
 |
|---|
|
| |
| Sanjeevi | 12/19/19 | .NET |
|---|
|
Microsoft Interview:
Here is a general overview of what you should expect during the interviews:
- General system architecture : Ability to walk through components of an application and describe the technologies and architectural patterns that should be used.
- Class design : Ability to discuss object oriented concepts and SOLID principles, applying them to design problems.
- SQL table design and performance basics : Ability to define tables to store data and discuss performance characteristics.
- Coding : Coding of basic algorithms in the language of your choice, and the ability to modify it based on changing requirements from the interviewer.
- Unit testing : Discuss your approach to testing the work you do and/or problems covered during the interview.
- Q+A : The interviewers will normally give you a chance to ask them some questions, so I suggest preparing a few.
- .NET:
NET is an integral part of many applications running on Windows and provides common functionality for those applications to run. This download is for people who need .NET to run an application on their computer. For developers, the .NET Framework provides a comprehensive and consistent programming model for building applications that have visually stunning user experiences and seamless and secure communication.
2.How many languages .NET is supporting now?
When .NET was introduced it came with several languages.
C#,
COBOL
and
Perl, etc.
Response.Redirect basically redirects the user's browser to another page or site. The history of the user's browser is updated to reflect the new address as well. It also performs a trip back to the client where the client's browser is redirected to the new page.
Whereas, Server.Transfer transfers from one page to the other without making any round-trip back to the client's browser. The history does not get updated in the case of Server.Transfer.
| Class | Object |
|---|---|
| Class is the definition of an object | An object is an instance of a class. |
| It is a template of the object | A class does not become an object unless instantiated |
| It describes all the methods, properties, etc | An object is used to access all those properties from the class. |
what do you know about boxing and unboxing?
| Boxing | Unboxing |
|---|---|
| Implicit | Explicit |
| Converting a value type to the type object | Extracting the value type from the object |
| eg : obj myObject = i; | eg : i = (int)myObject; |
Differentiate between constants and read-only variables.
| Constants | Read-only Variables |
|---|---|
| Evaluated at compile time | Evaluated at run-time |
| Support only value type variables | They can hold the reference type variables |
| They are used when the value is not changing at compile time | Used when the actual value is unknown before the run-time |
| Cannot be initialized at the time of declaration or in a constructor | Can be initialized at the time of declaration or in a constructor |
From which base class all web Forms are inherited?
All web forms are inherited from page class.
What are the different types of constructors in c#?
Following are the types of constructors in C#:
-
Default Constructor
-
Parameterized constructor
-
Copy Constructor
-
public class Employee
-
{ -
**public** string firstName; -
**public** string lastName; -
**public** string position; -
**public** int salary; -
**public** Employee() -
{ -
} -
// Copy constructor. -
**public** Employee(Employee employee) -
{ -
firstName = employee.firstName; -
lastName = employee.lastName; -
position = employee.position; -
salary = employee.salary; -
} -
} -
Static Constructor
Characteristic of static constructor
- A static constructor does not take any access modifiers.
- A static constructor does not have a parameter.
- A static constructor is called automatically to initialize the class before the first instance is created or any static members are referenced.
- A static constructor cannot be called directly.
- The user has no control over when the static constructor is executed in the program.
- A typical use of static constructors is when the class is using a log file and the constructor is used to write entries to this file.
- A class can have only one static constructor.
- It can access only static members of a class.
- Private Constructor
A private constructor is a special instance constructor. It is generally used in classes that contain static members only. If a class has one or more private constructors and no public constructors, other classes (except nested classes) cannot create instances of this class. The use of private constructor is to serve singleton classes. A singleton class is one which limits the number of objects created to one. Using private constructor we can ensure that no more than one object can be created at a time
- One use of private constructor is when we have the only static member.
- It provides the implementation of singleton class pattern.
- Once we provide constructor (private/public/any) the compiler will not add the no parameter public constructor to any class.
use of static constructor. Why and when would we create a static constructor and is it possible to overload one?
No you can't overload it; a static constructor is useful for initializing any static fields associated with a type (or any other per-type operations) - useful in particular for reading required configuration data into readonly fields, etc.
It is run automatically by the runtime the first time it is needed (the exact rules there are complicated (see "beforefieldinit") and changed subtly between CLR2 and CLR4). Unless you abuse reflection, it is guaranteed to run at most once (even if two threads arrive at the same time).
#### List the events in the page life cycle.
Following are the events in the page life cycle:
- Page_PreInit
- Page_Init
- Page_InitComplete
- Page_PreLoad
- Page_Load
- Page_LoadComplete
- Page_PreRender
- Render
- What is the code to send an email from an ASP.NET application?
| 12345678 | mail message = new mail();message.From = "abc@gmail.com";message.To = "xyz@gmail.com";message.Subject = "Test";message.Body = "hello"; SmtpMail.SmtpServer = "localhost";SmtpMail.Send(message); |
|---|
What is cross-page posting?
Whenever we click on a submit button on a page, the data is stored on the same page. But if the data is stored on a different page, it is known as a cross-page posting.
Cross-page posting can be achieved by POSTBACKURL property which causes the postback.
FindControl method can be used to get the values that are posted on this page to which the page has been posted.
What are the different types of cookies in ASP.NET?
- **Session Cookie: ** It resides on the client machine for a single session until the user logs out.
- **Persistent Cookie: ** Resides on the user machine for a period specified for its expiry. It may be an hour, a month or never.
What is the difference between ExecuteScalar and ExecuteNonQuery?
| ExecuteScalar | ExecuteNonQuery |
|---|---|
| Returns the output value | Does not return any value |
| Used for fetching a single value | Used to execute insert and update statements |
| Does not return the number of affected rows | Returns the number of affected rows. |
What is the difference between a stack and a heap?
| Stack | Heap |
|---|---|
| Stored value type | Stored reference type |
| A stack is responsible for keeping track of each executing thread and its location. | The heap is responsible for keeping track of the more precise objects or data. |
IIS acts as a front end proxy to the backend Kestrel Console application that hosts the .NET based Kestrel Web server.

In this scenario, IIS uses a very low level and early pipeline AspNetCoreModule that intercepts all requests pointed at it (via a module mapping) and then forwards those requests to Kestrel on a different port. Requests come in on standard HTTP ports (80 and 443 for SSL) and IIS proxies the incoming requests to a different port that Kestrel is listening on.
By default the module configuration forwards all requests to Kestrel, but you have some very limited control over what gets routed to the module.
w3wp.exe process (there may be more than one for each application pool so you have find the right one which you can do by looking at the command line arguments in Process Explorer or Task Manager) and the dotnet.exe process
You can see that both w3wp.exe and dotnet.exe - which runs the Kestrel Web server process - are using the same NETWORK SERVICE account. Keep in mind that you may have multiple application pools, and multiple instances of .NET Core Application's running at the same time in which case each application pool and kestrel process will launch in their associated security context.

How to enable Attribute Routing?
Just add the method — "MapMvcAttributeRoutes()" to enable attribute routing as shown below
public static void RegisterRoutes(RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
//enabling attribute routing
routes.MapMvcAttributeRoutes();
//convention-based routing
routes.MapRoute
(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new { controller = "Customer", action = "GetCustomerList", id = UrlParameter.Optional }
);
}
What is routes.IgnoreRoute("{resource}.axd/{*pathInfo}")
.axd files don't exist physically. ASP.NET uses URLs with .axd extensions (ScriptResource.axd and WebResource.axd) internally, and they are handled by an HttpHandler.
Therefore, you should keep this rule, to prevent ASP.NET MVC from trying to handle the request instead of letting the dedicated HttpHandler do it.
9. Explain JSON Binding?
JavaScript Object Notation (JSON) binding support started from MVC3 onwards via the new JsonValueProviderFactory, which allows the action methods to accept and model-bind data in JSON format. This is useful in Ajax scenarios like client templates and data binding that need to post data back to the server.
Active Directory Federation Services (ADFS):
Active Directory Federation Services (ADFS) is a Single Sign-On (SSO) solution created by Microsoft. As a component of Windows Server operating systems, it provides users with authenticated access to applications that are not capable of using Integrated Windows Authentication (IWA) through Active Directory (AD).
Developed to provide flexibility, ADFS gives organizations the ability to control their employees' accounts while simplifying the user experience: employees only need to remember a single set of credentials to access multiple applications through SSO.
How does ADFS work?
ADFS manages authentication through a proxy service hosted between AD and the target application. It uses a Federated Trust, linking ADFS and the target application to grant access to users. This enables users to log onto the federated application through SSO without needing to authenticate their identity on application directly.
The authentication process generally follows these four steps:
- The user navigates to a URL provided by the ADFS service.
- The ADFS service then authenticates the user via the organization's AD service.
- Upon authenticating, the ADFS service then provides the user with an authentication claim.
- The user's browser then forwards this claim to the target application, which either grants or denies access based on the Federated Trust service created.
A shared access signature (SAS) provides secure delegated access to resources in your storage account without compromising the security of your data. With a SAS, you have granular control over how a client can access your data.
Azure Storage supports three types of shared access signatures:
- User delegation SAS (preview). A user delegation SAS is secured with Azure Active Directory (Azure AD) credentials and also by the permissions specified for the SAS. A user delegation SAS applies to Blob storage only.
For more information about the user delegation SAS, see Create a user delegation SAS (REST API).
- Service SAS. A service SAS is secured with the storage account key. A service SAS delegates access to a resource in only one of the Azure Storage services: Blob storage, Queue storage, Table storage, or Azure Files.
For more information about the service SAS, see Create a service SAS (REST API).
- Account SAS. An account SAS is secured with the storage account key. An account SAS delegates access to resources in one or more of the storage services. All of the operations available via a service or user delegation SAS are also available via an account SAS. Additionally, with the account SAS, you can delegate access to operations that apply at the level of the service, such as Get/Set Service Properties and Get Service Stats operations. You can also delegate access to read, write, and delete operations on blob containers, tables, queues, and file shares that are not permitted with a service SAS.
3. What is an IL?
Intermediate Language is also known as MSIL (Microsoft Intermediate Language) or CIL (Common Intermediate Language). All .NET source code is compiled to IL. IL is then converted to machine code at the point where the software is installed, or at run-time by a Just-In-Time (JIT) compiler.
4. What is code access security (CAS)?
Code access security (CAS) is part of the .NET security model that prevents unauthorized access of resources and operations, and restricts the code to perform particular tasks.
5. What is Difference between NameSpace and Assembly?
Assembly is physical grouping of logical units, Namespace, logically groups classes.
Namespace can span multiple assembly.
6. Mention the execution process for managed code.
A)Choosing a language compiler
B) Compiling the code to MSIL
C) Compiling MSIL to native code
D) Executing the code.
7. What is Microsoft Intermediate Language (MSIL)?
The .NET Framework is shipped with compilers of all .NET programming languages to develop programs. There are separate compilers for the Visual Basic, C#, and Visual C++ programming languages in .NET Framework. Each .NET compiler produces an intermediate code after compiling the source code. The intermediate code is common for all languages and is understandable only to .NET environment. This intermediate code is known as MSIL.
8. What is managed extensibility framework?
Managed extensibility framework (MEF) is a new library that is introduced as a part of .NET 4.0 and Silverlight 4. It helps in extending your application by providing greater reuse of applications and components. MEF provides a way for host application to consume external extensions without any configuration requirement.
