
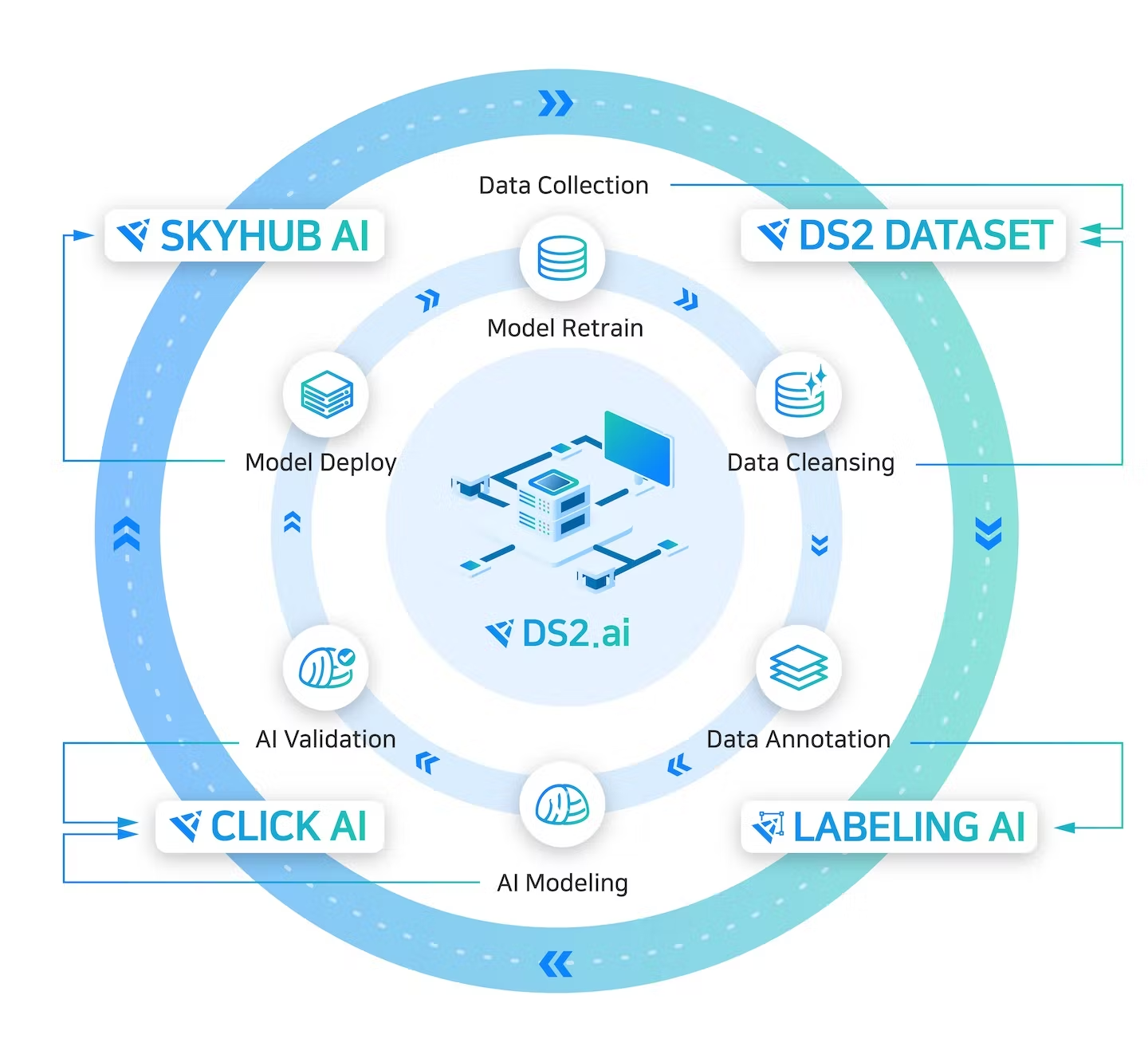
Easiest way to use AI models without coding (Web UI & API support)
English | 한글

-
Easy to use SOTA models including OCR, GPT, STT, TTS, Image to Text, Translations
-
Manual & Auto Annotation Tools (Tableur, Text, Image, Recommeder system)
-
ML & DL Training (Pytorch, Tensorflow, XGboost, etc)
-
AI Aalytics (Prescriptive analysis and Data analytics with Metabase)
-
AI Model Deployment and monitoring
-
Use Active learning process
-
API & Python SDK Support
Extended documentation for DS2




and also you can use OCR, Text summary, fill mask, text to speech (TTS). In DS2, you can change the model to another one from Hugging face.
