



The fastest compression and decompression in the browser.
Using NPM
npm i wasm-flate
Using WAPM
wapm install drbh/flate
Or use it in you HTML page with the precompiled CDN version
<script src="https://unpkg.com/wasm-flate@0.1.11-alpha/dist/bootstrap.js"></script>check out the examples for code to decompress data in Python, Node and Go on the server side
Docs - get API reference and flate functions.
Examples - Examples compressing in browser, sending to node server and decompressing... really fast!
Test pako vs wasm-flate in your browsers here
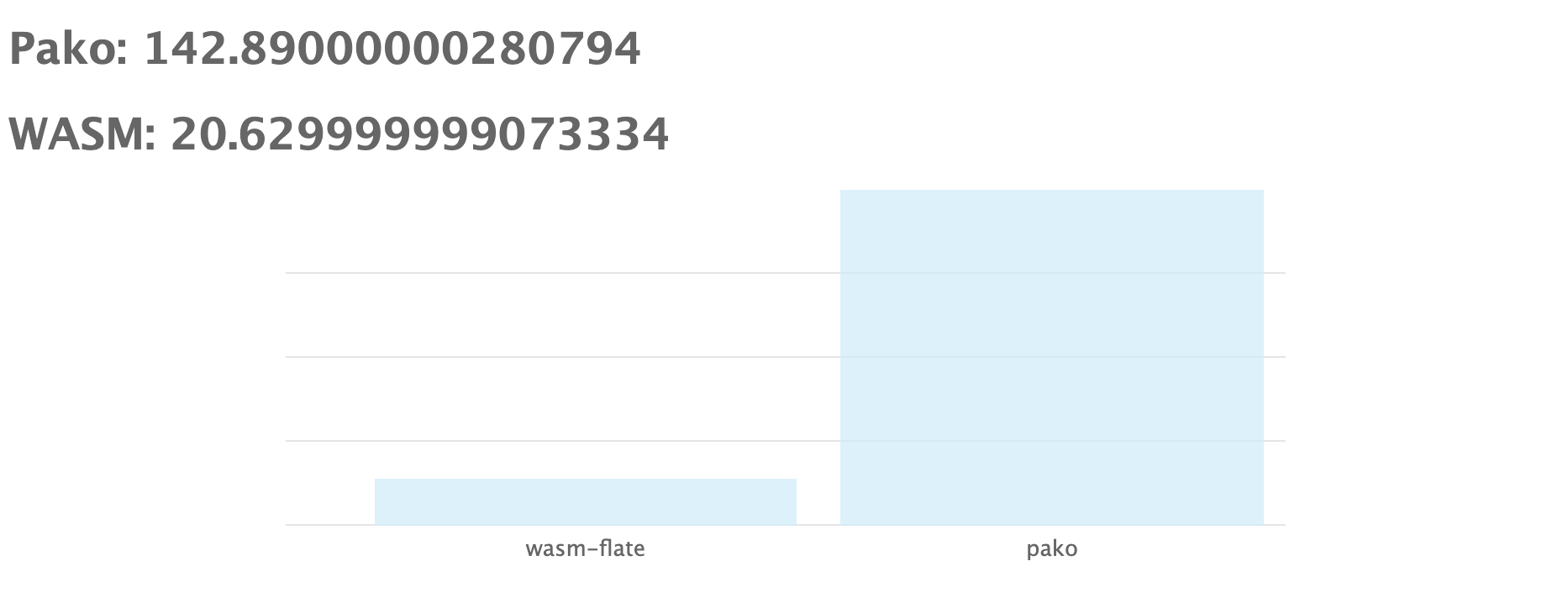
In Chrome on my MacBook Pro, we see that pako takes about 143 ms where wasm-flate only takes about 21 ms. This is 6.8x faster.
