Computer vision is one of the main areas where Artificial Neural Networks are frequently deployed to classify images. How these networks deal with various aberrations in the images is an ongoing field of research.
In this project, we use the ASIRRA dataset that contains images of dogs and cats to test the binary classification efficiency of a downscaled AlexNet, one of the most famous Artificial Neural Network used in computer vision using cross-entropy as loss function, ADAM optimizer, and early stopping to prevent overfitting and minimize training duration.
This network is trained on different variations of the dataset which are pathophysiologically analogous to various visual distortions of the human visual system like full or partial color blindness, blurriness. We use gaussian noise (of radius 2 and 5) and decrease the resolution to 64x64 pixels to simulate vision with lost glasses, color removal as an analog for partial color blindness, greyscale for full-color blindness, and some additional artificial errors such as salt and pepper, and speckle.
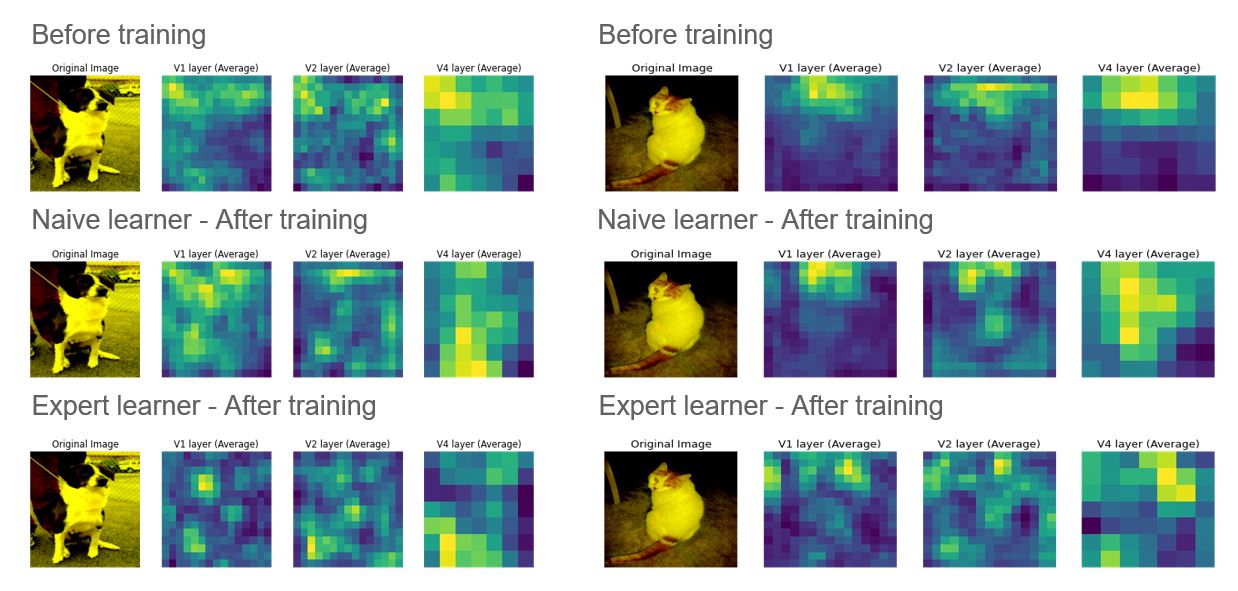
We also see the heat activation maps of the various error types to get a visual idea of the feature extraction being done in the network for various errors. We expect to see differences in accuracy and the number of epochs taken to reach suitable accuracy for different errors and understand why this Artificial Neural Network may perform better on specific variations.

