项目旨在以Mask-RCNN为基础进行海洋垃圾识别分类,并对比不同图像预处理下识别的准确性,试图寻找一种有效的水下目标检测识别方法。
若使用Taco训练集训练好的模型评估WaterCo-1.0测试集,但因为数据集背景不同、域间差异而导致效果不佳,即存在Domain gap。迫切的需要一种方法修正测试集,以消除domain gap,使得原有训练模型能够适用于其他数据集。
我们提出了一种消除大气与海洋图片数据集背景差异方法,使用大气训练集得到的训练模型评估海洋测试集变为可能。这种映射方法成为消除域间隔阂的桥梁。
这里我们通过对数据集预处理,由TACO数据集制作WaterCo(-1.0)数据集,WaterCo-2.0数据集,WaterCo-3.0数据集,
TACO数据集:陆地垃圾数据集
WaterCo(-1.0)数据集:水下垃圾数据集
WaterCo-2.0数据集:WaterCo(-1.0)数据集基础上去除domain gap尝试1:颜色校正
WaterCo-3.0数据集:WaterCo-2.0数据集基础上去除domain gap尝试2:去模糊

.png "TACO")
TACO数据集
.png "WaterCO-1.0")
WaterCO-1.0数据集
为模拟水下图像低对比度、低清晰度、蓝绿色为主的特点,本项目中采用一种类似“逆暗通道去雾”的算法对大气图像进行处理,其主要思路为以某一张真实水下图像为参照,通过计算获取该图像的三通道全局背景光及三通道透射率,再结合水下光学成像模型将仓真实水下图像所得参数附加到大气图像上实现水下情况模拟。具体流程如下:
-
通过取每个像素三通道中的最小值组成灰度图得到暗通道;
-
以暗通道中前百分之一亮的像素点对应的三通道均值作为各自的全局背景光;
-
利用信息损失最小、直方图分布优先的方法求出红色通道的透射率
-
利用所得红色通道透射率分别得到绿色透射率和蓝色通道透射率 其中三通道透射率分别为R=0.5、G=0.065、B=0.075;
-
根据水下光学图像成像模型,对大气图像做如下处理:
I_λ (x)=t_λ (x)J(x)+(1-t_λ (x)) B_λ,λ∈{R,G,B}
其中I_λ (x)表示水下模拟图像,J(x)表示清晰的大气图像; -
加入高斯模糊模拟水下模糊的成像效果。
在利用神经网络进行深度图像恢复前,本项目拟用无监督的颜色校正方法先对图像进行初步的颜色校正预处理。该方法综合了RGB颜色模型下的平衡和对比度校正以及HIS颜色模型下的对比度校正,可以有效地消除偏蓝的色泽,增加低红色和低照度的问题,从而获得用于科学目的的高质量图像。具体流程如下:
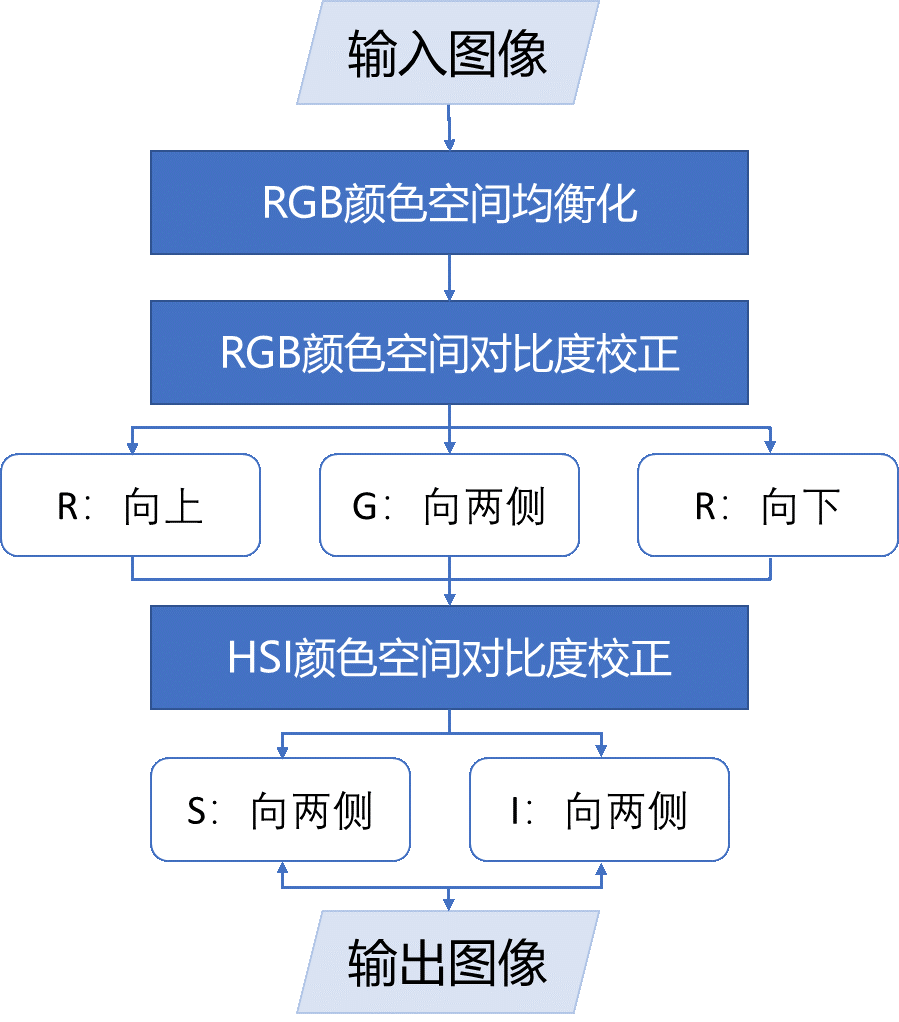
-
RGB下通道均衡:分别计算RGB三通道各自的最大值(R_max/B_max/G_max)和平均值(R_avg/B_avg/G_avg),为平衡RGB三通道,根据Von Kries 假设调整值红、绿色通道:
R'=B_avg/R_avgR G'=B_avg/G_avgG
-
RGB下对比度校正:该步骤关键在于处理像素值在0.2%-99.8%部分使其释放图遍布0-255区域。对绿色通道,直方图需向两端拉伸,该过程可表示为:
P_o=(P_i-X_min )((255-0)/(X_max-X_min ))其中P_o为校正后像素值,P_i为校正前像素值;X_min、X_max分别为绿色通道0.2%-99.8%范围内的最小和最大值。 对红色通道,其直方图需要向大的方向拉伸以达到增强效果,该过程可表示为:
P_o=(P_i-X_min )((255-X_min)/(X_max-X_min ))对蓝色通道则需向小的方向拉伸,该过程可表示为:
P_o=(P_i-X_min )((X_max-0)/(X_max-X_min )) -
HIS下对比度校正:将颜色空间由RGB转到HIS空间后,参照上述扩展方法对饱和度(S)和强度(I)通道进行两边扩展。
