Enforced Density-Based Spatial Clustering of Applications with Noise.
This package is an extension on the DBSCAN algorithm to enable for pre-labeled data points in the clusters, or in other words to enforce certain cluster values and splits. It mimics the scikit-learn implementation of sklearn.cluster.DBSCAN.
You can either install the package through PyPI:
pip install edbscanOr via this repository directly:
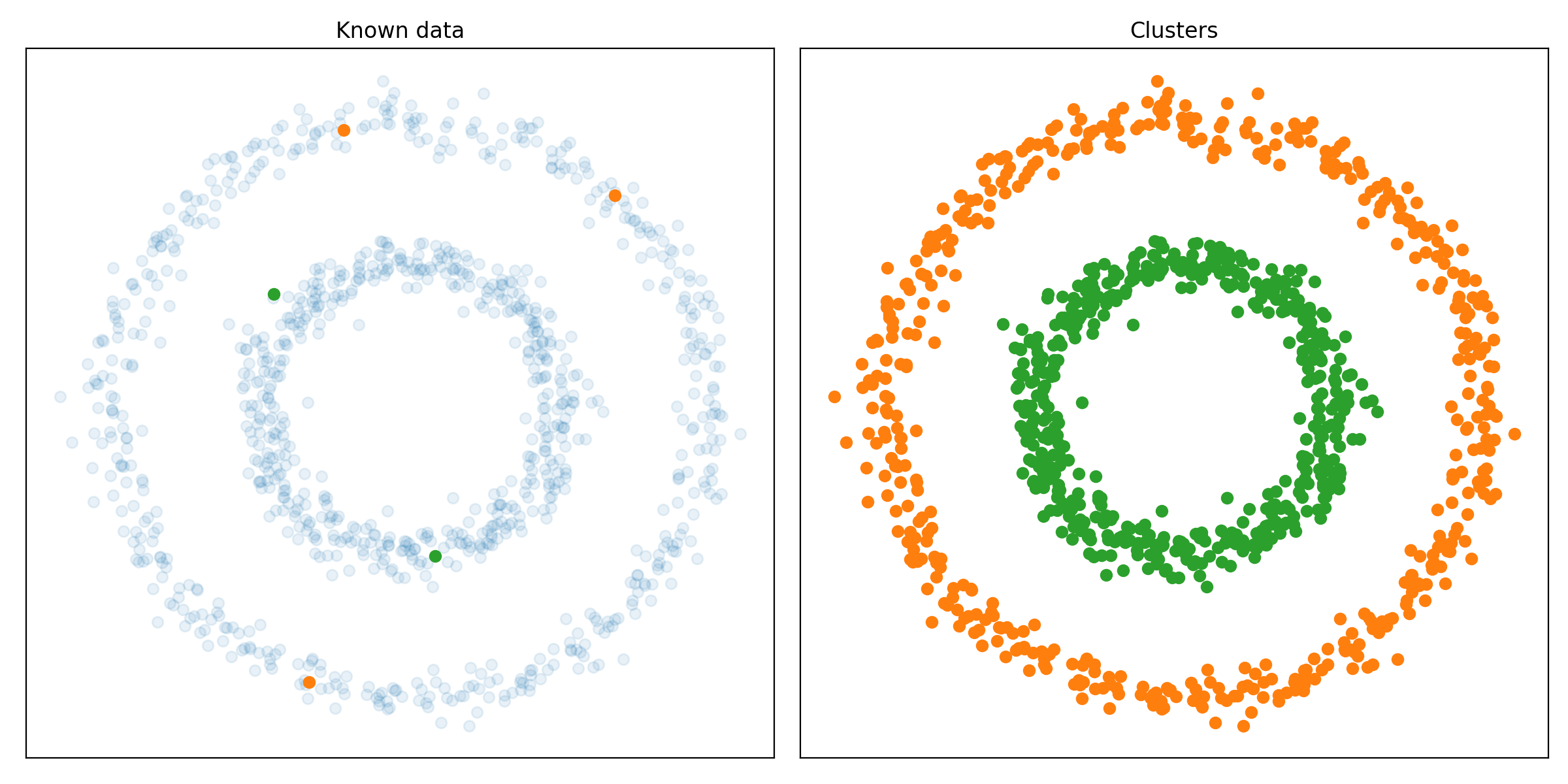
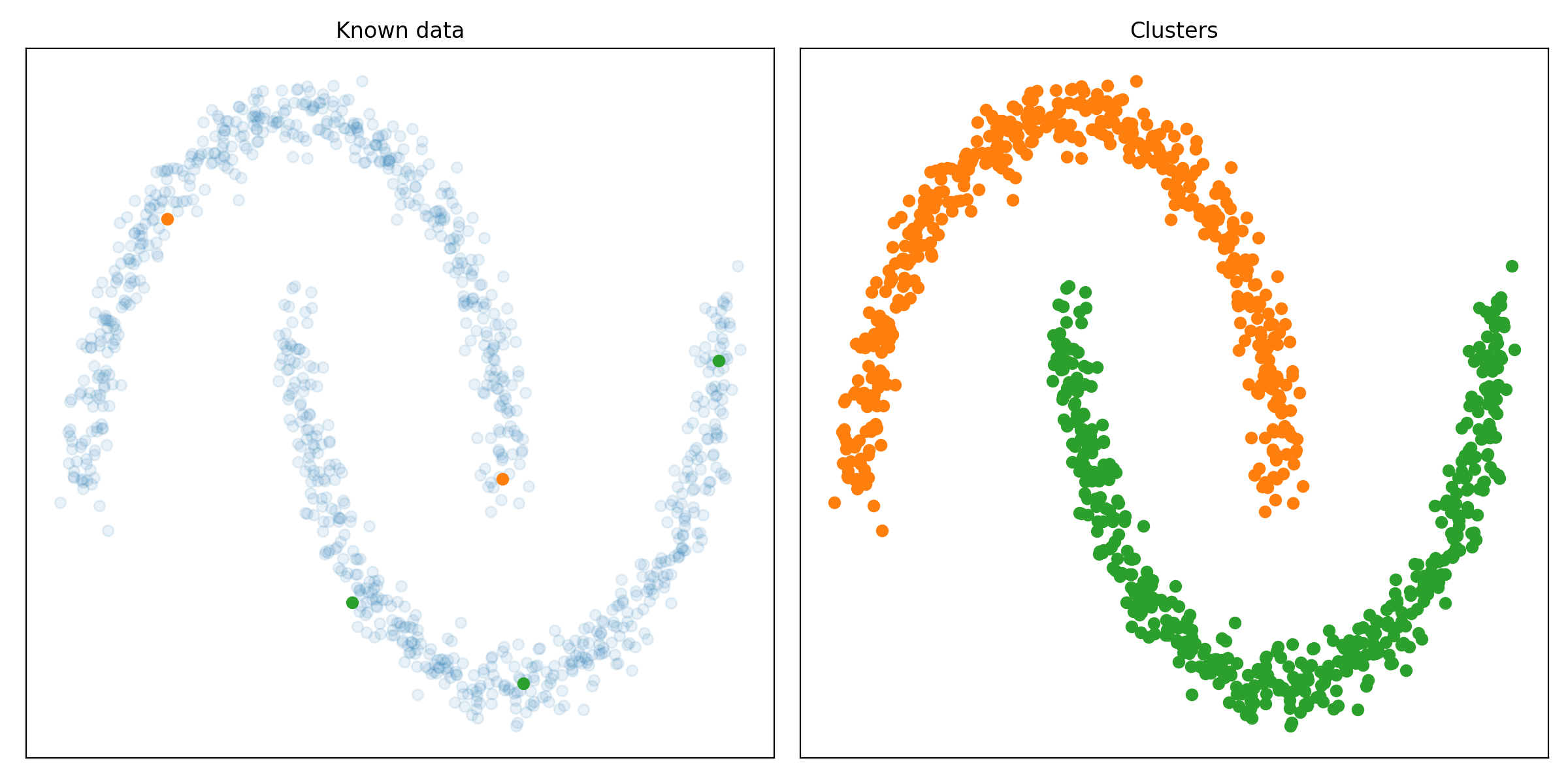