9. Which method do you use to enforce garbage collection in .NET?
The System.GC.Collect() method.
10. What is the difference between int and int32.
There is no difference between int and int32. System.Int32 is a .NET Class and int is an alias name for System.Int32.
11. What are tuples?
Tuple is a fixed-size collection that can have elements of either same or different data types. Similar to arrays, a user must have to specify the size of a tuple at the time of declaration. Tuples are allowed to hold up from 1 to 8 elements and if there are more than 8 elements, then the 8th element can be defined as another tuple. Tuples can be specified as parameter or return type of a method.
12. What is the full form of ADO?
The full form of ADO is ActiveX Data Object.
**13. What are the two fundamental objects in ** ADO.NET?
DataReader and DataSet are the two fundamental objects in ADO.NET
14. What is the meaning of object pooling?
Object pooling is a concept of storing a pool (group) of objects in memory that can be reused later as needed. Whenever, a new object is required to create, an object from the pool can be allocated for this request; thereby, minimizing the object creation. A pool can also refer to a group of connections and threads. Pooling, therefore, helps in minimizing the use of system resources, improves system scalability, and performance.
15. Mention the namespace that is used to include .NET Data Provider for SQL server in .NET code.
The System.Data.SqlClient namespace.
16. Which architecture does Datasets follow?
Datasets follow the disconnected data architecture.
**17. What is the role of the DataSet object in ** ADO.NET?
One of the major component of ADO.NET is the DataSet object, which always remains disconnected from the database and reduces the load on the database.
18. Which property is used to check whether a DataReader is closed or opened?
The IsClosed property is used to check whether a DataReader is closed or opened. This property returns a true value if a Data Reader is closed, otherwise a false value is returned.
19. Name the method that needs to be invoked on the DataAdapter control to fill the generated DataSet with data?
The Fill() method is used to fill the dataset with data.
20. What are the pre-requisites for connection pooling?
There must be multiple processes to share the same connection describing the same parameters and security settings. The connection string must be identical.
21. Which adapter should you use, if you want to get the data from an Access database?
OleDbDataAdapter is used to get the data from an Access database.
22. What are different types of authentication techniques that are used in connection strings to connect .NET applications with Microsoft SQL Server?
The Windows Authentication option
The SQL Server Authentication option
23. What are the parameters that control most of connection pooling behaviors?
Connect Timeout
Max Pool Size
Min Pool Size
Pooling
24. What is AutoPostBack?
If you want a control to postback automatically when an event is raised, you need to set the AutoPostBack property of the control to True.
25. What is the function of the ViewState property?
Automatic memory management is made possible by Garbage Collection in .NET Framework. When a class object is created at runtime, certain memory space is allocated to it in the heap memory. However, after all the actions related to the object are completed in the program, the memory space allocated to it is a waste as it cannot be used. In this case, garbage collection is very useful as it automatically releases the memory space after it is no longer required.
Garbage collection will always work on Managed Heap and internally it has an Engine which is known as the Optimization Engine.
Garbage Collection occurs if at least one of multiple conditions is satisfied. These conditions are given as follows:
If the system has low physical memory, then garbage collection is necessary.
- If the memory allocated to various objects in the heap memory exceeds a pre-set threshold, then garbage collection occurs.
- If the GC.Collect method is called, then garbage collection occurs. However, this method is only called under unusual situations as normally garbage collector runs automatically.
There are mainly 3 phases in garbage collection. Details about these are given as follows:
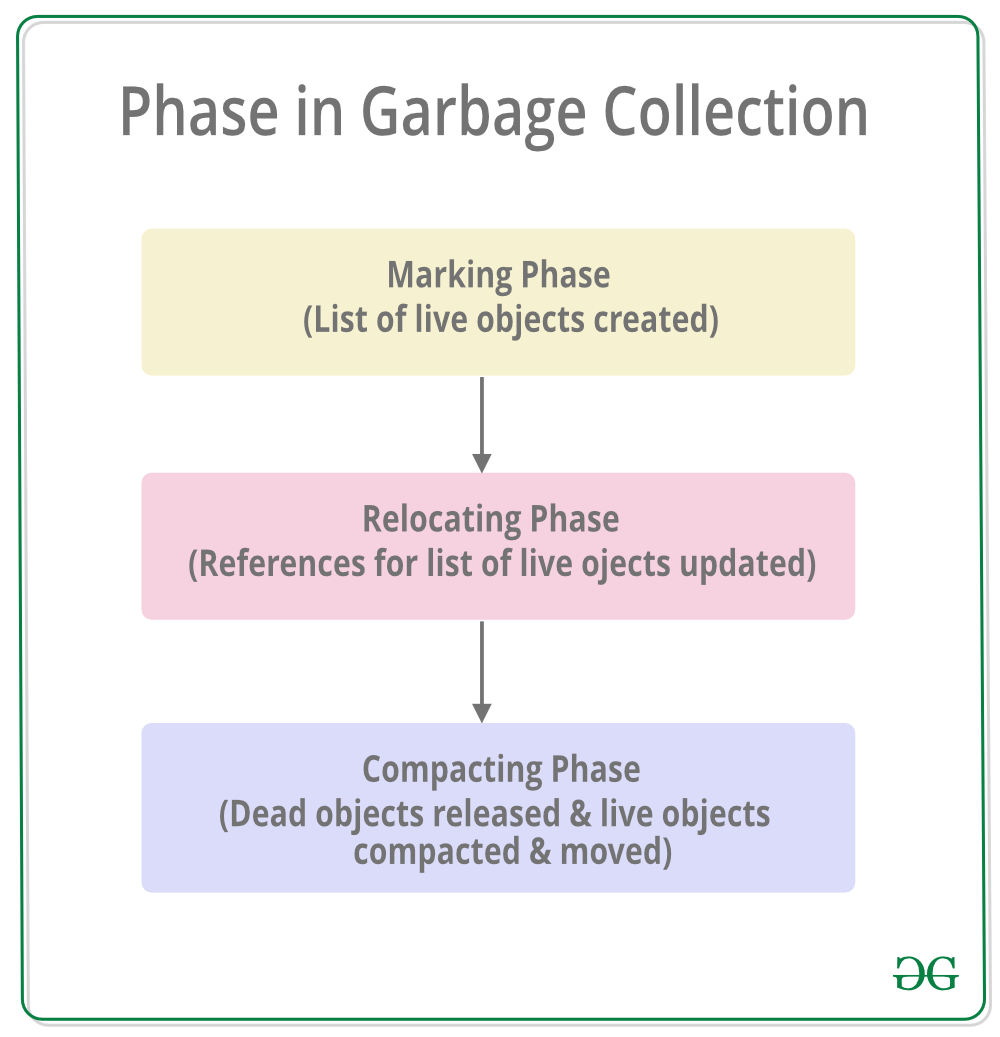
- Marking Phase: A list of all the live objects is created during the marking phase. This is done by following the references from all the root objects. All of the objects that are not on the list of live objects are potentially deleted from the heap memory.
- Relocating Phase: The references of all the objects that were on the list of all the live objects are updated in the relocating phase so that they point to the new location where the objects will be relocated to in the compacting phase.
- Compacting Phase: The heap gets compacted in the compacting phase as the space occupied by the dead objects is released and the live objects remaining are moved. All the live objects that remain after the garbage collection are moved towards the older end of the heap memory in their original order.
The heap memory is organized into 3 generations so that various objects with different lifetimes can be handled appropriately during garbage collection. The memory to each Generation will be given by the Common Language Runtime(CLR) depending on the project size. Internally, Optimization Engine will call the Collection Means Method to select which objects will go into Gneration 1 or Generation 2.

- **Generation 0 : ** All the short-lived objects such as temporary variables are contained in the generation 0 of the heap memory. All the newly allocated objects are also generation 0 objects implicitly unless they are large objects. In general, the frequency of garbage collection is the highest in generation 0.
- **Generation 1 : ** If space occupied by some generation 0 objects that are not released in a garbage collection run, then these objects get moved to generation 1. The objects in this generation are a sort of buffer between the short-lived objects in generation 0 and the long-lived objects in generation 2.
- **Generation 2 : ** If space occupied by some generation 1 objects that are not released in the next garbage collection run, then these objects get moved to generation 2. The objects in generation 2 are long lived such as static objects as they remain in the heap memory for the whole process duration.
**Note: ** Garbage collection of a generation implies the garbage collection of all its younger generations. This means that all the objects in that particular generation and its younger generations are released. Because of this reason, the garbage collection of generation 2 is called a full garbage collection as all the objects in the heap memory are.released. Also, the memory allocated to the Generation 2 will be greater than Generation 1's memory and similarly the memory of Generation 1 will be greater than Generation 0's memory( Generation 2 > Generation 1 > Generation 0 ).
Q #1) What is .Net framework?
Ans: It is a platform for building various applications on windows. It has a list of inbuilt functionalities in the form of class, library, and APIs which are used to build, deploy and run web services and different applications. It supports different languages such as C#, VB .Net, Cobol, Perl, etc.
This framework supports object-oriented programming model.
Q #2) What are the important components of .Net?
Ans: The components of .Net are Common language run-time, .Net Class library, Application domain, Common Type System, .Net framework, Profiling, etc. However, the two important components are Class library and Common Language Runtime.
CLR provides building blocks for a wide variety of applications. The class library consists of a set of classes that are used to access the common functionality. The functionality can be shared among different applications.
Q #3) What is CTS?
Ans: CTS stands for Common Type System. It has a set of rules which state how a data type should be declared, defined and used in the program. It describes the data types that are to be used in the application.
We can design our own classes and values by following the rules that are present in the CTS. The rules are made so that the data type declared using a programming language is callable by an application that is developed using a different language.
Q #4) What is CLR?
Ans: CLR stands for Common Language Runtime. It is one of the most important components of .Net framework. It provides building blocks for many applications.
An application built using C# gets compiled by its own compiler and is converted into an Intermediate language. This is then targeted to CLR. CLR does various operations like memory management, Security checks, assemblies to be loaded and thread management. It provides a secure execution environment for applications.
Q #5) What is CLS?
Ans: CLS stands for Common Language Specification. With the rules mentioned under CLS, the developers are made to use the components that are inter-language compatible. They are reusable across all the .Net Compliant languages.
Q #6) What is JIT?
Ans: JIT stands for Just In Time. JIT is a compiler that converts Intermediate Language to a Native code.
The code is converted into Native language during execution. Native code is nothing but hardware specifications that can be read by the CPU. The native code can be stored so that it is accessible for subsequent calls.
Q #7) What is MSIL?
Ans: MSIL stands for Microsoft Intermediate Language.
MSIL provides instructions for calling methods, initializing and storing values, operations such as memory handling, exception handling and so on. All .Net codes are first compiled to IL.
Q #8) What is meant by Managed and Unmanaged code?
Ans: The code that is managed by the CLR is called Managed code. This code runs inside the CLR. Hence, it is necessary to install the .Net framework in order to execute the managed code. CLR manages the memory through garbage collection and also uses the other features like CAS and CTS for efficient management of the code.
Unmanaged code is any code that does not depend on CLR for execution. It means it is developed by any other language independent of .Net framework. It uses its own runtime environment for compiling and execution.