——基于Scale-recurrent Network(SRN)的水下数据集质量提升
运用了Xin Tao等人[1]的尺度递归网络(Scale-Recurrent Network,简称SRN),它以不同比例从输入图像中向下采样的一系列模糊图像作为输入,并经过一系列卷积和反卷积运算生成一组对应的清晰图像。在全分辨率下,最清晰的是最终输出。该网络具有训练效率高、测试速度快的优点.
Setup-train
+ model:(百度云链接:https://pan.baidu.com/s/1U_w7PmqVTzqVEhHbaxCGGw 提取码:nv5d)下载到checkpoints/color/checkpoints
+ data:根据datalist.txt放置到./training_set(自建)
+ datalist.txt:记录data对路径,其中每一行前一个是期望输出(TACO原图),后一个是输入(注水后初步去水,即WaterCo-2.0),用空格隔开
+ file.m:用于产生datalist.txt
+ run_model.py:
1. train时如果不用gpu则gpu=-1
2. 其余参照原作者的README.md(放在了./models)
+ model.py:主要修改train函数
1. global_step = tf.Variable(initial_value=420, dtype=tf.int32, trainable=False)中的initial_value改为断点步数(=0则从头开始)
2. ckpt_name = model_name + '-' + str(420)中str()改为断点步数(如果从头开始就把相关202-205行都注释掉)
+ logs.txt:记录训练过程,可根据loss选择合适的model
Setup-test
+ run_model.py:
1. 将args.phase = 'train'注释掉
2. 设置input_path和output_path
+ model.py:主要修改test函数
1. self.load(sess, checkpoint_path, step=420)中step改为断点步数
我们使用Mask-RCNN网络进行训练,Mask-RCNN使用在这之前已经详细讲解,这里不再赘述。
其中我们选择了网络初始权重为COCO数据集训练下的Mask-RCNN权重。训练环境为Keras-2.3.1, tensorflowGPU-1.13.1。实验室4×NVIDIA 1060Ti环境下,能够为模型训练创造良好环境。

-
读取名称映射.csv配置 文件包含了基类与子类的映射,通过这份.csv文件的定义,使得类别之间的关系得到明确。
-
读取WaterCo数据集 读取经过数据集迁移工作得到的WaterCo数据集,并根据参数选择对应读入训练集,忽略测试集、验证集。
-
读取神经网络训练参数配置 使用子类继承基类原始定义,并在子类中修改对应参数,其中包括训练使用GPU数量、GPU显存容量、学习率、学习动量、训练集容量、ROI掩膜尺度等信息,作为神经网络的配置参数。
Crossentropy loss: 于是分类问题,使用经典的交叉熵损失函数
loss = K.sparse_categorical_crossentropy(target=anchor_class,output=rpn_class_logits,from_logits=True)
Optimizer: 选择学习率优化器为SGD
OPTIMIZER = 'SGD'
-
读取网络模型 创建模型框架结构为MaskR-CNN,并根据模型结构选择模型参数权重,初始化权重为COCO数据集训练权重,可以在公开地址中下载到。
-
正式训练神经网络 训练前可以选择是否进行数据增强,如有必要则可以提高模型鲁棒性。在训练步分别设置训练轮数为20/40,学习率为0.001等值,设置模型保存位置,开始模型训练。在训练过程中,需要在每轮中不断保存模型参数与tensorboard信息。