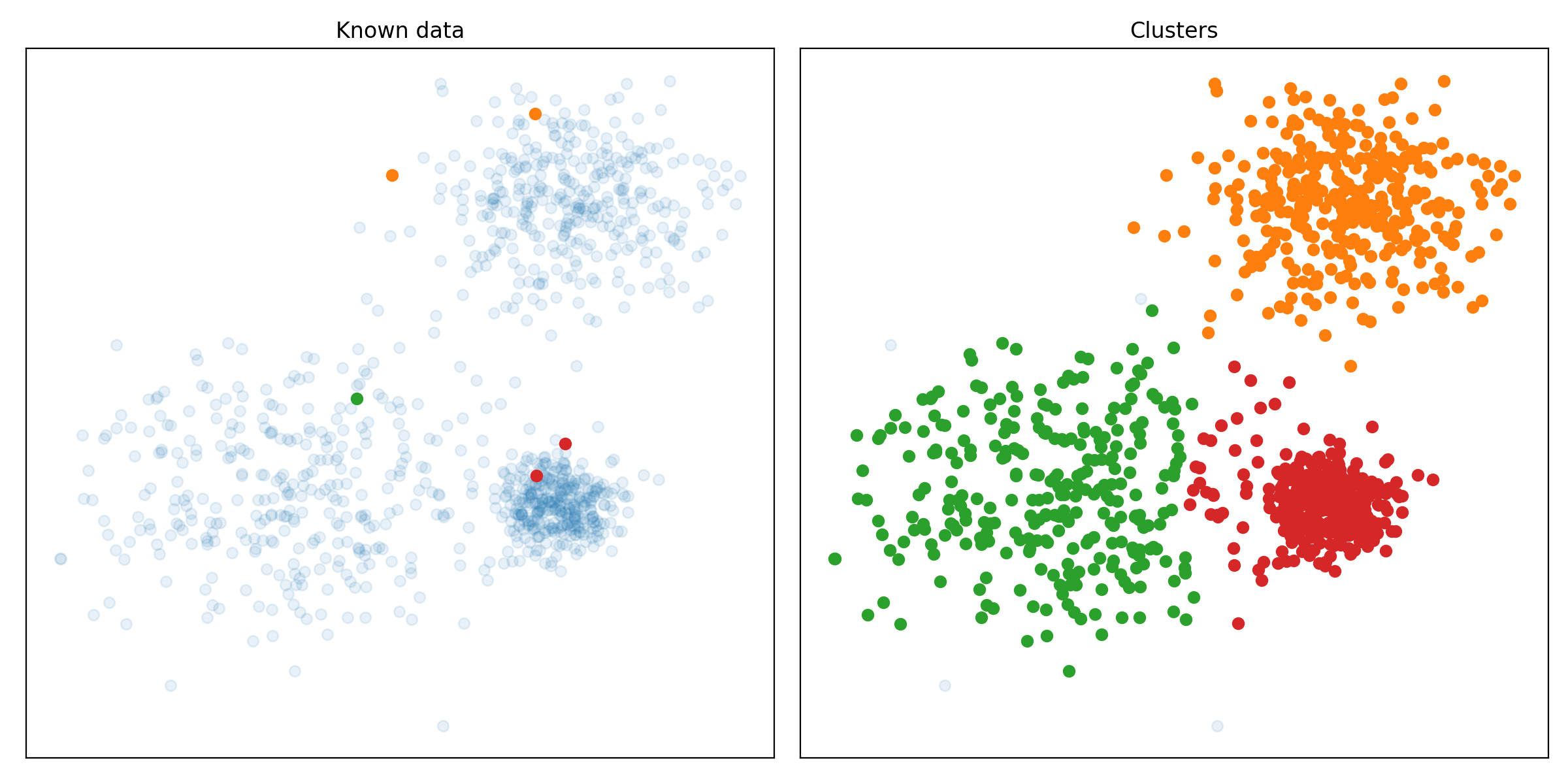
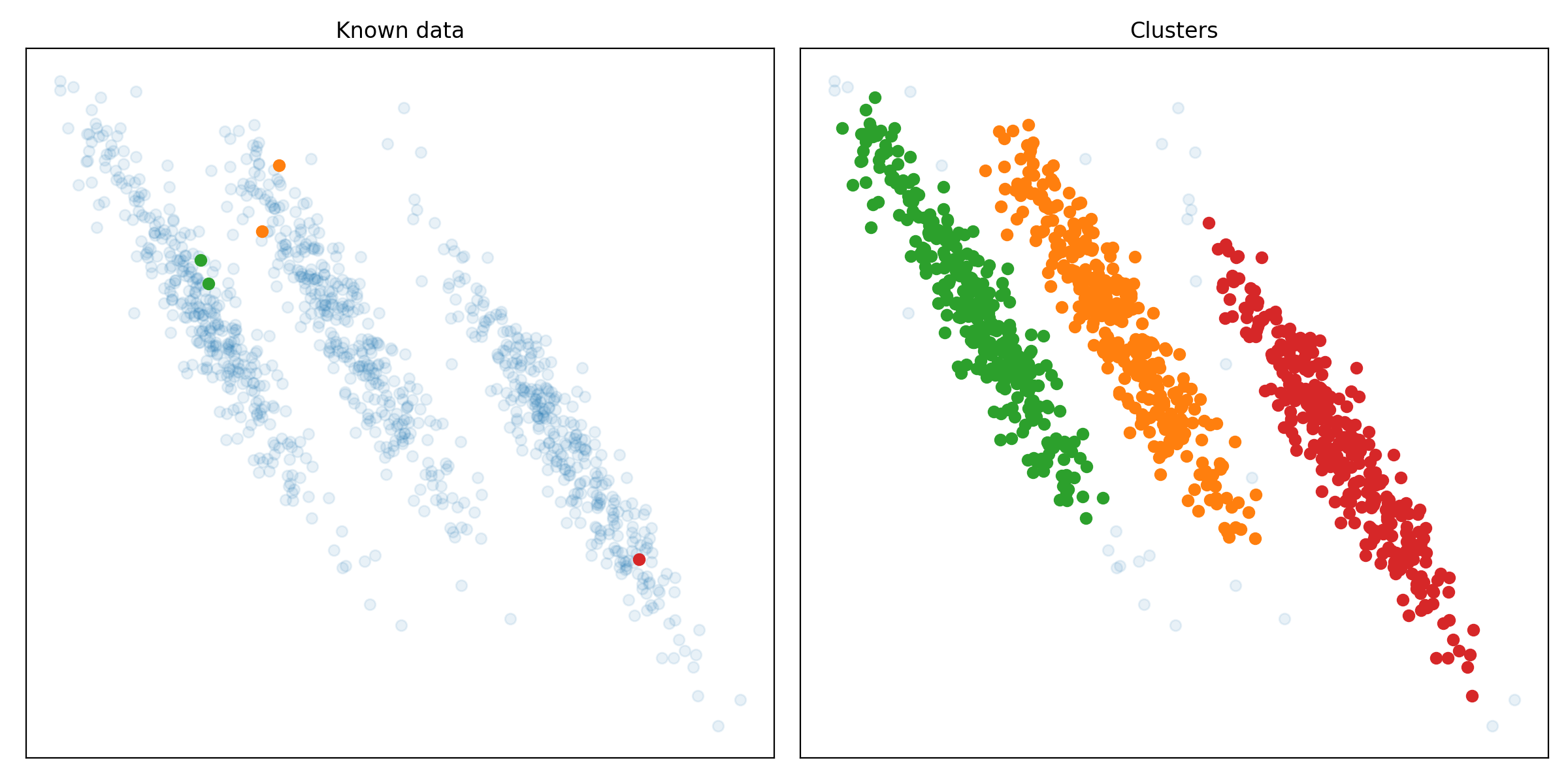
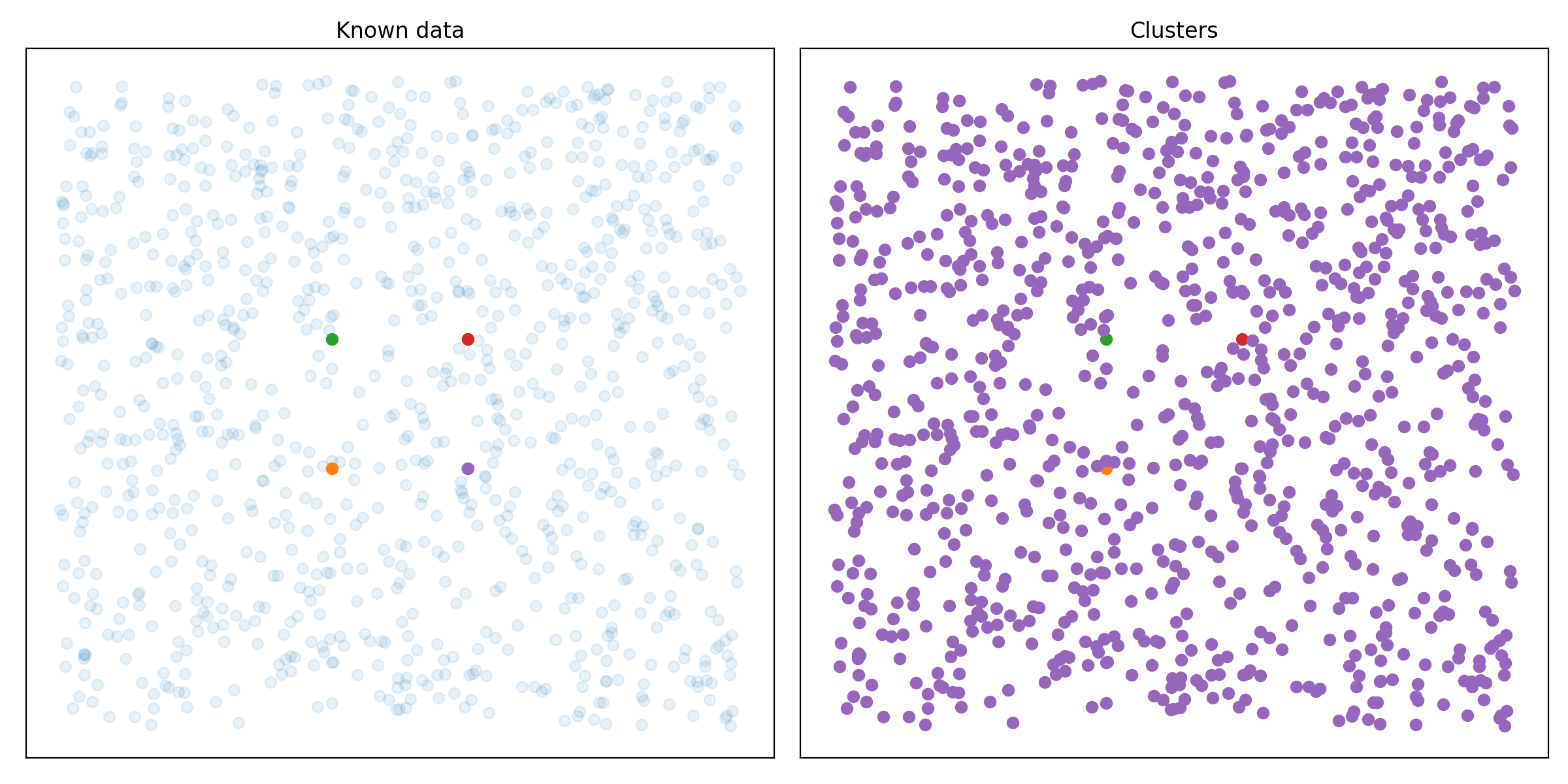
pip install git+https://github.com/RubenPants/EDBSCAN.gitThe image below shows you the result of EDBSCAN on a given input. The image on the left shows you the raw input data, together with the few labeled samples. The image on the right shows the clusters found by EDBSCAN, where the light blue dots represent the detected noise.
# Load in the data
import numpy as np
data = np.load(open('data.npy'))