- We use ASIRRA dataset containing images of cats and dogs as a binary classification problem.
- Introduce some errors that are biologically plausible such as -
- Gaussian noise for vision blurriness
- Greyscale for full color blindness
- Individual color removal for partial color blindness
- Synthetic errors such as salt and pepper, and speckle
- Downscaled Alexnet (by 2) and 64x64 images to increase speed.
- ADAM optimizer along with cross-entropy as loss function.
- Regulariser - Early stopping
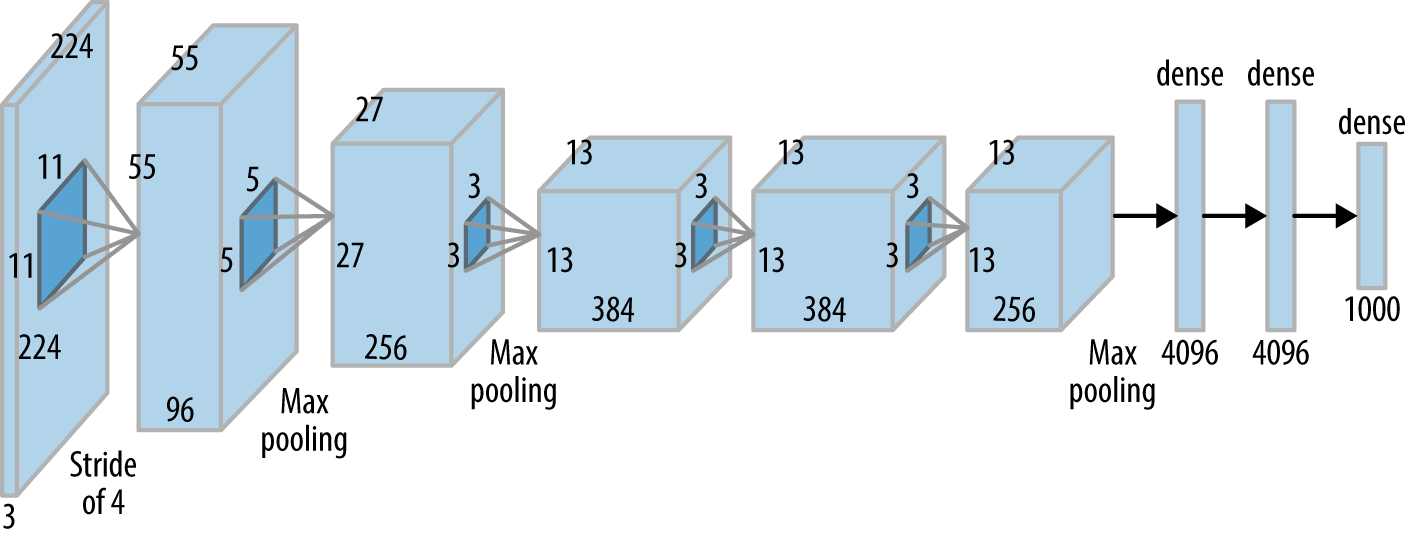

- Naive learner
Trains directly on specific errors. - Expert learner
First trains on clear images and then on specific errors. - Intermediate layer outputs
Shows how V1, V2, and V4 layers look for specific images.
- Gaussian Blur 5