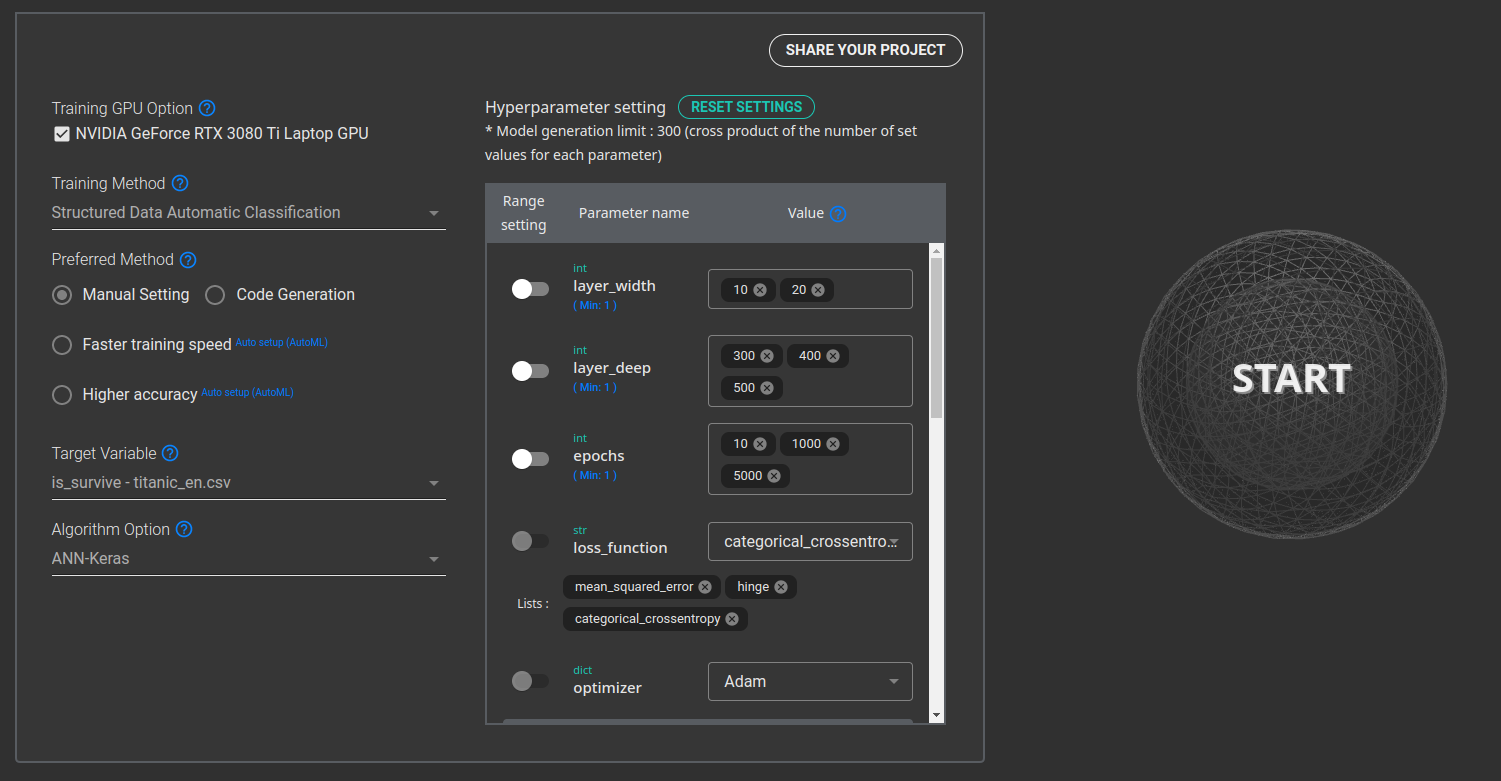
After labeling is complete, artificial intelligence can be developed using the learning data. Click the “Start AI Development” button on the dataset or labeling project screen to enter the setting screen for AI development. On the setting screen, three types of development environments are supported.