Though it is not running inside the CLR, the unmanaged code will work properly if all the other parameters are correctly followed.
Q #9) How is a Managed code executed?
Ans: Following steps are followed while executing a Managed code:
- Choosing a language compiler depending on the language in which the code is written.
- Converting the above code into Intermediate Language by its own compiler.
- The IL is then targeted to CLR which converts the code into native code with the help of JIT.
- Execution of Native code.
Q #10) What is ASP.Net?
Ans: ASP .Net is a part of .Net technology and it comprises of CLR too. It is an open source server-side technology that enables the programmers to build powerful web services, websites and web applications.
ASP stands for Active Server Pages.
Q #11) Explain State management in ASP .Net.
Ans: State Management means maintaining the state of the object. The object here refers to a web page/control.
There are two types of State management, Client Side, and Server side.
Client Side – Storing the information in the Page or Client's System. They are reusable, simple objects.
Server Side – Storing the information on the Server. It is easier to maintain the information on the Server rather than depending on the client for preserving the state.
Q #12) What is an Assembly? What are the different types of Assemblies?
Ans: An Assembly is a collection of logical units. Logical units refer to the types and resources which are required to build an application and deploy them using the .Net framework. The CLR uses this information for type implementations. Basically, Assembly is a collection of Exe and Dlls. It is portable and executable.
There are two types of Assemblies, Private and Shared.
Private Assembly , as the name itself suggests, it is accessible only to the application. It is installed in the installation directory of the Application.
A Shared assembly can be shared by multiple applications. It is installed in the GAC.
Q #13) Explain the different parts of an Assembly.
Ans: The different parts of an Assembly are:
- Manifest – It contains the information about the version of an assembly. It is also called as assembly metadata.
- Type Metadata – Binary information of the program.
- MSIL – Microsoft Intermediate Language code.
- Resources – List of related files.
Q #14) What is an EXE and a DLL?
Ans: Exe and DLLs are Assembly executable modules.
Exe is an executable file. This runs the application for which it is designed. An Exe is generated when we build an application. Hence the assemblies are loaded directly when we run an Exe. However, an Exe cannot be shared with the other applications.
DLL stands for Dynamic Link Library. It is a library that consists of code which needs be hidden. The code is encapsulated inside this library. An Application can consist of many DLLs. These can be shared with the other applications as well.
Other applications which need to share this DLL need not worry about the code intricacies as long as it is able to call the function on this DLL.
Q #15) What is Caching?
Ans: Caching means storing data temporarily in the memory so that the application can access the data from the cache instead of looking for its original location. This increases the performance of the application and its speed. System.Runtime.Caching namespace is used for Caching information in .Net.
Given below are the 3 different types of Caching:
- Page Caching
- Data Caching
- Fragment Caching
Q #16) What is MVC?
Ans: MVC stands for Model View Controller. It is an architectural model for building the .Net applications.
Models – Model objects store and retrieve data from the database for an application. They are usually the logical parts of an application that is implemented by the application's data domain.
View – These are the components that display the view of the application in the form of UI. The view gets the information from the model objects for their display. They have components like buttons, drop boxes, combo box, etc.
Controllers – They handle the User Interactions. They are responsible for responding to the user inputs, work with the model objects, and pick a view to be rendered to the user.
Q #17) What is the difference between Function and Stored procedure?
Ans:
Stored Procedure:
- A Stored procedure is always used to perform a specific task.
- It can return zero, one or more value.
- It can have both Input and Output Parameters.
- Exception handling can be done using a try-catch block.
- A function can be called from a Procedure.
Functions:
- Functions must return a single value.
- It can only have the input parameter.
- Exception handling cannot be done using a try-catch block.
- A Stored procedure cannot be called from a function.
Q #18) Explain CAS (Code Access Security).
Ans: .Net provides a security model that prevents unauthorized access to resources. CAS is a part of that security model. CAS is present in the CLR. It enables the users to set permissions at a granular level for the code.
CLR then executes the code depending on the available permissions. CAS can be applied only to the managed code. Unmanaged code runs without CAS. If CAS is used on assemblies, then the assembly is treated as partially trusted. Such assemblies must undergo checks every time when it tries to access a resource.
The different components of CAS are Code group, Permissions, and Evidence.
Evidence – To decide what permissions to give, the CAS and CLR depend on the specified evidence by the assembly. The examination of the assembly provides details about the different pieces of evidence. Some common evidence include Zone, URL, Site, Hash Value, Publisher and Application directory.
Code Group – Depending on the evidence, codes are put into different groups. Each group has specific conditions attached to it. Any assembly that matches those condition is put into that group.
Permissions – Each code group can perform only specific actions. They are called Permissions. When CLR loads an assembly, it matches them to one of the code groups and identifies what actions those assemblies can do. Some of the Permissions include Full Trust, Everything, Nothing, Execution, Skip Verification, and the Internet.
Q #19) What is GAC?
Ans: GAC stands for ** Global Assembly Cache**. Whenever CLR gets installed on the machine, GAC comes as a part of it. GAC specifically stores those assemblies which will be shared by many applications. A Developer tool called Gacutil.exe is used to add any file to GAC.
Q #20) What is meant by Globalization and Localization?
Ans: Internationalization is the process of designing applications that support multiple languages. This is divided into Localization and Globalization.
Globalization is nothing but developing applications to support different languages. Existing applications can also be converted to support multiple cultures.
Whereas Localization means changing the already globalized app to cater to a specific culture or language Microsoft.Extensions.Localization is used for localizing the app content. Some of the other keywords that are used for Localization are IHtmlLocalizer, IStringLocalizer, IViewLocalizer and so on
Q #21) What is a Garbage Collector?
Ans: Garbage collection is a feature of .Net to free the unused code objects in the memory.
The memory heap is divided into three generations. Generation 0, Generation 1 and Generation 2.
Generation 0 – This is used to store short-lived objects. Garbage Collection happens frequently in this Generation.
Generation 1 – This is for medium-lived objects. Usually, the objects that get moved from generation 0 are stored in this.
Generation 2 – This is for long-lived objects.
Collecting a Generation refers to collecting the objects in that generation and all its younger generations. Garbage collection of Generation 2 means full garbage collection, it collects all the objects in Generation 2 as well as Generation 1 and Generation 0.
During the Garbage collection process, as the first phase, list of live objects are identified. In the second phase, references are updated for those objects which will be compacted. And in the last phase, the space occupied by dead objects are reclaimed. The remaining objects are moved to an older segment.
What is BCL?
The Base Class Library is a Common Language Infrastructure. BCL encapsulates a large number of common functionalities which are available to all the .NET Languages. BCL makes the developers life much simpler while implementing various functionalities like I/O operations, Data access operations, graphical user interfaces and interfaces to various hardware devices by encapsulating them into various namespaces and classes. It also encapsulates the services which are required by the latest real world applications. .NET Framework applications, components and the controls are built on BCL.
Explain Different Types of Constructors in C#?
There are four different types of constructors you can write in a class -
-
Default Constructor
-
Parameterized Constructor
-
Copy Constructor
-
Static Constructor
What are functional and non-functional requirements?
Functional requirements defines the behavior of a system whereas non-functional requirements specify how the system should behave; in other words they specify the quality requirements and judge the behavior of a system.
E.g.
Functional - Display a chart which shows the maximum number of products sold in a region.
Non-functional – The data presented in the chart must be updated every 5 minutes.
What is a stack? What is a heap? Give the differences between the two?
Stack is a place in the memory where value types are stored. Heap is a place in the memory where the reference types are stored.
What is instrumentation?
It is the ability to monitor an application so that information about the application's progress, performance and status can be captured and reported.
What is object role modeling (ORM) ?
It is a logical model for designing and querying database models. There are various ORM tools in the market like CaseTalk, Microsoft Visio for Enterprise Architects, Infagon etc.
What is a COM Callable Wrapper (CCW)?
CCW is a wrapper created by the common language runtime(CLR) that enables COM components to access .NET objects.
What is a Runtime Callable Wrapper (RCW)?
RCW is a wrapper created by the common language runtime(CLR) to enable .NET components to call COM components.
What is a digital signature?
A digital signature is an electronic signature used to verify/gurantee the identity of the individual who is sending the message.
What is Application Domain and how does it work?
Windows Operating Systems load a set of resources like .EXE, DLLs and allocate the memory for those resources in an area called as Process. Windows OS creates a separate and isolated area for each running application. Making separate isolation area for each application, makes the process more secure and stable. In case, one process fails, it does not affect the other process.
.NET applications, however, are not hosted like traditional applications by Windows Operating System. Under .NET, .EXEs are hosted under a process by logical partitioning which is known as "Application Domain". Now you can host multiple application domains under one single process.
What is MIME?
The definition of MIME or Multipurpose Internet Mail Extensions as stated in MSDN is "MIME is a standard that can be used to include content of various types in a single message. MIME extends the Simple Mail Transfer Protocol (SMTP) format of mail messages to include multiple content, both textual and non-textual. Parts of the message may be images, audio, or text in different character sets.
What are Cookies in ASP.NET?
Answer: Cookies are a State Management Technique that can store the values of control after a post-back. Cookies can store user-specific Information on the client's machine like when the user last visited your site. Cookies are also known by many names, such as HTTP Cookies, Browser Cookies, Web Cookies, Session Cookies and so on. Basically cookies are a small text file sent by the web server and saved by the Web Browser on the client's machine.
List of properties containing the HttpCookies Class:
- Domain: Using these properties we can set the domain of the cookie.
- Expires: This property sets the Expiration time of the cookies.
- **HasKeys: ** If the cookies have a subkey then it returns True.
- **Name: ** Contains the name of the Key.
- **Path: ** Contains the Virtual Path to be submitted with the Cookies.
- Secured: If the cookies are to be passed in a secure connection then it only returns True.
- **Value: ** Contains the value of the cookies.
Limitation of the Cookies
- The size of cookies is limited to 4096 bytes.
- A total of 20 cookies can be used in a single website.
Answer. Ajax stands for Asynchronous JavaScript and XML; in other words Ajax is the combination of various technologies such as a JavaScript, CSS, XHTML, DOM, etc.
AJAX allows web pages to be updated asynchronously by exchanging small amounts of data with the server behind the scenes. This means that it is possible to update parts of a web page, without reloading the entire page.
Web applications running within Microsoft's Internet Information Services (IIS) utilize what is known as IIS worker processes. These worker processes run as w3wp.exe, and there can be multiple per computer. It is possible to run IIS on a Windows desktop or Windows server, although it is usually only seen on Microsoft Windows Servers configured as web servers.
Web applications on Windows Servers are configured via command line or Internet Information Systems (IIS) Manager. Within IIS you can set up websites and which application pools they are assigned. Multiple websites can be assigned to a single IIS application pool.
IIS application pools also provide a bunch of advanced settings. These impact the behavior of w3wp and your IIS worker process. Including things like what Windows user account it runs as, auto restarting of the process, auto shutdown, and more. It is also possible for one IIS application pool to create multiple IIS worker processes in what is called a web garden.
There is one key thing you need to know about IIS application pools that are a little confusing. Within the IIS management console, you can stop and start application pools. But, just because an IIS application pool is started, there may not be an IIS worker process (w3wp) running. IIS will not start the worker process until the first web request is received.