print(data.shape) # (220, 2)
y = np.load(open('y.npy'))
print(y.shape) # (220, )
print(y) # array([None, None, …, -1, None, …, 0, None, …, 1, …], dtype=object)
# Run the algorithm
from edbscan import edbscan
core_points, labels = edbscan(X=data, y=y)
print(labels) # array([-1, 2, 2, 4, -1, -1, 6, 3, 4, …])As shown in the code snippet above, aside from the raw data (data), a target vector y is provided. This vector indicates the known (labeled) clusters. A None cluster label are those not yet known, that need to get clustered by the EDBSCAN algorithm.
For more detailed usages, see the notebooks present in the examples/ folder.
There are three concepts that define how EDBSCAN operates:
- The DBSCAN algorithm on which this algorithm is based on, read the paper or the scikit-learn documentation for more.
- Semi-supervised annotations, represented by the
yvector in the Usage section. This vector contains three types of values:Noneif the given sample is not known to belong to a specific cluster and needs to get labeled by the EDBSCAN algorithm-1if the given sample is known to be noise0..Nif the given sample is known to belong to cluster0..N
- Where DBSCAN expands its clusters in a FIFO fashion, will EDBSCAN expand its clusters in a most dense first fashion. In other words, the items that have the most detected nearest neighbours get expanded first. By doing so, the denser areas get assigned a cluster faster. This prevents two dense cluster that are near each other from merging if they are already assigned a different label.