- Manual setting: Select the desired deep learning & machine learning library (Pytorch, Tensorflow, XGboost, etc.)
- Fast learning speed (AutoML): A function that creates a model by speeding up the learning rate among AutoML learning techniques
- High Accuracy (AutoML): A function that creates a model with high accuracy among AutoML learning techniques
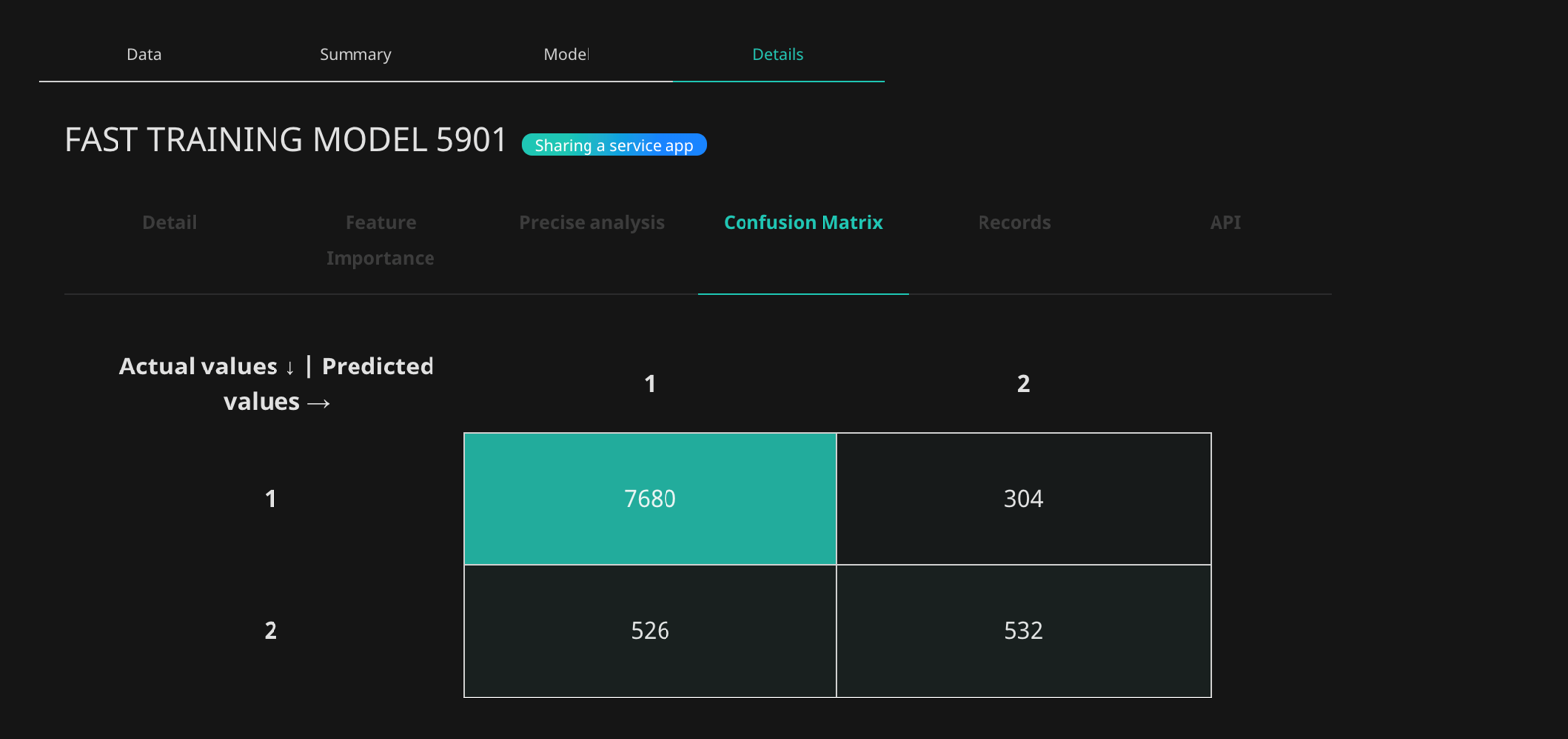
After selecting the desired learning method, click the Start button on the right to start learning. If you click the "Model" tab at the bottom after starting, you can check the progress of the model being developed. It provides the function of "distribute" and the function of "analyzing" through the data set of the prediction result created by the model.