- Micro Services:
Microservices architecture style
A microservices architecture consists of a collection of small, autonomous services. Each service is self-contained and should implement a single business capability within a bounded context. A bounded context is a natural division within a business and provides an explicit boundary within which a domain model exists.

- Microservices are small, independent, and loosely coupled. A single small team of developers can write and maintain a service.
- Each service is a separate codebase, which can be managed by a small development team.
- Services can be deployed independently. A team can update an existing service without rebuilding and redeploying the entire application.
- Services are responsible for persisting their own data or external state. This differs from the traditional model, where a separate data layer handles data persistence.
- Services communicate with each other by using well-defined APIs. Internal implementation details of each service are hidden from other services.
- Supports polyglot programming. For example, services don't need to share the same technology stack, libraries, or frameworks.
Benefits:
Agility. Because microservices are deployed independently, it's easier to manage bug fixes and feature releases. You can update a service without redeploying the entire application, and roll back an update if something goes wrong. In many traditional applications, if a bug is found in one part of the application, it can block the entire release process. New features may be held up waiting for a bug fix to be integrated, tested, and published.
Small, focused teams. A microservice should be small enough that a single feature team can build, test, and deploy it. Small team sizes promote greater agility. Large teams tend be less productive, because communication is slower, management overhead goes up, and agility diminishes.
Small code base. In a monolithic application, there is a tendency over time for code dependencies to become tangled. Adding a new feature requires touching code in a lot of places. By not sharing code or data stores, a microservices architecture minimizes dependencies, and that makes it easier to add new features.
Mix of technologies. Teams can pick the technology that best fits their service, using a mix of technology stacks as appropriate.
Fault isolation. If an individual microservice becomes unavailable, it won't disrupt the entire application, as long as any upstream microservices are designed to handle faults correctly (for example, by implementing circuit breaking).
Scalability. Services can be scaled independently, letting you scale out subsystems that require more resources, without scaling out the entire application. Using an orchestrator such as Kubernetes or Service Fabric, you can pack a higher density of services onto a single host, which allows for more efficient utilization of resources.
Data isolation. It is much easier to perform schema updates, because only a single microservice is affected. In a monolithic application, schema updates can become very challenging, because different parts of the application may all touch the same data, making any alterations to the schema risky.
Challenges
The benefits of microservices don't come for free. Here are some of the challenges to consider before embarking on a microservices architecture.
Complexity. A microservices application has more moving parts than the equivalent monolithic application. Each service is simpler, but the entire system as a whole is more complex.
Development and testing. Writing a small service that relies on other dependent services requires a different approach than a writing a traditional monolithic or layered application. Existing tools are not always designed to work with service dependencies. Refactoring across service boundaries can be difficult. It is also challenging to test service dependencies, especially when the application is evolving quickly.
Lack of governance. The decentralized approach to building microservices has advantages, but it can also lead to problems. You may end up with so many different languages and frameworks that the application becomes hard to maintain. It may be useful to put some project-wide standards in place, without overly restricting teams' flexibility. This especially applies to cross-cutting functionality such as logging.
Network congestion and latency. The use of many small, granular services can result in more interservice communication. Also, if the chain of service dependencies gets too long (service A calls B, which calls C...), the additional latency can become a problem. You will need to design APIs carefully. Avoid overly chatty APIs, think about serialization formats, and look for places to use asynchronous communication patterns like queue-based load leveling.
Data integrity. With each microservice responsible for its own data persistence. As a result, data consistency can be a challenge. Embrace eventual consistency where possible.
Management. To be successful with microservices requires a mature DevOps culture. Correlated logging across services can be challenging. Typically, logging must correlate multiple service calls for a single user operation.
Versioning. Updates to a service must not break services that depend on it. Multiple services could be updated at any given time, so without careful design, you might have problems with backward or forward compatibility.
Skill set. Microservices are highly distributed systems. Carefully evaluate whether the team has the skills and experience to be successful.
Best practices
Model services around the business domain.
Decentralize everything. Individual teams are responsible for designing and building services. Avoid sharing code or data schemas.
Data storage should be private to the service that owns the data. Use the best storage for each service and data type.
Services communicate through well-designed APIs. Avoid leaking implementation details. APIs should model the domain, not the internal implementation of the service.
Avoid coupling between services. Causes of coupling include shared database schemas and rigid communication protocols.
Offload cross-cutting concerns, such as authentication and SSL termination, to the gateway.
Keep domain knowledge out of the gateway. The gateway should handle and route client requests without any knowledge of the business rules or domain logic. Otherwise, the gateway becomes a dependency and can cause coupling between services.
Services should have loose coupling and high functional cohesion. Functions that are likely to change together should be packaged and deployed together. If they reside in separate services, those services end up being tightly coupled, because a change in one service will require updating the other service. Overly chatty communication between two services may be a symptom of tight coupling and low cohesion.
Isolate failures. Use resiliency strategies to prevent failures within a service from cascading. See Resiliency patterns and Designing reliable applications.
Reliability patterns - Cloud Design Patterns | Microsoft Docs
Build microservices on Azure - Azure Architecture Center | Microsoft Docs
Principles of the reliability pillar - Azure Architecture Center | Microsoft Docs
What is a Microservices Architecture in a Nutshell?
Robert C. Martin coined the term single responsibility principle which states "gather together those things that change for the same reason, and separate those things that change for different reasons."
A microservices architecture takes this same approach and extends it to the loosely coupled services which can be developed, deployed, and maintained independently. Each of these services is responsible for discrete task and can communicate with other services through simple APIs to solve a larger complex business problem.
Key Benefits of a Microservices Architecture
As the constituent services are small, they can be built by one or more small teams from the beginning separated by service boundaries which make it easier to scale up the development effort if need be.
Once developed, these services can also be deployed independently of each other and hence its easy to identify hot services and scale them independent of whole application. Microservices also offer improved fault isolation whereby in the case of an error in one service the whole application doesn't necessarily stop functioning. When the error is fixed, it can be deployed only for the respective service instead of redeploying an entire application.
Another advantage which a microservices architecture brings to the table is making it easier to choose the technology stack (programming languages, databases, etc.) which is best suited for the required functionality (service) instead of being required to take a more standardized, one-size-fits-all approach.
The What, Why, and How of a Microservices Architecture | by Hashmap | HashmapInc | Medium
The Bulkhead pattern isolates elements of an application into pools so that if one fails, the others will continue to function. The pattern is coined Bulkhead because it resembles the sectioned partitions of a ship's hull. If the hull of a ship is compromised, only the damaged section fills with water, which prevents the ship from sinking.
The Circuit Breaker pattern wraps a protected function call in a circuit breaker object, which monitors for failures. Once a failure crosses the threshold, the circuit breaker trips, and all further calls to the circuit breaker return with an error, without the protected call being made at all for a certain configured timeout.
After the timeout expires some calls are allowed by circuit breaker to pass through, and if they succeed the circuit breaker resumes a normal state. For the period the circuit breaker has failed, users can be notified that a certain part of system is broken and the rest of the system can still be used.
Be aware that providing the required level of resiliency for an application can be a multi-dimensional challenge — take a look at Bilgin Ibryam's post for some great detail "It takes more than a Circuit Breaker to create a resilient application".
This solution has a number of benefits:
- Enables the continuous delivery and deployment of large, complex applications.
- Improved maintainability - each service is relatively small and so is easier to understand and change
- Better testability - services are smaller and faster to test
- Better deployability - services can be deployed independently
- It enables you to organize the development effort around multiple, autonomous teams. Each (so called two pizza) team owns and is responsible for one or more services. Each team can develop, test, deploy and scale their services independently of all of the other teams.
- Each microservice is relatively small:
- Easier for a developer to understand
- The IDE is faster making developers more productive
- The application starts faster, which makes developers more productive, and speeds up deployments
- Improved fault isolation. For example, if there is a memory leak in one service then only that service will be affected. The other services will continue to handle requests. In comparison, one misbehaving component of a monolithic architecture can bring down the entire system.
- Eliminates any long-term commitment to a technology stack. When developing a new service you can pick a new technology stack. Similarly, when making major changes to an existing service you can rewrite it using a new technology stack.
This solution has a number of drawbacks:
- Developers must deal with the additional complexity of creating a distributed system:
- Developers must implement the inter-service communication mechanism and deal with partial failure
- Implementing requests that span multiple services is more difficult
- Testing the interactions between services is more difficult
- Implementing requests that span multiple services requires careful coordination between the teams
- Developer tools/IDEs are oriented on building monolithic applications and don't provide explicit support for developing distributed applications.
- Deployment complexity. In production, there is also the operational complexity of deploying and managing a system comprised of many different services.
- Increased memory consumption. The microservice architecture replaces N monolithic application instances with NxM services instances. If each service runs in its own JVM (or equivalent), which is usually necessary to isolate the instances, then there is the overhead of M times as many JVM runtimes. Moreover, if each service runs on its own VM (e.g. EC2 instance), as is the case at Netflix, the overhead is even higher.
- Microservice architecture gives developers the freedom to independently develop and deploy services
- A microservice can be developed by a fairly small team
- Code for different services can be written in different languages (though many practitioners discourage it)
- Easy integration and automatic deployment (using open-source continuous integration tools such as Jenkins, Hudson, etc.)
- Easy to understand and modify for developers, thus can help a new team member become productive quickly
- The developers can make use of the latest technologies
- The code is organized around business capabilities
- Starts the web container more quickly, so the deployment is also faster
- When change is required in a certain part of the application, only the related service can be modified and redeployed—no need to modify and redeploy the entire application
- Better fault isolation: if one microservice fails, the other will continue to work (although one problematic area of a monolith application can jeopardize the entire system)
- Easy to scale and integrate with third-party services
- No long-term commitment to technology stack
- Due to distributed deployment, testing can become complicated and tedious
- Increasing number of services can result in information barriers
- The architecture brings additional complexity as the developers have to mitigate fault tolerance, network latency, and deal with a variety of message formats as well as load balancing
- Being a distributed system, it can result in duplication of effort
- When number of services increases, integration and managing whole products can become complicated
- In addition to several complexities of monolithic architecture, the developers have to deal with the additional complexity of a distributed system
- Developers have to put additional effort into implementing the mechanism of communication between the services
- Handling use cases that span more than one service without using distributed transactions is not only tough but also requires communication and cooperation between different teams
The Six Characteristics Of Microservices
The current implementation of IHttpClientFactory, that also implements IHttpMessageHandlerFactory, offers the following benefits:
- Provides a central location for naming and configuring logical HttpClient objects. For example, you may configure a client (Service Agent) that's pre-configured to access a specific microservice.
- Codify the concept of outgoing middleware via delegating handlers in HttpClient and implementing Polly-based middleware to take advantage of Polly's policies for resiliency.
- HttpClient already has the concept of delegating handlers that could be linked together for outgoing HTTP requests. You can register HTTP clients into the factory and you can use a Polly handler to use Polly policies for Retry, CircuitBreakers, and so on.
- Manage the lifetime of HttpMessageHandler to avoid the mentioned problems/issues that can occur when managing HttpClient lifetimes yourself.
So, what's a "Typed Client"? It's just an HttpClient that's pre-configured for some specific use. This configuration can include specific values such as the base server, HTTP headers or time outs.
The following diagram shows how Typed Clients are used with IHttpClientFactory:

Figure 8-4. Using IHttpClientFactory with Typed Client classes.
