This is the repo for the recommendation system project made for Bhuvan Portal for submission during hackathon organized on hack2skill.
Team Name: Sirius Coders.
Team members: Rushin Shah, Rushi Jhala, Dev Chauhan, Ruchita Rathod.
We have made a Recommendation System for Bhuvan Portal to help people find a relevant dataset according to query and past history.
We have used Tensorflow Recommenders to create this system. Using it we have create real time recommendation model which is divided into three stages:
- Candidate Selection or Retrival Phase (Using Vector Embedding to narrow down millions of database to few thousands using famous Two Tower Model)
- Ranking Phase (Narrowing down thousands of datasets to few hundered through user history and context)
- Post-Ranking Phase (Further Narrowing Down to dozens using current session context).
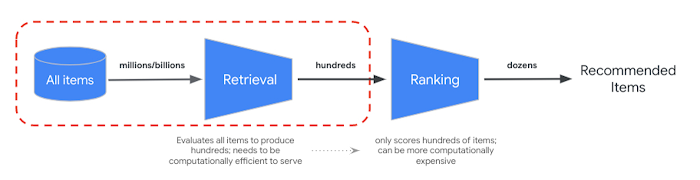
Each the stages narrows down the recommended dataset by some magnitude in order to avoid bottleneck at any specific stage and achieve the best result.
Currently, We have Generated a Synthetic DataBase which consists of:
* Users Database
* Dataset Database
* Download logs Database
Currently we have made three csv files for each but this can be improved using Relational Databases and using vector Databases
* Currently we train the users tower of the model using features like: Occupation Of the user.
* And for the Query tower, we have used Features like: Previous download by the user, current query of the user.
We have only implemented the training portion of the first phase and other two phase are still in progess
- Fork the Repo.
- Setup up python Virtual Environment using
python -m venv {ENV_NAME} - Install all the dependency according to requirements.txt file -----
pip install -r requirements.txt - Run data_creation.py to produce data
- Run candidate_model.py to train candidate phase of the model.