-
Setting Training Options
-
Confusion Matrix
-
Feature Importance
.png?alt=media&token=a8418d6c-1f51-46f6-b70c-e1e5eb25e940)
Once the optimal model has been selected, prescriptive analysis can be run to gain insights from sentences built around explainable AI (XAI).

You can use the Deploy Model function by completing training through DS2.ai or uploading a model you have already created to DS2.ai. (The ability to upload models directly supports Pytorch and Tensorflow2 models.)
You can upload by clicking the "Deploy" menu button at the top or distribute the developed model through the "Deploy" function in the "Learning" menu. The deployed model can be managed through a separate endpoint, and the number of API calls can be monitored.
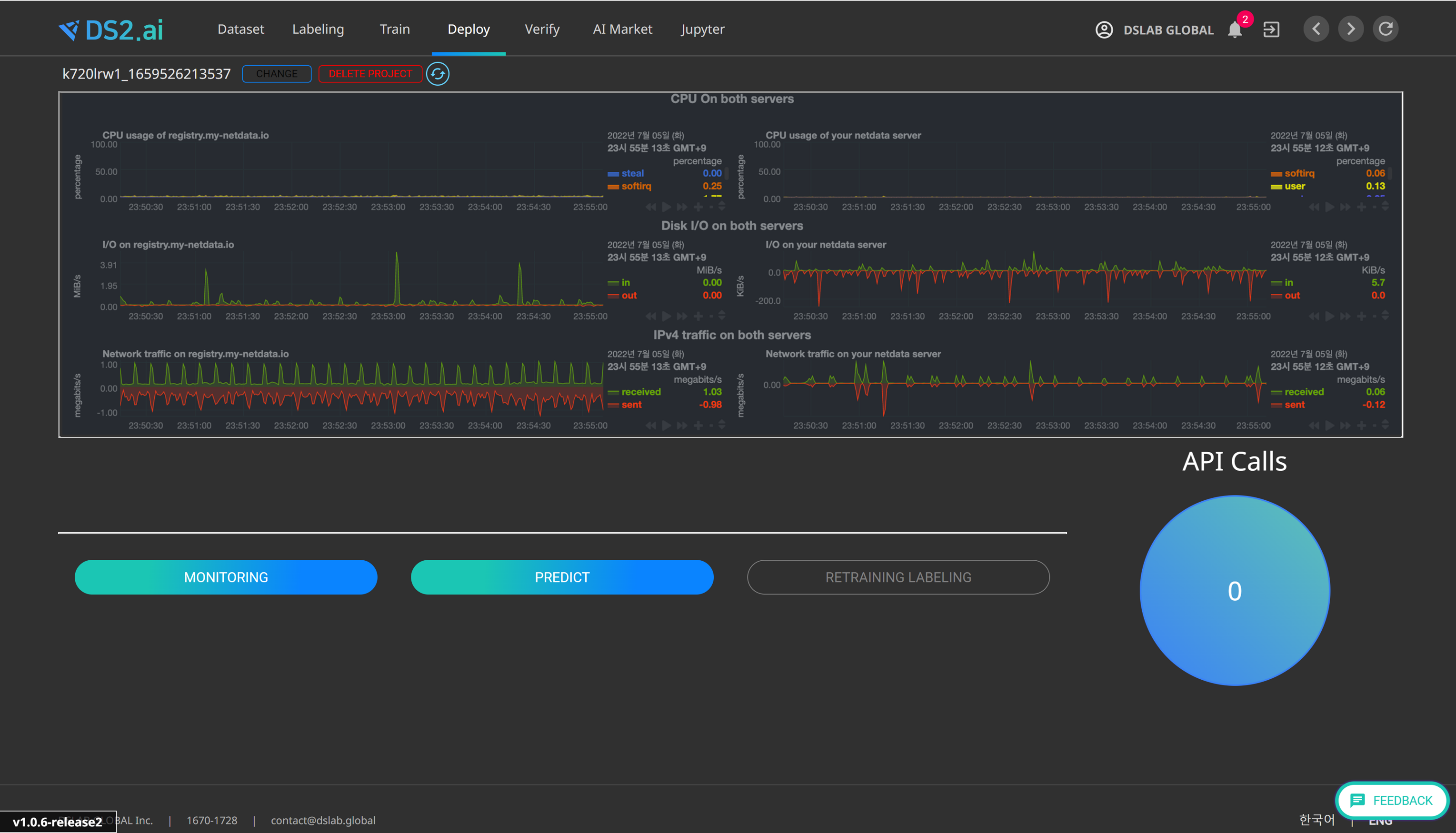
After the model is deployed, the input and output values used for prediction are automatically stored in the dataset, helping to quickly and easily create AI with higher accuracy through active learning.
