python-3.6+, Java-1.8, maven-3.0.4
-
克隆该仓库
git clone https://github.com/Rvlis/Open_Information_Extraction.git cd Open_Information_Extraction -
安装包
pip install -r requirements.txt -
安装 stanza,stanza支持通过python接口访问JAVA编写的自然语言处理工具 Stanford CoreNLP
git clone https://github.com/Rvlis/stanza.git cd stanza pip install -e .
-
安装 Stanford CoreNLP
cd Open_Information_Extraction pythonimport stanza stanza.install_corenlp("路径值,绝对路径,建议放在Open_Information_Extraction目录下")
-
添加环境变量
CORENLP_HOME=4.中路径值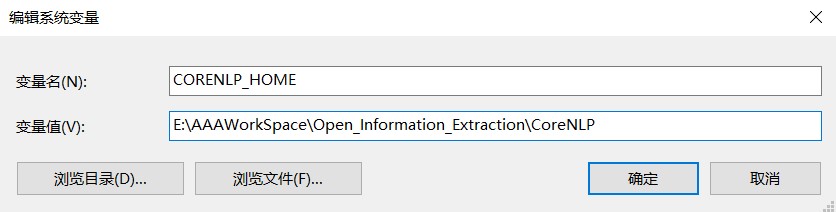
-
安装 neuralcoref 实现共指消解
git clone https://github.com/Rvlis/neuralcoref.git cd neuralcoref pip install -r requirements.txt pip install -e .
-
安装Spacy预训练模型,下载该链接下的
.tar.gz文件并安装cd Open_Information_Extraction pip install en_core_web_md-2.3.1.tar.gz -
环境配置完成后,运行demo,对单句进行关系三元组抽取
cd OIE/src python run.py
得到以下输出结果
>>> Bell, a telecommunication company, which is based in Los Angeles --> (Bell; is based in; Los Angeles) >>> Bell, a telecommunication company, which is based in Los Angeles --> (Bell; "is" ; a telecommunication company)

阅读以下参考文献或任何其他参考资料,了解本实验中复合句简化的原理
Context-Preserving Text Simplification
OIE/src/C2S_part/: C2S(Complex To Simple),复合句简化,基于stanford corenlp工具实现
实验内容的核心部分,要求 熟练掌握 该阶段原理和实现,对于该阶段所设计到的相关知识(包括Tokenize、词性标注POS、依存解析等,以及使用代码过程中遇到的障碍)都要做到熟练掌握
OIE/src/NER_part/corenlp_chunk_candidate_relations_triples.py
-
基于规则的显式短语识别
-
这一步中显式短语的识别方法是通过 建立关于词性标注(POS tagging,part-of-speech tagging)的正则表达式
-
正则表达式代码:19-59
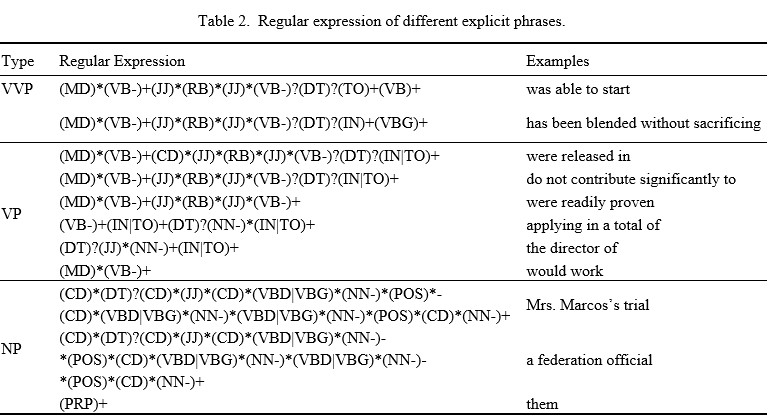
- 匹配代码:226-278
-
-
基于深度学习的显式短语识别
- 这一步中显式短语的识别方法是 使用自然语言处理工具(例如 Spacy)进行命名实体识别, 识别出的实体也归类为“显式实体”
- 匹配代码:283-338
-
隐式短语扩展(两种扩展规则)
- 识别名词短语中形容词修饰语的第一规则:70-120
- 识别名词短语中核心名词的第二规则:122-151

同上
-
关系抽取阶段是通过制定一组结合语言场景与依存解析的规则来过滤掉实体识别阶段中无用的短语,并进一步利用保留的短语生成关系三元组
-
由于自然语言的特性,同一语义会有多种不同的表达方式,这也进一步导致了自然语言语句的冗长性和结构复杂性。 通过大量的实证研究,我们总结出 六种 常见的、不同的语言场景来处理这一特性,这六种场景 并非完全独立,通过 对这六种场景的不同组合,我们可以对一些结构复杂的长句进行有效的处理
-
六种语言场景分别为:
- 主谓宾结构(含主动时态和被动时态): Scenario-1,2 (64-114, 117-149)
- 主系表结构: Scenario-8 (337-360)
- 补足语关系: Scenario-5 (180-214)
- 处理出现在VVP短语中的补语成分: Scenario-5 (180-214)
- 并列关系: Scenario-7 (306-335)
- 同位语关系: Scenario-6 (218-265)
-
在 Open_Information_Extraction 路径下载开源评测工具CaRB:包括数据集+评测工具
- 对评测工具作了解即可,理解其评测原理和数据集中数据来源、标注方法等
- 参考文献 CaRB: A Crowdsourced Benchmark for Open IE
cd Open_Information_Extraction git clone https://github.com/Rvlis/CaRB.git或者点击此链接下载该仓库后解压到 Open_Information_Extraction 路径下,解压后文件夹名为 CaRB
-
安装运行CaRB所需要的包
pip install -r ./CaRB/requirements.txt
-
规范本OIE工具的输入格式以满足CaRB要求——Tab seperated, 具体格式为[sentence probability predicate arg1 arg2], 具体流程为:
- 批量处理输入句子,参考代码OIE/src/run.py 批量抽取部分
- 格式化输出,参考代码OIE/src/run.py 性能评估部分
cd OIE/src python .\run.py --type 1
-
性能评估
cd ../../CaRB python carb.py --gold=data/gold/dev.tsv --out=dump/OIE.dat --tabbed ../OIE/data/CaRB_output_dev.txt
-
(待做) 除直接的性能评估外,后续还可能进行消融实验(比如w/o共指消解、w/o复合句简化)来补充实验部分内容
- w/o共指消解
cd OIE/src python run.py --type 1 --coref 0 cd ../../CaRB python carb.py --gold=data/gold/dev.tsv --out=dump/OIE-wo-coref.dat --tabbed ..\OIE\data\CaRB_output_dev_wo_coref.txt
- w/o复合句简化
cd OIE/src python run.py --type 1 --simp 0 cd ../../CaRB python carb.py --gold=data/gold/dev.tsv --out=dump/OIE-wo-simp.dat --tabbed ..\OIE\data\CaRB_output_dev_wo_simp.txt