This section compares EDBSCAN to (1) other clustering algorithms as DBSCAN and HDBSCAN, and (2) on different clustering benchmarks.
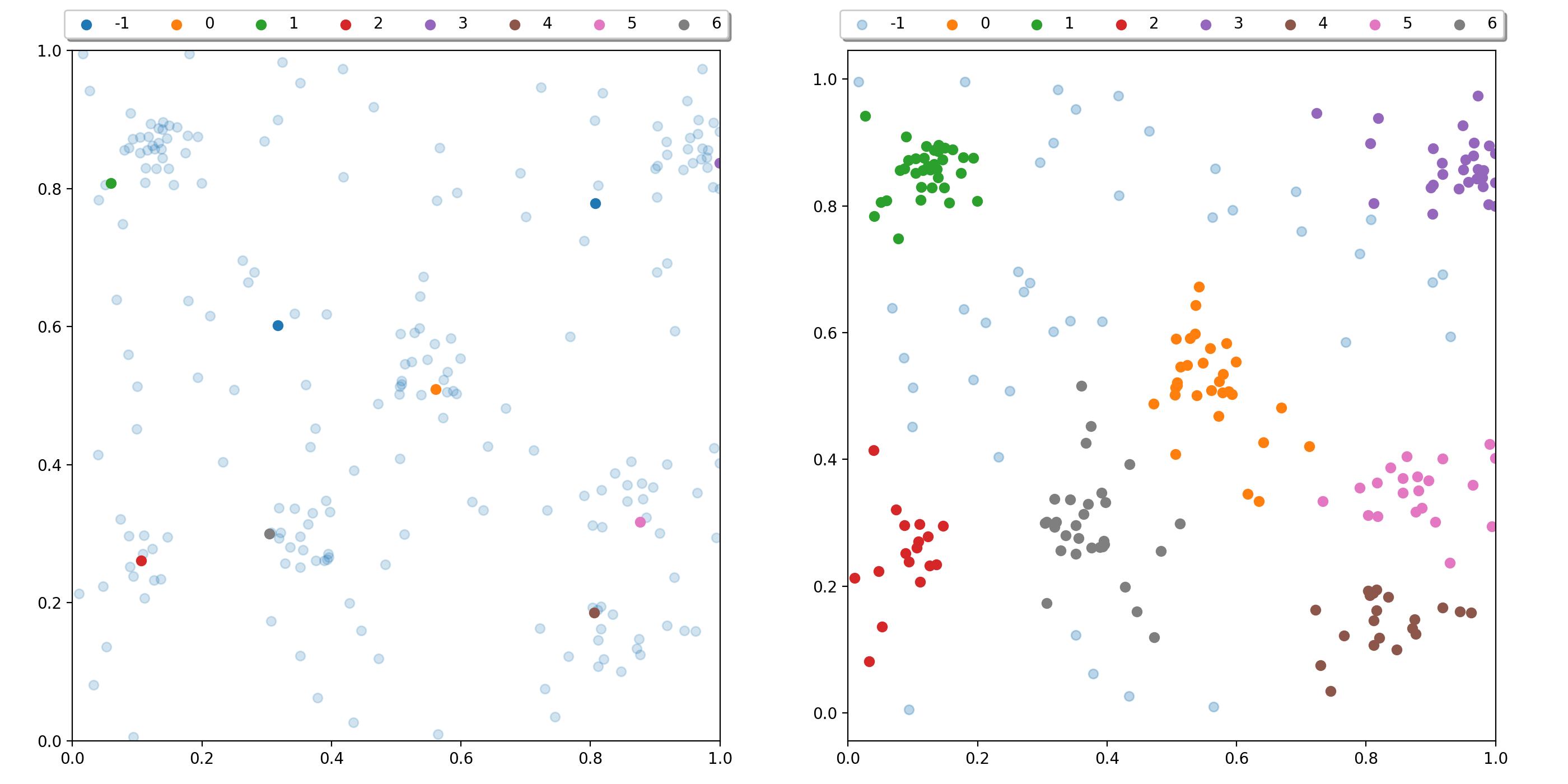
This section compares the behaviour of the DBSCAN algorithm, the