In the above image, a ClientService (used by a controller or client code) uses an HttpClient created by the registered IHttpClientFactory. This factory assigns an HttpMessageHandler from a pool to the HttpClient. The HttpClient can be configured with Polly's policies when registering the IHttpClientFactory in the DI container with the extension method AddHttpClient.
To configure the above structure, add IHttpClientFactory in your application by installing the Microsoft.Extensions.Http NuGet package that includes the AddHttpClient extension method for IServiceCollection. This extension method registers the internal DefaultHttpClientFactory class to be used as a singleton for the interface IHttpClientFactory. It defines a transient configuration for the HttpMessageHandlerBuilder. This message handler (HttpMessageHandler object), taken from a pool, is used by the HttpClient returned from the factory.
In the next code, you can see how AddHttpClient() can be used to register Typed Clients (Service Agents) that need to use HttpClient.
services.AddHttpClient<ICatalogService, CatalogService>(client =>
{
client.BaseAddress = new Uri(Configuration["BaseUrl"]);
})
.AddPolicyHandler(GetRetryPolicy())
.AddPolicyHandler(GetCircuitBreakerPolicy());
static IAsyncPolicy<HttpResponseMessage> GetRetryPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.OrResult(msg => msg.StatusCode == System.Net.HttpStatusCode.NotFound)
.WaitAndRetryAsync(6, retryAttempt => TimeSpan.FromSeconds(Math.Pow(2, retryAttempt)));
}
static IAsyncPolicy<HttpResponseMessage> GetCircuitBreakerPolicy()
{
return HttpPolicyExtensions
.HandleTransientHttpError()
.CircuitBreakerAsync(5, TimeSpan.FromSeconds(30));
}
In this section, you'll learn how to implement the HealthChecks feature in a sample ASP.NET Core 3.1 Web API application when using the Microsoft.Extensions.Diagnostics.HealthChecks package. The Implementation of this feature in a large-scale microservices like the eShopOnContainers is explained in the next section.
To begin, you need to define what constitutes a healthy status for each microservice. In the sample application, we define the microservice is healthy if its API is accessible via HTTP and its related SQL Server database is also available.
In .NET 5, with the built-in APIs, you can configure the services, add a Health Check for the microservice and its dependent SQL Server database in this way:
// Startup.cs from .NET 5 Web API sample
//
public void ConfigureServices(IServiceCollection services)
{
//...
// Registers required services for health checks
services.AddHealthChecks()
// Add a health check for a SQL Server database
.AddCheck(
"OrderingDB-check",
new SqlConnectionHealthCheck(Configuration["ConnectionString"]),
HealthStatus.Unhealthy,
new string[] { "orderingdb" });
}
// Sample SQL Connection Health Check
public class SqlConnectionHealthCheck : IHealthCheck
{
private static readonly string DefaultTestQuery = "Select 1";
public string ConnectionString { get; }
public string TestQuery { get; }
public SqlConnectionHealthCheck(string connectionString)
: this(connectionString, testQuery: DefaultTestQuery)
{
}
public SqlConnectionHealthCheck(string connectionString, string testQuery)
{
ConnectionString = connectionString ?? throw new ArgumentNullException(nameof(connectionString));
TestQuery = testQuery;
}
public async Task<HealthCheckResult> CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = default(CancellationToken))
{
using (var connection = new SqlConnection(ConnectionString))
{
try
{
await connection.OpenAsync(cancellationToken);
if (TestQuery != null)
{
var command = connection.CreateCommand();
command.CommandText = TestQuery;
await command.ExecuteNonQueryAsync(cancellationToken);
}
}
catch (DbException ex)
{
return new HealthCheckResult(status: context.Registration.FailureStatus, exception: ex);
}
}
return HealthCheckResult.Healthy();
}
}
// Startup.cs from .NET 5 Web Api sample
//
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
//…
app.UseEndpoints(endpoints =>
{
//...
endpoints.MapHealthChecks("/hc");
//...
});
//…
}


Health monitoring | Microsoft Docs
// Startup.cs from .NET 5 Web API sample
//
public void ConfigureServices(IServiceCollection services)
{
//...
// Registers required services for health checks
services.AddHealthChecks()
// Add a health check for a SQL Server database
.AddCheck(
"OrderingDB-check",
new SqlConnectionHealthCheck(Configuration["ConnectionString"]),
HealthStatus.Unhealthy,
new string[] { "orderingdb" });
}
- What is Azure Kubernetes Service?
Azure Kubernetes Service (AKS) manages your hosted Kubernetes environment and makes it simple to deploy and manage containerized applications in Azure. Your AKS environment is enabled with features such as automated updates, self-healing, and easy scaling. The Kubernetes cluster master is managed by Azure and is free. You manage the agent nodes in the cluster and only pay for the VMs on which your nodes run.
You can either create your cluster in the Azure portal or use the Azure CLI. When you create the cluster, you can use Resource Manager templates to automate cluster creation. With these templates, you specify features such as advanced networking, Azure Active Directory (AD) integration, and monitoring. This information is then used to automate the cluster deployment on your behalf.
With AKS, we get the benefits of open-source Kubernetes without the complexity or operational overhead compared to running our own custom Kubernetes cluster.
At its core, an AKS cluster is a cloud hosted Kubernetes cluster. Unlike a custom Kubernetes installation, AKS streamlines the installation process and takes care of most of the underlying cluster management tasks.
You have two options when you create an AKS cluster. You either use the Azure portal or Azure CLI. Both options require you to configure basic information about the cluster. For example:
- The Kubernetes cluster name
- The version of Kubernetes to install
- A DNS prefix to make the master node publicly accessible
- The initial node pool size
The initial node pool size defaults to two nodes, however it's recommended that at least three nodes are used for a production environment.

AKS supports the Docker image format that means that you can use any development environment to create a workload, package the workload as a container and deploy the container as a Kubernetes pod.
Here you use the standard Kubernetes command-line tools or the Azure CLI to manage your deployments. The support for the standard Kubernetes tools ensures that you don't need to change your current workflow to support an existing Kubernetes migration to AKS.
AKS also supports all the popular development and management tools such as Helm, Draft, Kubernetes extension for Visual Studio Code and Visual Studio Kubernetes Tools.
-
Microsoft bot framework:
-
Technology:
Version 4.3
.NET Core 2.2
-
Like pages in webapp – here dialogs – main dialog and sub dialogs called by on-turn async, routedialog.
-
Session management by user state, conversation state
-
.bot file for configuration
-
Adaptive cards for chat designing – configurable
-
Qna maker filter based on meta data
-
Endpoint -api url for bot messages
-
Microsoft app id password to login chat regtd
-
Dispatch LUIS and luis instances - Dispatch command line tool
-
Dispatch to split between LUIS task related messages and QnA clarifier
-
DB for storing conversations based on conv id
-
Adaptive card:
-
Cards are sent as an attachment
-
action.submit -for submit
-
radio button – input.choiceset
-
action.openurl – for opening site by url
- LUIS
- Intents - An intent represents a task or action the user wants to perform. It is a purpose or goal expressed in a user's utterance.
- Entity - Entities extract data from the utterance. Entity types give you predictable extraction of data. There are two types of entities: machine-learned and non-machine-learned. It is important to know which type of entity you are working with in utterances.
- Role - Roles allow entities to have named subtypes. A role can be used with any prebuilt or custom entity type and used in both example utterances and patterns.
- Utterances - are input from the user that your app needs to interpret. To train LUIS to extract intents and entities from them
- Phrases - Add features to a language model to provide hints about how to recognize input that you want to label or classify. Features help LUIS recognize both intents and entities, but features are not intents or entities themselves.
- History – train -Patterns are designed to improve accuracy when several utterances are very similar. A pattern allows you to gain more accuracy for an intent without providing many more utterances.
-
C#:
1. Generics – some keyword to mention – compile time assign type. 2. Collections:

1. Struct
2. Class - blue print of object
3. Datatypes –

1. Value types – in Heap
Value Type:
A Value Type stores its contents in memory allocated on the stack. When you created a Value Type, a single space in memory is allocated to store the value and that variable directly holds a value. If you assign it to another variable, the value is copied directly and both variables work independently. Predefined datatypes, structures, enums are also value types, and work in the same way. Value types can be created at compile time and Stored in stack memory, because of this, Garbage collector can't access the stack.
1. Reference types – in Stack
Reference Type:
Reference Types are used by a reference which holds a reference (address) to the object but not the object itself. Because reference types represent the address of the variable rather than the data itself, assigning a reference variable to another doesn't copy the data. Instead it creates a second copy of the reference, which refers to the same location of the heap as the original value. Reference Type variables are stored in a different area of memory called the heap. This means that when a reference type variable is no longer used, it can be marked for garbage collection. Examples of reference types are Classes, Objects, Arrays, Indexers, Interfaces etc.
1. Var – anonymous type - implicitly typed variable – type based on right side of =
2. Dynamic type - A dynamic type escapes type checking at compile time; instead, it resolves type at run time.
3. Enum – named integer constants
4. LINQ - language integrated query - single querying interface for different types of data sources.
var teenStudentsName = from s in studentList
where s.age > 12 && s.age < 20
selectnew { StudentName = s.StudentName };
1. Lambda – lambda expression along with linq – shorter way to represent anonymous method – special syntax
var studentNames = studentList.Where(s => s.Age > 18)
.Select(s => s)
.Where(st => st.StandardID > 0)
.Select(s => s.StudentName);
1. Extension method - additional methods. Extension methods allow you to inject additional methods without modifying, deriving or recompiling the original class, struct or interface
-
public static class XX
-
{ -
**public** **static** **void** NewMethod( **this** Class1 ob) -
{ -
Console.WriteLine("Hello I m extended method"); -
} -
}- Async - Async and await are the code markers, which marks code positions from where the control should resume after a task completes.
- pass by ref - memory based – same value
- pass by value – value will be different diff ram location address
- Optional parameters -
| BASIS FOR COMPARISON | BOXING | UNBOXING |
|---|---|---|
| Basic | Object type refers to the value type. | process of retrieving value from the boxed object. |
| --- | --- | --- |
| Storage | The value stored on the stack is copied to the object stored on heap memory. | The object's value stored on the heap memory is copied to the value type stored on stack. |
| Conversion | Implicit conversion. | Explicit conversion. |
| Example | int n = 24; | |
| object ob = n; | int m = (int) ob; |
-
Oops:
- polymorphism
overloading - same method name attributes different – parameters
Overriding – same method name and attributes – inheritance – parent class method with virtual keyword – child class override keyword.
- Encapsulation
- Interface – only method defn no content – used for multiple inheritance – not available in c#
- Abstract – method defn or full method – inheriting can override or implement
– eg>: cellphone old model features used in new ones.
-
Sealed Class – cannot inherit class – extension method is possible
-
Entity Framework
Entity Framework is an Object Relational Mapper (ORM) which is a type of tool that simplifies mapping between objects in your software to the tables and columns of a relational database.
- Types:
POCO - just auto create in visual studio - A POCO entity is a class that doesn't depend on any framework-specific base class. It is like any other normal .NET CLR class, which is why it is called "Plain Old CLR Objects".
Dynamic – change some properties attribute based
- Entity Lifecycle
States in lifetime –
-
Added: The entity is marked as added.
