Note: The error estimation logic based on variational sampling can be found here. Since then, we have made much change to this repository to test different ideas.
Update: This repository is no longer actively maintained. You can still contact the authors (Yongjoo Park, Barzan Mozafari) for questions.
Project website: https://verdictdb.org
Documentation: https://docs.verdictdb.org


VerdictDB brings you Interactive-speed, resource-efficient data analytics.
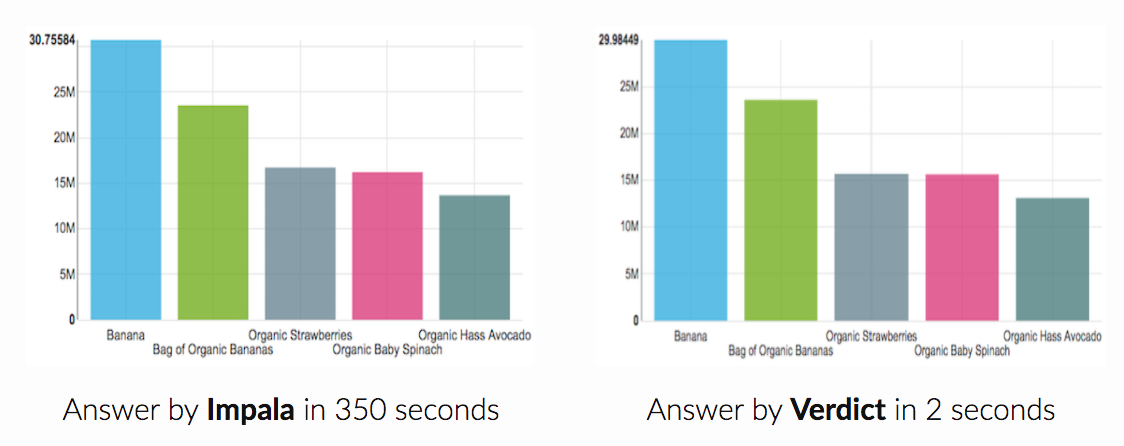
- 200x faster by sacrificing only 1% accuracy VerdictDB can give you 99% accurate answers for your big data queries in a fraction of the time needed for calculating exact answers. If your data is too big to analyze in a couple of seconds, you will like VerdictDB.
- No change to your database VerdictDB is a middleware standing between your application and your database. You can just issue the same queries as before and get approximate answers right away. Of course, VerdictDB handles exact query processing too.
- Runs on (almost) any database VerdictDB can run on any database that supports standard SQL. We already have drivers for Hive, Impala, and MySQL. We’ll soon add drivers for some other popular databases.
- Ease of use VerdictDB is a client-side library: no servers, no port configurations, no extra user authentication, etc. You can simply make a JDBC connection to VerdictDB; then, VerdictDB automatically reads data from your database. VerdictDB is also shipped with a command-line interface.
Find out more about VerdictDB by visiting VerdictDB.org.
When you issue standard SQL queries as below, VerdictDB quickly returns an approximate answer to the query with an error bound (the true answer is within the error bound).
select city, count(*)
from big_data_table_sample
where arbitrary_attr like '%what i want%'
group by city
order by count(*)
limit 10;A user may run the above query without VerdictDB. However, simply replacing the original tables (e.g., big_data_table) with its sample table could result in largely incorrect answers when the query is executed directly on the database. VerdictDB automatically handles such translations so its answers are accurate (1-2% within the exact answers).
All you need to do before observing such speedups is creating samples (which we call scrambles in VerdictDB) with just a single SQL expression.
CREATE SCRAMBLE big_data_table_sample FROM big_data_table;
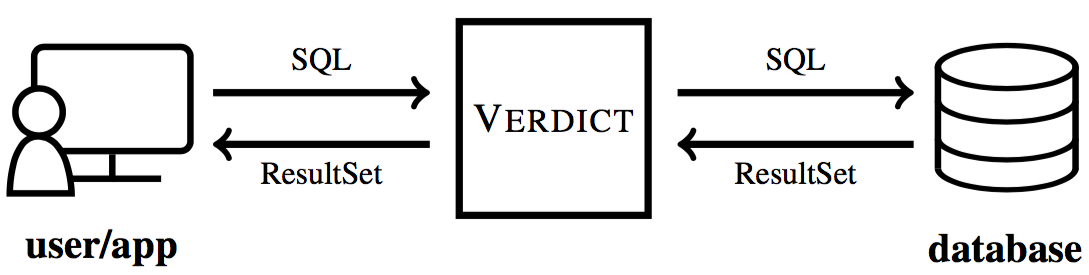
VerdictDB supports the standard interface such as JDBC. For Apache Spark, you can simply include VerdictDB's jar file and issue queries to VerdictDB's SQL context.
Due to its support for standard interface, VerdictDB integrates easily with popular front-end tools, such as Apache Zeppelin, Hue, Jupyter notebooks, and so on.
You only need to download a couple of jar files to get started. VerdictDB does not require "sudo" access or any complicated setup process. Go to this download page to find out the files relevant to your data analytics platforms. We already provide pre-built jar files for Cloudera distributions, MapR distributions, and official Apache Spark. You can also build from the source code using the standard build tool, Apache Maven.
VerdictDB speeds up aggregate queries, for which a tiny fraction of the entire data can be used instead for producing highly accurate answers. There are many theories and optimizations as well we developed and implemented inside VerdictDB for high accuracy and great efficiency. Visit our research page and see innovations we make.
We maintain VerdictDB for free under the Apache License so that anyone can benefit from these contributions. If you like our project, please star our Github repository (https://github.com/mozafari/verdictdb) and send your feedback to verdict-user@umich.edu.