HDBSCAN and the EDBSCAN algorithm on the data shown in the Usage section. The input data looks as follows:
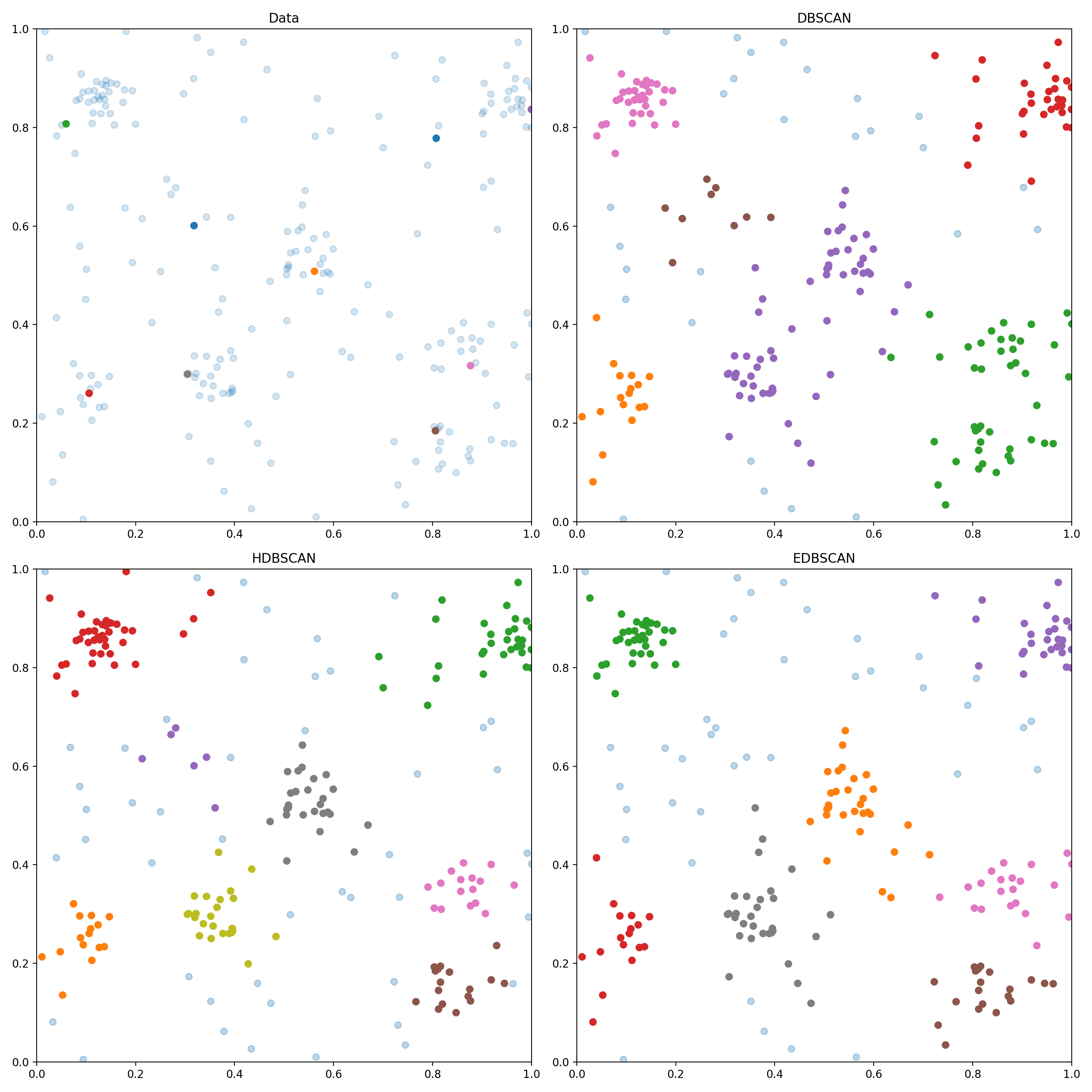
In each of the clustered results, light-blue data represents the detected noise.