-
Deleted: The entity is marked as deleted.
-
Modified: The entity has been modified.
-
Unchanged: The entity hasn't been modified.
-
Detached: The entity isn't tracked.
- State:
-
Unchanged State
-
When an entity is Unchanged, it's bound to the context but it hasn't been modified.
-
By default, an entity retrieved from the database is in this state.
-
When an entity is attached to the context (with the Attach method), it similarly is in the Unchanged state.
-
The context can't track changes to objects that it doesn't reference, so when they're attached it assumes they're Unchanged.
-
Detached State
-
Detached is the default state of a newly created entity because the context can't track the creation of any object in your code.
-
This is true even if you instantiate the entity inside a using block of the context.
-
Detached is even the state of entities retrieved from the database when tracking is disabled.
-
When an entity is detached, it isn't bound to the context, so its state isn't tracked.
-
It can be disposed of, modified, used in combination with other classes, or used in any other way you might need.
-
Because there is no context tracking it, it has no meaning to Entity Framework.
-
Added State
-
When an entity is in the Added state, you have few options. In fact, you can only detach it from the context.
-
Naturally, even if you modify some property, the state remains Added, because moving it to Modified, Unchanged, or Deleted makes no sense.
-
It's a new entity and has no correspondence with a row in the database.
-
This is a fundamental prerequisite for being in one of those states (but this rule isn't enforced by the context).
-
Modified State
-
When an entity is modified, that means it was in Unchanged state and then some property was changed.
-
After an entity enters the Modified state, it can move to the Detached or Deleted state, but it can't roll back to the Unchanged state even if you manually restore the original values.
-
It can't even be changed to Added, unless you detach and add the entity to the context, because a row with this ID already exists in the database, and you would get a runtime exception when persisting it.
-
Deleted State
-
An entity enters the Deleted state because it was Unchanged or Modified and then the DeleteObject method was used.
-
This is the most restrictive state, because it's pointless changing from this state to any other value but Detached.
- Entity Framework Approach types:
-
Code First
-
Database First
-
Model First
- APIGEE
- Azure
7.1. Azure App Service vs Azure Functions: What are the differences?
Developers describe Azure App Service as "Build, deploy, and scale web apps on a fully managed platform". Quickly build, deploy, and scale web apps created with popular frameworks .NET, .NET Core, Node.js, Java, PHP, Ruby, or Python, in containers or running on any operating system. Meet rigorous, enterprise-grade performance, security, and compliance requirements by using the fully managed platform for your operational and monitoring tasks.
On the other hand, Azure Functions is detailed as "Listen and react to events across your stack". Azure Functions is an event driven, compute-on-demand experience that extends the existing Azure application platform with capabilities to implement code triggered by events occurring in virtually any Azure or 3rd party service as well as on-premises systems.
Azure App Service and Azure Functions are primarily classified as "Platform as a Service" and "Serverless / Task Processing" tools respectively.
Pros of App service:
- .Net Framework
- Visual studio
Pros of Azure Function Su
- Pay only when invoked
- Great developer experience for C#
- Multiple languages supported
- Great debugging support
- Can be used as lightweight https service
- Poor developer experience for C#
- Easy scalability
When hosting an Azure Function in an App Service Plan, are there any significant differences compared with using an App Service associated with the same App Service Plan? I assume the only difference is that the Function offers additional out of the box triggers. Any differences I'm missing that would lead to preferring one over the other?
Well, an Azure Function is a different beast than an App Service. An Azure function is triggered by an external event or a timer. It then executes the code of the function. When hosted on a consumption plan this execution is allowed to run for 5 or 10 minutes max. When you need a longer execution time you need to run it on an App Service Plan.
An App Service can host any app you've created. Like a website (that runs continuously and doesn't need to be triggered before it starts doing something) or an api for example.
I'd also like to confirm that hosting Azure Functions in an App Service Plan can actually limit scalability if scaling is not configured on the App Service Plan. As I understand it, Functions automatically scale as needed when using Consumption or Premium hosting without additional configuration.
Correct, when hosting Azure Functions in an App Service Plan you are responsible for making sure the app service is scaled to allow the function to perform well under load. Thats why the consumption plan is designed to handle this so the developer can focus on the functionality and does not need to worry about the infrastructure.
So, for integration scenario's azure functions are a very natural fit. For web sites an App Service might be the best solution.
To address your comment:
I should have mentioned that this question was in the context of hosting a restful API and not a UI application. In this scenario, I'm not seeing much difference between a Function and App Service, but please correct me if I'm missing something
A couple of things: For one, there is a certain sweet spot. If traffic is heavy enough a consumption plan based azure function might be more costly than having a dedicated app service plan. That depends of course on a lot of factors (CPU usage, request duration etc.). Also, you won't be able to use things like Asp.Net Core Middleware out of the box. Finally, I'd argue that if your api is becoming large enough managing a single asp.net core solution may be easier than having to manage a lot of azure functions with small functions or one azure function project with lots and lots of functions, but hey, that's just my opinion (haven't actually dealt with it to be honest)
When not to use Azure Functions?
Azure functions are not for everything. Not all applications should be using Azure functions apps. As I mentioned earlier, Azure functions uses triggers and once an event is triggered, the task will be executed in the background.
Azure functions are not a replacement of Web APIs. If your web applications use Web APIs as middleware to bunch of data and business logic related tasks.
Unlike Web API or services, Azure Functions are not designed to multiple tasks. An Azure functions app should be designed to do one task only.
Azure functions are not designed to work in tightly coupled systems that are dependent on other parts of application.
Azure functions are not for front-end applications where data is being accessed and saved back and forth in the backend databases.
Azure functions should not have too much complex logic in the function code.
Azure functions are compute-on-demand. Replacing an API with bunch of Azure functions apps may increase your cost of development, maintenance, and compute.
Azure Web Job is a piece of code runs in the Azure App services. It is a Cloud Service used to run background tasks. Azure Functions are built on the top of Azure Web Jobs with the added capabilities. The table below differentiates Azure Functions and Web Jobs:
| Azure Functions | Web Jobs | |
|---|---|---|
| Trigger | Azure Functions can be triggered with any of the configured trigger, but it doesn't run continuously | Web Jobs is of two types, Triggered Web Jobs and Continuous Web Jobs |
| Supported languages | Azure Functions support various languages like C#, F#, JavaScript, node.js and more. | Web Jobs also support various languages like C#, F#, JavaScript and more. |
| Deployment | Azure Functions is a separate App Service that run in the App Service Plan | Web Jobs run as a background service for the App services like Web App, API Apps and mobile Apps |
An Azure function is a code triggered by an event whereas an Azure Logic app is a workflow triggered by an event.
Azure Logic App can define a workflow at ease consuming a range of APIs as connectors. These connectors will perform series of actions defined in the workflow. Like Azure Logic Apps, durable Azure Functions can also be used to define workflow in code structure.
| Azure Functions | Azure Logic Apps | |
|---|---|---|
| Trigger | Azure Functions can be triggered with the configured trigger like HTTPTrigger, TimerTrigger, QueueTrigger and more | Azure Logic Apps can be triggered with the API as connectors. It can also have multiple triggers in a workflow. |
| Defining Workflow | Workflow in Azure Functions can be defined using Azure Durable Function. It consists of Orchestrator Function that has the workflow defined with Several Activity Functions | Workflow on Azure Logic Apps can be defined with Logic App designer using various APIs as Connector. |
| Monitoring | Azure Functions can be monitored using Application Insights and Azure Monitor | Azure Logic Apps can be monitored using Log Analytics and Azure Monitor |
| Serverless360 can monitor both Azure Function Apps and Logic Apps |
- Explain the differences between NoSQL and relational databases.
There are two types of database systems are implemented Relational and NoSQL. There are lot of differences in these systems.
- Relational Database provide store of related tables while NoSQL stores the unstructured or semi-structured data in the form of key/value or JSON documents.
- Relational DB has fixed schema while NoSQL DB has dynamic schema.
- Relational DB use SQL (Structured Query Language) to manage the data, NoSQL DB have many models for managing and accessing the data.
- Relational Tables provide ACID guarantees, but NoSQL does not provide ACID guarantees beyond the scope of single DB partition. - In the context of transaction processing, the acronym ACID refers to the four key properties of a transaction: atomicity, consistency, isolation, and durability. ... After a transaction successfully completes, changes to data persist and are not undone, even in the event of a system failure.
- Relational DBs are mature, proven and widely used whereas NoSQL is high performance database with ease-of-use, resilience, scalability, and availability characteristics.
- What is Cosmos DB?
Azure Cosmos DB is a multi-model database service by Microsoft, that is globally distributed. It provides the capability of scale the throughput and storage across any number of azure regions with a single button click. You can manage and access the data using your favorite API including (MongoDB, SQL, Cassandra, Tables, Gremlin). Cosmos DB provides some SLA (service level agreements) for consistency guarantee, throughput, availability, and latency.
- Explain the common use cases for Azure Cosmos DB.
Azure Cosmos DB is a good choice for any Mobile, Web, Gaming or IOT applications that needs:
- low and fast order of millisecond response times.
- predictable performance
- to automatic scale rapidly and globally
- ability to query over schema-free data.
-
How does Azure Cosmos DB provide predictable performance?
-
What do you think about HIPAA compliances for Azure Cosmos DB ?
HIPAA establishes the standards to use, safeguarding and disclose the identifiable health information of any individual. Azure Cosmos DB fully supports HIPAA Compliance or it's HIPAA compliant. For more about HIPAA compliance visit What is HIPAA.
- Is there any storage limit of Cosmos DB?
There is no storage limit for a Cosmos container. It can store any amount of data.
- Can I use multiple APIs to access the data in Cosmos DB?
Can I use multiple APIs to access my data? Azure Cosmos DB is Microsoft's globally distributed, multi-model database service. ... As a result, we recommend using the same API for all access to the data in a given account. Each API operates independently, except the Gremlin and SQL API, which are interoperable.
-
How does Cosmos DB provide support for various data models like key/value, columnar, document and graph? How does Azure Cosmos DB support various data models such as key/value, columnar, document, and graph? ... Azure Cosmos DB has a schema agnostic indexing engine capable of automatically indexing all the data it ingests without requiring any schema or secondary indexes from the developer.
-
How does Cosmos DB cost is calculated? The cost of all database operations is normalised and expressed as request units (RU). Azure Cosmos DB offers two database operations models: Provisioned Throughput is measured in request units per second (RU/s) and billed per hour. ... Serverless bills for the request units (RU) used for each database operation.
-
Explain the throughput. You specify the exact amount of throughput you need and Azure Cosmos DB guarantees the configured throughput, backed by SLA. You can start with a minimum throughput of 400 RU/sec and scale up to tens of millions of requests per second or even more The cost of all database operations is normalized by Azure Cosmos DB and is expressed by Request Units (or RUs, for short). You can think of RUs per second as the currency for throughput.
-
Describe the throughput limits of Azure Cosmos DB. What are the throughput limits of Azure Cosmos DB? There's no limit to the total amount of throughput that a container can support in Azure Cosmos DB. The key idea is to distribute your workload roughly evenly among a sufficiently large number of partition keys.
-
Does Azure Cosmos DB provide free account?