- Uses WASM
- As fast as C or Rust implementation
- Works in all browsers
- GZIP supported
- ZLIB supported
- DELFATE supported
- Shipping compressed data from server and decompress in browser
- Shipping compressed data to server by compressing in browser
- Better UX for mobile (fast decompress - slow data fetch)
- Better UX for people with sparse networks
- Less resource use on server side
- Decreased storage need
- Leveraging growing WASM ecosystem
This package allows you to quickly compress and decompress data in the browser. The process is simple and optmized to execute as fast as your browser can run.
Pass a string or Uint8Array to the compression function you choose. The contents will be compressed and encoded to base64. The returned value will be a base64 encoded string.
Pass a base64 string of the compressed data and it will return a base64 decompressed value.
var flate = require('wasm-flate');
var data = "THIS IS EXAMPLE DATA TO COMPRESS"
var compressed_data = flate.zlib_encode(data)
var original_data = flate.zlib_decode(compressed_data)This will read in the string as a u8array, compress, decompress and compare the output with the original value. This show cases all the main uses of wasm-flate
var flate = require('wasm-flate');
var data = new Uint8Array( Buffer.from('wasm-flate is awesome!') );
var comp = flate.deflate_encode_raw(data)
var decomp = flate.deflate_decode_raw(comp)
JSON.stringify(data) === JSON.stringify(decomp) Here we can see how to compress data as a string, and it will return a base64 encoded compressed value.
var data = "THIS IS EXAMPLE DATA TO COMPRESS"
var compressed_data = flate.zlib_encode(data)
// this data is zlib compressed and base64 encodedvar data = "THIS IS EXAMPLE DATA TO COMPRESS"
var compressed_data = flate.gzip_encode(data)
// this data is gzip compressed and base64 encodedvar data = "THIS IS EXAMPLE DATA TO COMPRESS"
var compressed_data = flate.deflate_encode(data)
// this data is deflate compressed and base64 encodedvar original_data = flate.zlib_decode("eNrtlEtOAzEMhvc9RTXrLpw4jmMu0EMgFk7GQQjRSjCgSlXvThgG1KpqeUgskOpN/Ppt61tkO5vPu14H7a7m2+a3aHjU3p5afD3G8yk/1vRh/bwalja0cuco+kARE/lucdRz92JjEzgiiZEAE0y23337Pgs2xbhCzOo5o5GnUvpamrSYSotbrooztQPxtAQ2Kk6sFvbcjvK+AHt1JMFqnzU5TqoYoU/76mF9b6vlx36DzOK5BK0eOVLJ5NAFBQPyTiUGqmBejyd8HgHftG6asFt8QVgkCgglCKcBMzI7hCRB4t/xdQYphkwxclOElBO7LD2IQ8SqVjBgqLH+N77nuPoLzx/zxOTPMqWAGC5cf/sP4Gm2Cbj9ANzYBrzwPeQ7vjezN2/3Cpfxnx4=")The folowing output is some compressed JSON of ECR20 tokens traded on a DEX (the data used is arbitrary!)
{
"data": {
"trades": [
{
"amountGet": "15624563852",
"amountGive": "10155966503800000000",
"get": "0xce7f06ba27b3e525ccdfc559cea9e523e5f91eae",
"give": "0xa919efc72756222c072a1594efdba8178aa360d8",
"tokenGet": "0xe0b7927c4af23765cb51314a0e0521a9645f0e2a",
"tokenGive": "0x0000000000000000000000000000000000000000"
}
], "..."
}We can prove if sending compressed data is worth the incurred computational time by performing a simple calculation.
If the time to send a file is greater then the time to compress plus the time to send and the time to decompress then we should opt for the second method.
This can be thought of as the following psudeo equation.
time to send > ( time to compress + time to send compressed + time to decompress )
How do we know the time to compress and the time to send in relation to a specific file on a specific network?
Well we can estimate for now - and then run benchmarks to evulate our theory.