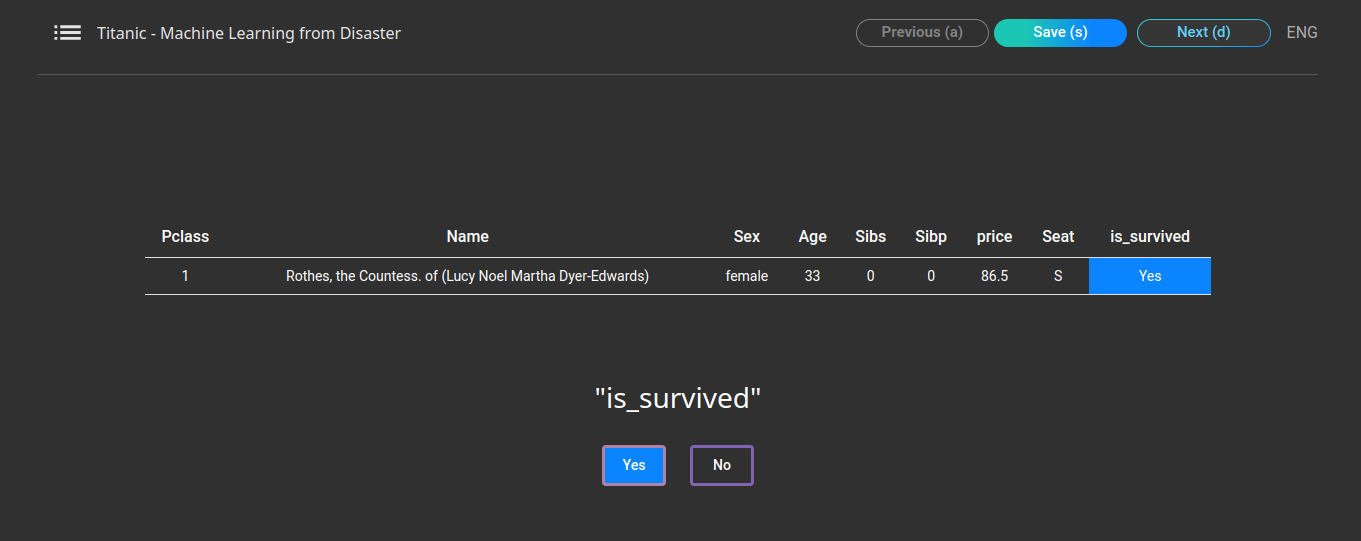
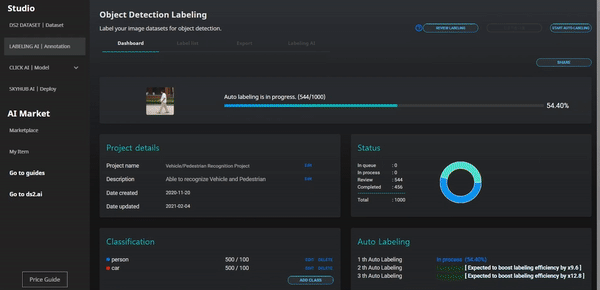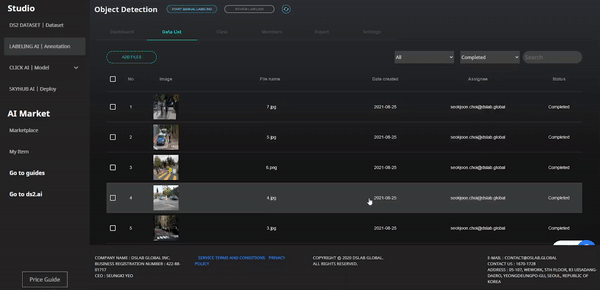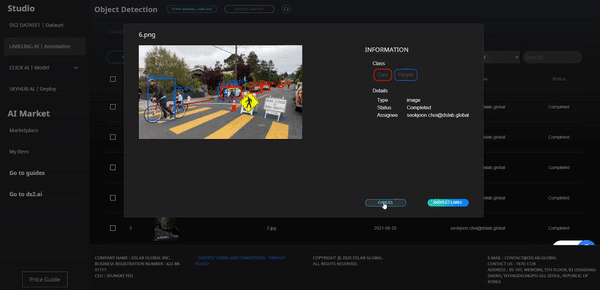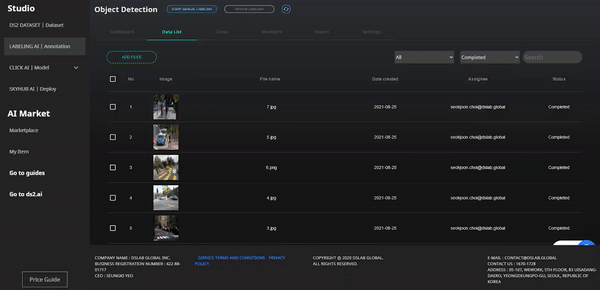
Supports training data labeling tools needed to create artificial intelligence models. After clicking Labeling on the top menu, upload the dataset, and you can start labeling by selecting the desired function between manual labeling and auto-labeling tool. (Labeling tool type: Tablur(Classification, Regression), Text, Image, Object Detection)
One of the powerful features of DS2.ai is the manual setting function that can easily set up learning under various conditions to derive an optimal artificial intelligence model.
pip install ds2aiAfter completing the installation of the ds2ai Python library, you can start learning using the example below.
import ds2ai
ds2 = ds2ai.DS2("your-app-code")
project = ds2.train(
"BankMarketing.csv",
option="custom",
training_method="normal",
value_for_predict="is_charge",
algorithm="keras_ann",
hyper_params={
"layer_width": [20,3,5],
"layer_deep": [3],
"epochs": [10],
"loss_function": ["mean_squared_error"],
"optimizer": [
{
"clipvalue": 0.5,
"learning_rate": 0.001,
"beta_1": 0.9,
"beta_2": 0.9999,
"epsilon": None,
"decay": 0,
"amsgrad": False,
"function_name": "Adam"
}
],
"activation": ["relu"],
"batch_size": [32],
"output_activation": ["relu"]
}
)You can check the app code by clicking the user name in the upper right corner. You can start learning with the code above after putting this app code as shown below.
ds2 = ds2ai.DS2("Your App code")After the code is executed, the ability to predict or deploy the job situation and the trained model is available in ds2.ai as-is. For more information on how to use, refer to "SDK | PYTHON" in the left menu.