-
Explain the connection mode. Are Direct and Gateway connection modes encrypted? Azure Cosmos DB offers a simple, open RESTful programming model over HTTPS called gateway mode. Additionally, it offers an efficient TCP protocol, which is also RESTful in its communication model and uses TLS for initial authentication and encrypting traffic, called direct mode.
For more you can refer Connection Mode
- Explain the indexing in Cosmos DB. In Azure Cosmos DB, every container has an indexing policy that dictates how the container's items should be indexed. The default indexing policy for newly created containers indexes every property of every item and enforces range indexes for any string or number. This allows you to get good query performance without having to think about indexing and index management upfront.
In some situations, you may want to override this automatic behavior to better suit your requirements. You can customize a container's indexing policy by setting its indexing mode, and include or exclude property paths.
For more you can refer Indexing in Azure Cosmos DB
- Describe the Indexing policies in Cosmos DB.
For more you can refer Indexing policies in Azure Cosmos DB
-
What Indexing modes Azure Cosmos DB supports?
-
Describe the change feed in Azure Cosmos DB. Change feed in Azure Cosmos DB is a persistent record of changes to a container in the order they occur. Change feed support in Azure Cosmos DB works by listening to an Azure Cosmos container for any changes. It then outputs the sorted list of documents that were changed in the order in which they were modified.
-
Describe the Partitioning in Azure Cosmos DB. Azure Cosmos DB uses partitioning to scale individual containers in a database to meet the performance needs of your application. In partitioning, the items in a container are divided into distinct subsets called logical partitions. Logical partitions are formed based on the value of a partition key that is associated with each item in a container. All the items in a logical partition have the same partition key value.
-
How Azure Cosmos DB is globally distributed database? Azure Cosmos DB is a globally distributed database system that allows you to read and write data from the local replicas of your database. ... With Azure Cosmos DB, you can add or remove the regions associated with your account at any time. Your application doesn't need to be paused or redeployed to add or remove a region.
For more you can refer Global distribution in Cosmos DB
- How will you implement Azure Cosmos DB security?
For more you can refer Security in Azure Cosmos DB
- Explain the ACID in Cosmos DB. A transaction in a typical database can be defined as a sequence of operations performed as a single logical unit of work. Each transaction provides ACID (Atomicity, Consistency, Isolation, Durability) property guarantees.
- Atomicity guarantees that all the operations done inside a transaction are treated as a single unit, and either all of them are committed or none of them are.
- Consistency makes sure that the data is always in a valid state across transactions.
- Isolation guarantees that no two transactions interfere with each other – many commercial systems provide multiple isolation levels that can be used based on the application needs.
- Durability ensures that any change that is committed in a database will always be present. Azure Cosmos DB supports full ACID compliant transactions with snapshot isolation for operations within the same logical partition key.
For more you can refer ACID in Cosmos DB
-
Explain common clauses (Select, From, Where, Order By, Group By, Offset Limit) in Azure Cosmos DB.
-
Explain the SQL subquery and it's types.
A subquery is a query which is nested within another query. A query or statement that contains sub query is called as outer query. Sometimes subquery is known as inner query. There are two types of subqueries. Azure Cosmos DB supports only Correlated subqueries.
- Correlated - This type of subquery is evaluated once for each row processed by outer query and this subquery reference values from outer query.
- Non-correlated - This type of subquery does not depend on outer query. It can be run on its own without referencing values from outer query.
Subqueries can be further classified into three categories based on the number of rows and columns returned by the subquery as below.
- Table - returns multiple rows and multiple columns.
- Multi-value - returns multiple rows and single column.
- Scalar - returns single row and single column.
For more you can refer SQL subquery in Azure Cosmos DB
-
Explain Joins.
-
How Azure Cosmos DB SQL query execution works? About SQL query execution. In Azure Cosmos DB, you store data in containers , which can grow to any storage size or request throughput. Azure Cosmos DB seamlessly scales data across physical partitions under the covers to handle data growth or increase in provisioned throughput.
-
What APIs Azure Cosmos DB offers?
-
What are the benefits of using server-side programming in Azure Cosmos DB? Benefits of using server-side programming
- Batching: You can group operations like inserts and submit them in bulk. ...
- Pre-compilation: Stored procedures, triggers, and UDFs are implicitly pre-compiled to the byte code format in order to avoid compilation cost at the time of each script invocation.
For more you can refer server-side programming in Cosmos DB
-
What is Container in Cosmos DB?
-
What is _etag in Azure Cosmos DB? Every item stored in an Azure Cosmos container has a system defined _etag property. The value of the _etag is automatically generated and updated by the server every time the item is updated. ... The value of the if-match header matches the value of the _etag at the server, the item is then updated.
- What is NoSQL database?
NoSQL DB or non-relational databases store the data differently than relational databases do. NoSQL databases provide easy scale and high performance for massive amount of unstructured and rapidly changing data. A relational data can also be stored in a NoSQL database but differently than relational databases (SQL Server, PostgreSQL) do. NoSQL databases has different types (Document DB, Key-value database, Graph database etc) based on data model. NoSQL database sometimes called as "Not only SQL" or "non-SQL" database can also handle a huge amount of highly structured data means they are not restricted to fixed data models like relational databases.
- How to choose between non-relational (NoSQL) and relational (SQL) databases?
You can choose between NoSQL and SQL databases based on certain parameters as below.
- BEST FOR
NoSQL database is best for:
- massive amount, rapidly changing and unstructured data.
- When data is schema agnostic.
SQL or relational database is best for:
- When data schema is maintained by application.
- Relational data that logical structure and requirement can be identified in advance.
- Scenarios - NoSQL is good choice for Mobile apps, real-time analytics, IoT Apps, Database migration. RDBMS is good for Banking systems, finance systems, Inventory management, Transaction management systems.
- Scalability - NoSQL databases provide scalability horizontally by sharing across multiple servers. RDBMS provide scalability vertically by increasing server load.
- Data Model - Database can be of any type - Key value, columnar, document DB and graph database. RDBMS database is in the form of tables of rows and columns and use SQL to query data.
- For more visit - NoSQL Database
- What are the different types of NoSQL Database.
There are 4 most common types of NoSQL databases as below.
- Key-value databases
- Document databases
- Wide-column or Column-family databases
- Graph databases stores
- What is Key-Value store or Key-Value database?
Key/Value database use the key-value pairs to store the data in a hash table. Key uniquely identifies the data. This is used to store data using appropriate hash function. Key-Value is good choice when you want to lookup some data based on key rather than performing joins over multiple tables of key values. For more visit key-value data store.
- What is DocumentDB?
DocumentDB or Document database is a completely NoSQL database service that stores the data as schema-free JSON (JavaScript Object Notation) document. When you are working on some application that needs to handle data with changing schema or you are not sure about the data which you needs to work with and how much data application needs to handle. You are also not sure about the structure of data. You also need scalability, low cost and fast deployment for your data. In all these scenarios we consider DocumentDB. There are many DocumentDB services as below.
-
What is Column store database?
-
What is Graph Database (GDB)?
-
What are the advantages of NoSQL?
-
What are the disadvantages of NoSQL Databases?
-
Explain some features of NoSQL Databases?
-
How to choses correct database between NoSQL and RDBMS?
-
What is Vertical and Horizontal Scaling?
-
What is Database Sharding?
-
How to scale NoSQL database?
-
What is NoSQL - CAP Theorem?
-
What is Polyglot Persistence in NoSQL Space?
-
What do you understand by NoSQL Database Performance Tuning?
-
What are different approaches to query optimization in NoSQL DB?
- How much will you rate yourself in NoSQL?
When you attend an interview, Interviewer may ask you to rate yourself in a specific Technology like NoSQL, So It's depend on your knowledge and work experience in NoSQL.
- What challenges did you face while working on NoSQL?
This question may be specific to your technology and completely depends on your past work experience. So you need to just explain the challenges you faced related to NoSQL in your Project.
- What was your role in the last Project related to NoSQL?
It's based on your role and responsibilities assigned to you and what functionality you implemented using NoSQL in your project. This question is generally asked in every interview.
- How much experience do you have in NoSQL?
Here you can tell about your overall work experience on NoSQL.
- Have you done any NoSQL Certification or Training?
It depends on the candidate like you have done any NoSQL training or certification. Certifications or training are not essential but good to have.
Azure Cosmos DB vs Azure Storage: What are the differences?
What is Azure Cosmos DB? A fully-managed, globally distributed NoSQL database service. Azure DocumentDB is a fully managed NoSQL database service built for fast and predictable performance, high availability, elastic scaling, global distribution, and ease of development.
What is Azure Storage? Reliable, economical cloud storage for data big and small. Azure Storage provides the flexibility to store and retrieve large amounts of unstructured data, such as documents and media files with Azure Blobs; structured nosql based data with Azure Tables; reliable messages with Azure Queues, and use SMB based Azure Files for migrating on-premises applications to the cloud.
Azure Cosmos DB can be classified as a tool in the "NoSQL Database as a Service" category, while Azure Storage is grouped under "Cloud Storage".
Some of the features offered by Azure Cosmos DB are:
- Fully managed with 99.99% Availability SLA
- Elastically and highly scalable (both throughput and storage)
- Predictable low latency: <10ms @ P99 reads and <15ms @ P99 fully-indexed writes
On the other hand, Azure Storage provides the following key features:
- Blobs, Tables, Queues, and Files
- Highly scalable
- Durable & highly available
"Best-of-breed NoSQL features" is the primary reason why developers consider Azure Cosmos DB over the competitors, whereas "All-in-one storage solution" was stated as the key factor in picking Azure Storage.
-
Pros of Azure Cosmos DB
-
Best-of-breed NoSQL features
-
High scalability
-
Globally distributed
-
Automatic indexing over flexible json data model
-
Tunable consistency
-
Always on with 99.99% availability sla
-
Javascript language integrated transactions and queries
-
Predictable performance
-
High performance
-
Analytics Store
-
Ease of use
-
No Sql
-
Rapid Development
-
Auto Indexing
Pros of Azure Storage
-
All-in-one storage solution
-
Pay only for data used regardless of disk size
-
Shared drive mapping
-
Cheapest hot and cloud storage
-
Cost-effective
- Azure Types:
Types of Azure Clouds
There are mainly three types of clouds in Microsoft Azure are:
- PAAS – (Platform as a service) is a computing platform which includes an operating system, programming language execution environment, database or web services. This Azure service is used by developers and application providers.
- SAAS – (Software as a service) is software which is centrally hosted and managed. It is a single version of the application is used for all customers. You can scale out to multiple instances. This helps you to ensure the best performance in all locations. The software is licensed through a monthly or annual subscription. MS Exchange, Office, Dynamics are offered as a SaaS
- IASS - (Infrastructure as a Service) is the foundational cloud platform layer. This Azure service is used by IT administrators for processing, storage, networks or any other fundamental computer operations.
A chatbot is an Artificial Intelligence (AI) software used to stimulate conversations with users in a natural language through telephones, websites, messages, and mobile apps. A chatbot responds based on the input from a user. These are smart robots which answer questions. They receive the questions, process them by understanding the question, and then deliver the answer that the user needs.
The chatbot is trained with actual chat data. Companies which already make use of human-powered chat have logs of the previous conversations. These logs are used to analyze what people are asking and what they intend to convey. With a combination of machine learning models and an ensemble of tools, the user's questions are matched with their intents. Models are trained in such a way that the bot is able to connect similar questions to a correct intent and produce the correct answer.