- Gaussian Blur 2

- Color Removal

- Speckle Noise

- Salt and Pepper Noise

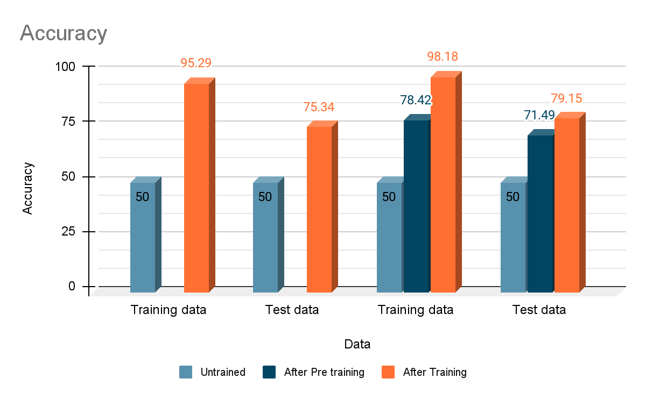
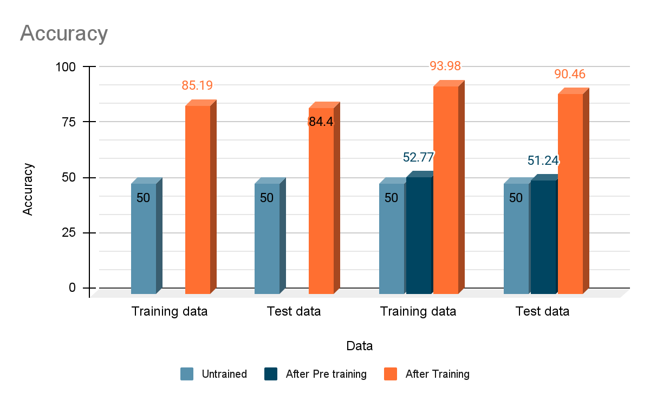
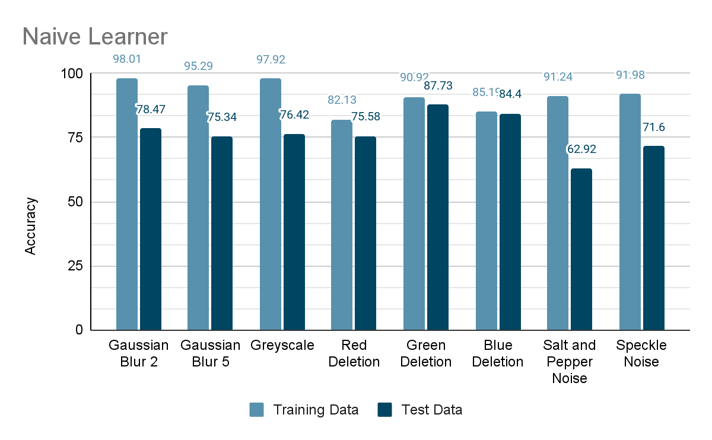
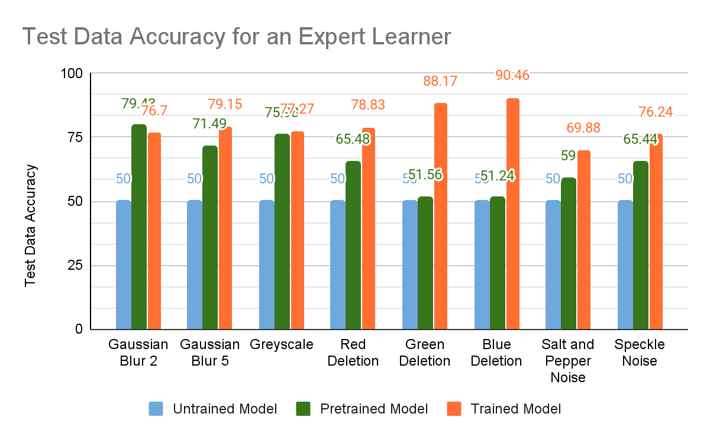
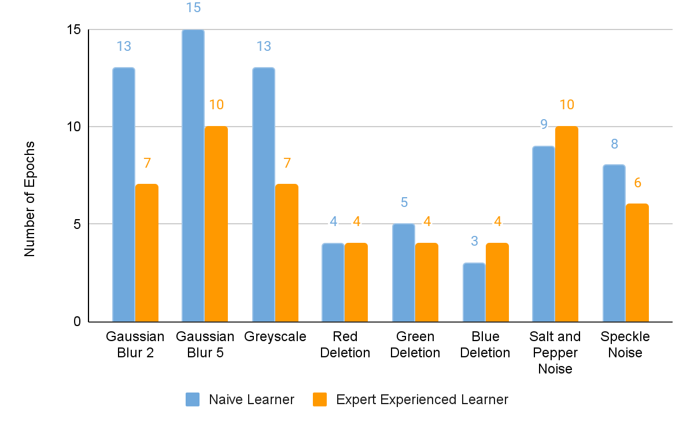
- Trained models perform better than untrained ones!
- For Gaussian noise and Grayscale images -
- Good accuracy on Pretrained Model
- Less number of epochs for training a pre-trained model
- Poor performance on single color deletion unless trained