Some observations on the DBSCAN result:
- Green combined two clusters that should be separated
- Purple combined two clusters that should be separated
- Brown identified noise as a cluster
Some observations on the HDBSCAN result:
- Yellow and Grey are now successfully separated
- Brown and Pink are now successfully separated
- Purple identified noise as a cluster
Some observations on the EDBSCAN result:
- Grey and Orange are now successfully separated
- Brown and Pink are now successfully separated
- The noise that was previously detected as a cluster is now successfully identified as noise
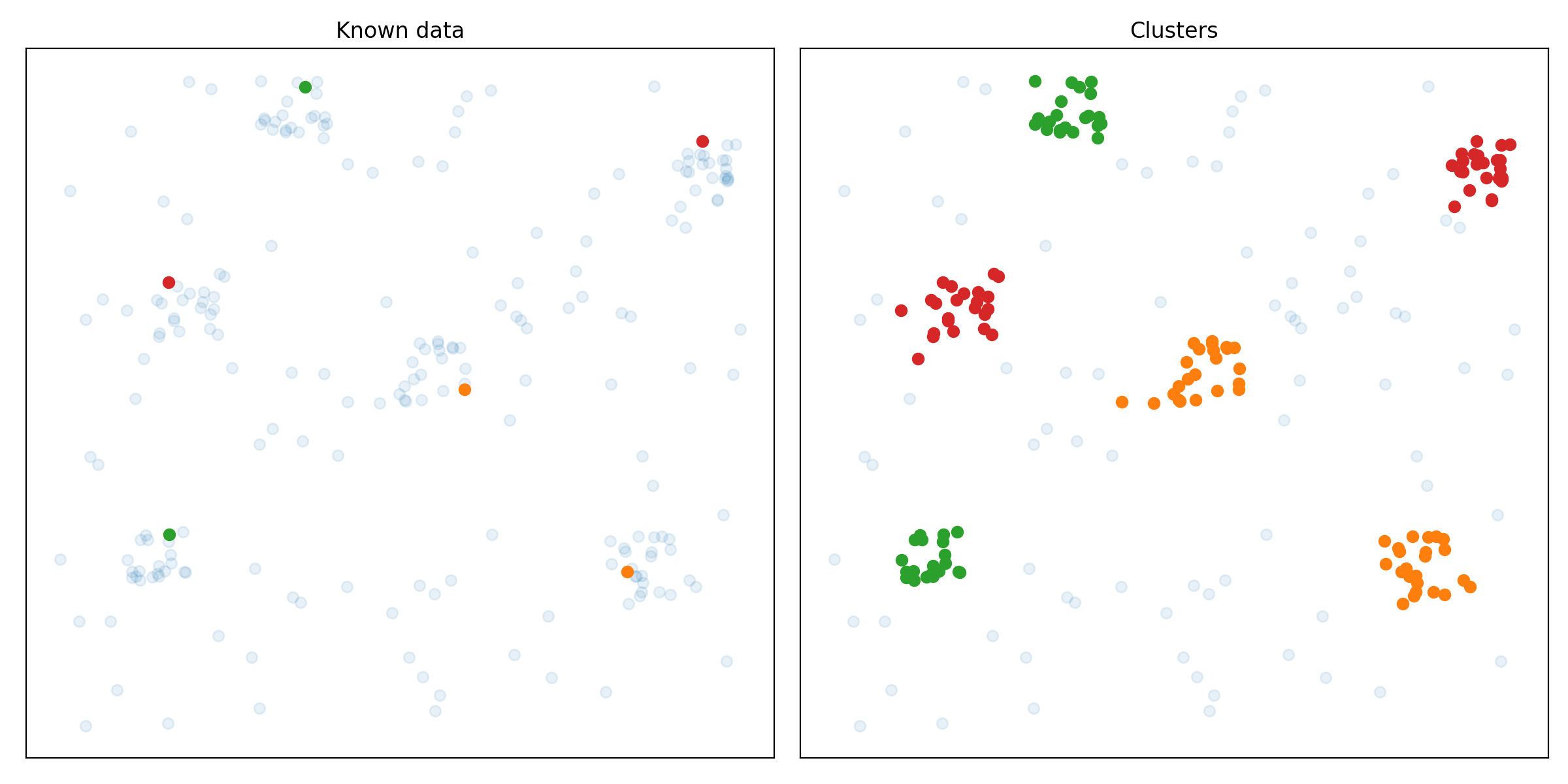
The following images show the results of the EDBSCAN algorithm on different scikit-learn clustering benchmarks.