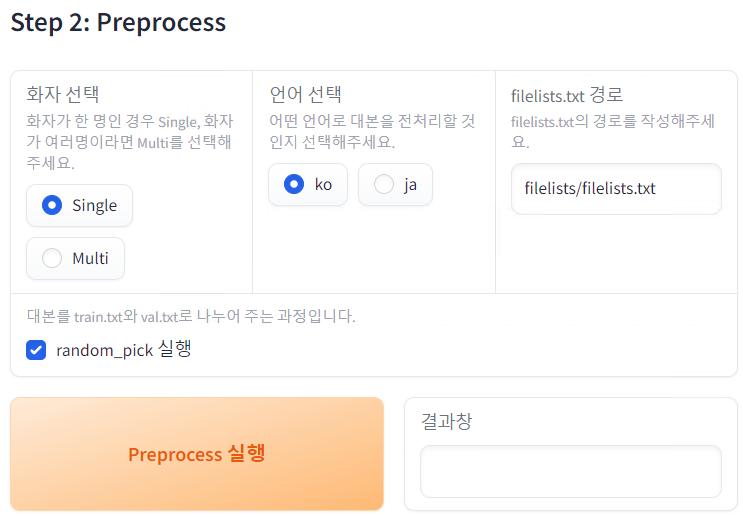
- 대사 추출 기능을 사용하지 않고 자신이 가지고 있는 대본 파일을 사용하는 경우 filelists.txt 경로에 자신의 대본 텍스트 파일의 경로를 입력한 뒤 화자, 언어를 선택한 뒤 Preprocess 실행 버튼을 실행합니다.

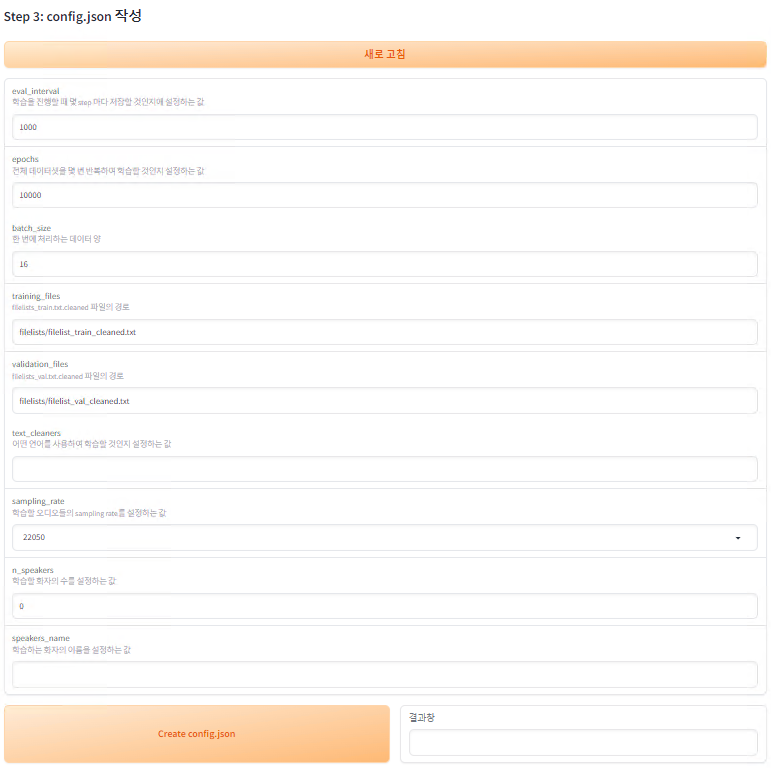
- 위의 Step 1과 Step 2 과정을 진행했다면 새로 고침 버튼을 눌러준 뒤 sampling_rate 와 n_speakers, speaker_name을 작성한 뒤 Create config.json 버튼을 실행해주세요.

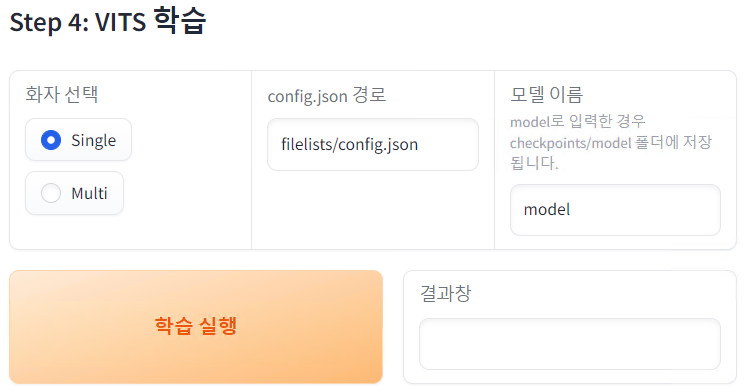
- 화자를 선택, 모델 이름을 작성한 뒤 학습 실행 버튼을 실행합니다.
- 새 명령 프롬프트에서 학습이 실행됩니다.
- VITS 학습을 종료하려면 Ctrl + C를 누르거나 명령 프롬프트를 종료하세요.

- 모델 경로에 chekcpoints/모델 이름 형태로 작성한 뒤에 Tensorboard 실행 버튼을 눌러주세요.
- Tensorboard는 새 명령 프롬프트에서 실행됩니다.
- Tensorboard를 종료하려면 Ctrl + C를 누르거나 명령 프롬프트를 종료하세요.

- config.json 경로와 모델 경로에 추론하고자 하는 json, pth의 경로를 입력합니다.
- 추론 Webui 실행을 누르면 server.py를 실행합니다.
- Tensorboard를 종료하려면 Ctrl + C를 누르거나 명령 프롬프트를 종료하세요.


- faster-whisper를 이용하여 대본을 작성하는 기능
- 언어를 바꿔 학습할 때마다 symbols.py를 자동으로 변경하는 기능
- pydub를 이용하여 오디오의 샘플레이트를 목표 샘플레이트에 맞게 변경하는 기능
- 정상적이지 않음 음성 파일이 들어오면 작업을 하지 않도록 예외 처리 추가
- 음성 파일의 길이가 1초에서 10초 사이가 아닌 음성 파일에 대한 처리를 하지 않도록 예외 처리 추가
- filelists 폴더 안에 이전에 작업한 음성 파일이 있는 경우 리샘플링하지 않도록 예외 처리 추가