Taking file size and network speed into account we can rewrite the above formula like:
( file size / network speed ) > (
( file size / compress speed ) +
( compressed file size / network speed ) +
( file size / decompression speed )
)
We can simpilfy our equation by attesting that we can compress and decompress at the same speed (they're roughtly equal). We also have to guess the compressed file size relative to it's original size and add a variable to evaluate that.
Next we port these psuedo equations into Python code and make for a simple calculator - this will tell us how many seconds we'll save on a specific file sent over a specific network. We will need to input the size of file to send in MBs, the compression ratio to full size, the compression speed in MB/s and the network speed in MB/s not Mbps.
We'll randomly assign the file to 10 MBs, we assume we can compress to 40% of the original size, we expect compression at 32 MB/s and we'll take the global internet speed average of 5.6 Mbps which is 0.7 MB/s ( MB/s == Mbps/8.0 ).
We use 32 MB/s for the algo speed - but it is actually much much faster - at closer to 90 MBs based on experience and quoted in this paper
f = 10 # size of file to send in MBs
cr = 0.40 # compression ratio to full size
cds = 32.0 # MB/s of DEFLATE algo
ns = 0.7 # Network MB/s == (Mbps/8.0)
time_saved = ( f / ns ) - ( ( (cr * f) / ns ) + ( 2 * ( f / cds ) ) )
size_saved = f - ( f * cr )
print( "time saved: %s secs\nsize saved: %s MBs" % ( round( time_saved, 1 ), size_saved ) )
### OUTPUT
## time saved: 7.9 secs
## size saved: 6.0 MBsWe can see that even in our exaggerated example where we underestimate how fast and how small we can compress a file we still save signifcant time on 10 MB/s. Remember this is based on the global internet speed average which is much lower then many countries - for instance South Koreas average is 27 Mbps or 3.375 MB/s
f = 10 # size of file to send in MBs
cr = 0.40 # compression ratio to full size
cds = 32.0 # MB/s of DEFLATE algo
ns = 3.375 # Network MB/s == (Mbps/8.0)
time_saved = ( f / ns ) - ( ( (cr * f) / ns ) + ( 2 * ( f / cds ) ) )
size_saved = f - ( f * cr )
print( "time saved: %s secs\nsize saved: %s MBs" % ( round( time_saved, 1 ), size_saved ) )
### OUTPUT
## time saved: 1.2 secs
## size saved: 6.0 MBsEven with those inputs we save 1.2 seconds and 6 MBs of data! 🙌
In short it is likely UX enchancing to compress data and decompress versus sending large files. In the following benchmarks we'll see why using wasm-flate is the fastest and most efficent way to compress on both the server and client sides!
- Compile compression to WASM
- Build useful functions for compression
- Compile useful functions to WASM
- Publish NPM package of WASM files and JS shim
- Add new functions for u8Array support
- Add basic API docs
- Write short medium article
- Compare with Native JS example
- Add node server side example
- Add Python server side example
- Make logo for lib based on WASM colorway
- Deploy to WAPM
- Add Golang example
- Add benchmarking suite
- Deploy multi file example
- Release solid roadmap
- Releae update schedule
- Find partner for case study
In order to build the wasm files with Rust, you'll need to clone the repo and run wasm-pack with nodejs as the target. This will create a set of files in pkg that can be used as a node module.
git clone https://github.com/drbh/wasm-flate.git
cd wasm-flate
wasm-pack build --target nodejs
You should have the following new files
pkg/
├── LICENSE-APACHE
├── LICENSE-MIT
├── README.md
├── wasm-flate.d.ts
├── wasm-flate.js
├── wasm-flate_bg.d.ts
├── wasm-flate_bg.js
├── wasm-flate_bg.wasm
└── package.json
If you found wasm-flate useful feel free to buy me a beer 🍺 or two 😀
BTC - 3QVK6D5QCZDSyLzFL3ZbELokyuSprRQQZF