Setup
# First make sure you have split the dataset into train/val/test set. e.g. You should have annotations_0_train.json
# in your dataset dir.
# Otherwise, You can do this by calling
python3 split_dataset.py --dataset_dir ../data
# Train a new model starting from pre-trained COCO weights on train set split #0
python3 -W ignore detector.py train --model=coco --dataset=../data --class_map=./taco_config/map_10.csv --round 0
# Continue training a model that you had trained earlier
python3 -W ignore detector.py train --dataset=../data --model=<model_name> --class_map=./taco_config/map_10.csv --round 0
# Continue training the last model you trained with image augmentation
python3 detector.py train --dataset=../data --model=last --round 0 --class_map=./taco_config/map_10.csv --use_aug
Setup
# First make sure you have split the dataset into train/val/test set. e.g. You should have annotations_0_train.json
# in your dataset dir.
# Otherwise, You can do this by calling
python3 split_dataset.py --dataset_dir ../data
# Test model and visualize predictions image by image
python3 detector.py test --dataset=../data --model=<model_name> --round 0 --class_map=./taco_config/map_10.csv
# Run COCO evaluation on a trained model
python3 detector.py evaluate --dataset=../data --model=<model_name> --round 0 --class_map=./taco_config/map_10.csv
# Check Tensorboard
tensorboard --logdir ./models/logs
[1] Tao, Xin, et al. "Scale-recurrent network for deep image deblurring." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018.
[2] X. Mao, C. Shen, and Y.-B. Yang. Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In NIPS, pages 2802–2810, 2016.
[3] C. J. Schuler, M. Hirsch, S. Harmeling, and B. Schölkopf. Learning to deblur. TPAMI, 38(7):1439–1451, 2016.
[4] Chakrabarti. A neural approach to blind motion deblurring.In ECCV, pages 221–235. Springer, 2016.
[5] S. Su, M. Delbracio, J. Wang, G. Sapiro, W. Heidrich, and O. Wang. Deep video deblurring. pages 1279–1288, 2017.
[6] S. Nah, T. H. Kim, and K. M. Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. Pages 3883–3891, 2017.
[7] C. Dong, C. C. Loy, K. He, and X. Tang. Learning a deep convolutional network for image super-resolution. In ECCV, pages 184–199. Springer, 2014.
[8] Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In MICCAI, pages 234–241. Springer, 2015.
[9] Q. Chen and V. Koltun. Photographic image synthesis with cascaded refinement networks. In ICCV. IEEE, 2017.
[10] Goodfellow, I., Bengio, Y., Courville, A..Deep learning (Vol. 1).Cambridge:MIT press,2016
[11] Gu, J., Wang, Z., Kuen, J., Ma, L., Shahroudy, A., Shuai, B., Liu, T., Wang, X., Wang, L., Wang, G. and Cai, J., 2015. Recent advances in convolutional neural networks. arXiv preprint arXiv:1512.07108.
[12] Girshick R , Donahue J , Darrell T , et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]// CVPR. IEEE, 2014.
[13] Girshick R . Fast R-CNN[J]. Computer ence, 2015.
[14] Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.
[15] Kaiming H , Georgia G , Piotr D , et al. Mask R-CNN[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, PP:1-1.
[16] 侯国家. 一种水下光学图像的模拟方法:**,201910142744.X [P]. 2019-07-30
[17] Iqbal, Kashif, et al. "Enhancing the low quality images using unsupervised colour correction method." 2010 IEEE International Conference on Systems, Man and Cybernetics. IEEE, 2010.
[18] 凌梅. 基于卷积神经网络的水下图像质量提升方法. MS thesis. 厦门大学, 2018.