After completing the installation, access to http://localhost:13002/skyhubredoc to check the API information.

You can use all DS2 functions through API and Python SDK.
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}@misc{grosman2021xlsr53-large-english,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {E}nglish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english}},
year={2021}
}@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@misc{li2021trocr,
title={TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models},
author={Minghao Li and Tengchao Lv and Lei Cui and Yijuan Lu and Dinei Florencio and Cha Zhang and Zhoujun Li and Furu Wei},
year={2021},
eprint={2109.10282},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@article{DBLP:journals/corr/abs-1910-13461, author = {Mike Lewis and Yinhan Liu and Naman Goyal and Marjan Ghazvininejad and Abdelrahman Mohamed and Omer Levy and Veselin Stoyanov and Luke Zettlemoyer}, title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension}, journal = {CoRR}, volume = {abs/1910.13461}, year = {2019}, url = {http://arxiv.org/abs/1910.13461}, eprinttype = {arXiv}, eprint = {1910.13461}, timestamp = {Thu, 31 Oct 2019 14:02:26 +0100}, biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib}, bibsource = {dblp computer science bibliography, https://dblp.org} }@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```bibtext
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}Each file included in this repository is licensed under the Apache License 2.0 BY License.
This project exists thanks to all the people who contribute.
Please read the contribution guidelines before submitting a pull request.