It is taught in the same way as humans are taught but at a larger scale and in a much faster manner. To teach a human customer service representative, we provide them with manuals which they read and understand and apply in a practical setting while performing the work. In the case of chatbots, thousands of conversation logs are shown to it and from that, it understands the nature of questions and the types of answers it needs to provide.
At the end of each conversation with a chatbot, the question, 'Did we help you?' is asked and if we answer 'No,' the conversation is forwarded to human support. The same way when a chatbot is unable to understand a question provided by a human, it will forward the conversation by itself to human customer support.
5. How does the bot continue to learn once it's life and how do we make sure it doesn't start behaving or speaking in an inappropriate manner?
Once the bot is set-up and starts interacting with customers, smart feedback loops are implemented. When customers ask questions, chatbots give them certain options in order to understand their questions and needs more clearly. This information is used to retrain the model thereby ensuring the accuracy of the chatbot. There are also guarding systems which have been implemented to make sure that the bot doesn't change based on a few replies. This is also ensured by making sure that the bot simply just doesn't rephrase what people tell it but is actually taught to answer questions the way its owner (the company) wants it to answer.
Yes, absolutely. The chatbot has been programmed to understand specific questions. The developing company can decide the extent to which it wants to expand or shrink its understanding.
It saves time and money and improves customer experience. It helps get feedback from actual users in real-time. Chatbots get smarter with time. They reduce the need for human intervention as the User Interface (UI) is generated automatically in many cases. For businesses with powerful front-end tooling, it can help in setting up cognitive chatbots in all your channels.
One needs to have a fair knowledge of back-end technologies and analytics. Languages used for developing chatbots are Java, C#, Python, and Node JS. To be able to answer arbitrary questions and to develop these smart robots, a deep understanding of machine learning, artificial intelligence, Natural Language Understanding (NLU), and Google Cloud Natural Language API (Application Programming Interface) is required.
AI-powered bots working with voice and text may become a common feature and an everyday activity of humans. It will become as regular as 3G internet and 3D printing are in today's scenario. In the close future, chatbots will become more human-like that it will be possible to ask a bot to make something for you which the bot will carry out if it is possible. They will become more like personal assistants to carry out our routine tasks such as buying groceries, paying bills, searching for holiday destinations, and much more.
Few Questions :
- How well you know about NLP or Natural Processing Language?
Chatbots are developed to provide the user with a conversation interaction between human and machine, and Natural Processing Language makes this happen easily. This language ensures that chatbots are more human. So, knowing NLP or Natural Processing language is important.
2. What are the other programming language, you know?
As a Bot developer, you are required to have knowledge about different programming languages and technologies. Some of the popular languages that you should be knowing are Python, Java, Clojure, jQuery, Java, Angular, SQL, JavaScript, and Amazon Simple Service.
3. Is it possible to control Bot once it has gone live?
Once you have made Bot live, it can be controlled. It has been programmed to understand a set of questions. The company developing the bot can decide when to expand or shrink the understanding of questions.
4. What is Mitsuku consumer bot?
It is one of the most popular and important bots which runs on Pandorabots. It is the world's leading conversation; AI chatbot platform. Pandorabots offers free web service for building bots.
5. How can you use AIML or Artificial Intelligence Markup Language or AIML to simplify bot models' conversation?
AIML is a flexible and universal language that the bot develops uses to write pattern templates. The developer uses AIML to match words and phrase patterns to keywords so that bits can have a more humane interaction with the user.
Wrapping it up- Chatbots is one of the most human ways the software can interact with humans and answer their queries. There are many bots that are being used to enhance customer interaction and customer satisfaction.
- Azure Functions:
Azure Functions makes the app development process more productive, and lets you launch serverless applications on Microsoft Azure. It helps in processing data, coordinating with different systems for IoT, integrating various processes and systems and building simple APIs and microservices.
1. **Features**
Here are some key features of Functions:
-
Choice of language - Write functions using your choice of C#, Java, Javascript, Python, and other languages. See Supported languages for the complete list.
-
Pay-per-use pricing model - Pay only for the time spent running your code. See the Consumption hosting plan option in the pricing section.
-
Bring your own dependencies - Functions supports NuGet and NPM, so you can use your favorite libraries.
-
Integrated security - Protect HTTP-triggered functions with OAuth providers such as Azure Active Directory, Facebook, Google, Twitter, and Microsoft Account.
-
Simplified integration - Easily leverage Azure services and software-as-a-service (SaaS) offerings.
-
Flexible development - Code your functions right in the portal or set up continuous integration and deploy your code through GitHub, Azure DevOps Services, and other supported development tools.
-
Open-source - The Functions runtime is open-source and available on GitHub.
- Types:
-
HTTPTrigger - Trigger the execution of your code by using an HTTP request. For an example, see Create your first function.
-
TimerTrigger - Execute cleanup or other batch tasks on a predefined schedule. For an example, see Create a function triggered by a timer.
-
CosmosDBTrigger - Process Azure Cosmos DB documents when they are added or updated in collections in a NoSQL database. For more information, see Azure Cosmos DB bindings.
-
BlobTrigger - Process Azure Storage blobs when they are added to containers. You might use this function for image resizing. For more information, see Blob storage bindings.
-
QueueTrigger - Respond to messages as they arrive in an Azure Storage queue. For more information, see Azure Queue storage bindings.
-
EventGridTrigger - Respond to events delivered to a subscription in Azure Event Grid. Supports a subscription-based model for receiving events, which includes filtering. A good solution for building event-based architectures. For an example, see Automate resizing uploaded images using Event Grid.
-
EventHubTrigger - Respond to events delivered to an Azure Event Hub. Particularly useful in application instrumentation, user experience or workflow processing, and internet-of-things (IoT) scenarios. For more information, see Event Hubs bindings.
-
ServiceBusQueueTrigger - Connect your code to other Azure services or on-premises services by listening to message queues. For more information, see Service Bus bindings.
-
ServiceBusTopicTrigger - Connect your code to other Azure services or on-premises services by subscribing to topics. For more information, see Service Bus bindings.
- App Service:
Azure App Service is a fully managed "Platform as a Service" (PaaS) that integrates Microsoft Azure Websites, Mobile Services, and BizTalk Services into a single service, adding new capabilities that enable integration with on-premises or cloud systems.

- Microsoft Service Fabric:
Microsoft Azure Service Fabric is the next-generation cloud application platform for highly scalable, highly reliable distributed applications. It introduces many new features for packaging, deploying, upgrading, and managing distributed cloud applications.
- Cloud Service:
Azure Cloud Services is an example of a platform as a service (PaaS). Like Azure App Service, this technology is designed to support applications that are scalable, reliable, and inexpensive to operate.

1. Two types of Azure Cloud Services roles. The only difference between the two is how your role is hosted on the VMs:
-
Web role: Automatically deploys and hosts your app through IIS.
-
Worker role: Does not use IIS, runs your app standalone.
A cloud service is created from three components, the service definition (.csdef), the service config (.cscfg), and a service package (.cspkg). Both the ServiceDefinition.csdef and ServiceConfig.cscfg files are XML-based and describe the structure of the cloud service and how it's configured; collectively called the model. The ServicePackage.cspkg is a zip file that is generated from the ServiceDefinition.csdef and among other things, contains all the required binary-based dependencies. Azure creates a cloud service from both the ServicePackage.cspkg and the ServiceConfig.cscfg.
Once the cloud service is running in Azure, you can reconfigure it through the ServiceConfig.cscfg file, but you cannot alter the definition.
- Differences between Cloud Services and Service Fabric before
- Cloud Services is about deploying applications as VMs.
- Service Fabric is about deploying applications to existing VMs or machines running Service Fabric on Windows or Linux
Cloud Service Sample below:

Service Fabric Sample Below: 
Cloud service Architecture: 
Service Fabric Architecture -for migrated ones and new development ones
Service Fabric – can be stateful or stateless, but cloud services are stateless and need to have DB for maintaining connectivity and also connections to other items through queue - but in-service fabric we don't need Queue for connectivity.
Service Fabric architectures: 
Service Fabric without migration or without queues:

Advantages of Service Fabric:
- Fast deployment times. Creating VM instances can be time consuming. In Service Fabric, VMs are only deployed once to form a cluster that hosts the Service Fabric application platform. From that point on, application packages can be deployed to the cluster very quickly.
- High-density hosting. In Cloud Services, a Worker Role VM hosts one workload. In Service Fabric, applications are separate from the VMs that run them, meaning you can deploy a large number of applications to a small number of VMs, which can lower overall cost for larger deployments.
- The Service Fabric platform can run anywhere that has Windows Server or Linux machines, whether it's Azure or on-premises. The platform provides an abstraction layer over the underlying infrastructure so your application can run on different environments.
- Distributed application management. Service Fabric is a platform that not only hosts distributed applications, but also helps manage their lifecycle independently of the hosting VM or machine lifecycle.
- Logging
- ADO.NET
- AngularJS
- AngularJS is a client-side JavaScript MVC framework to develop a dynamic web application.
- entirely based on HTML and JavaScript
- The ng-app directive is a starting point of AngularJS Application. It initializes the AngularJS framework automatically. AngularJS framework will first check for ng-app directive in a HTML document after the entire document is loaded and if ng-app is found, it bootstraps itself and compiles the HTML template.
- <bodyng-app="myAngularApp">
<script>
var app = angular.module('myAngularApp', []);
</script>
-
{{ expression }}
- Directives
| Directive | Description |
|---|---|
| ng-app | Auto bootstrap AngularJS application. |
| --- | --- |
| ng-init | Initializes AngularJS variables |
| ng-model | Binds HTML control's value to a property on the $scope object. |
| ng-controller | Attaches the controller of MVC to the view. |
| ng-bind | Replaces the value of HTML control with the value of specified AngularJS expression. |
| ng-repeat | Repeats HTML template once per each item in the specified collection. |
| ng-show | Display HTML element based on the value of the specified expression. |
| ng-readonly | Makes HTML element read-only based on the value of the specified expression. |
| ng-disabled | Sets the disable attribute on the HTML element if specified expression evaluates to true. |
| ng-if | Removes or recreates HTML element based on an expression. |
| ng-click | Specifies custom behavior when an element is clicked. |
<divng-controller="myController">
{{message}}
</div>
<script>
var ngApp = angular.module('myNgApp', []);
ngApp.controller('myController', function ($scope) {
$scope.message = "Hello World!";
});
</script>
- $scope – inside controller
- $rootscope – overall ngapp
<bodyng-app="myNgApp">
<divng-controller="myController">
Enter Message: <inputtype="text"ng-model="message"/><br/>
<buttonng-click="showMsg(message)">Show Message</button>
</div>
<script>
var ngApp = angular.module('myNgApp', []);
ngApp.controller('myController', function ($scope) {
$scope.message = "Hello World!";
$scope.showMsg = function (msg) {
alert(msg);
};
});
</script>
</body>
- Scope object methods:
The $scope object contains various methods. The following table lists important methods of $scope object.
| Method | Description |
|---|---|
| $new() | Creates new child scope. |
| --- | --- |
| $watch() | Register a callback to be executed whenever model property changes. |
| $watchGroup() | Register a callback to be executed whenever model properties changes. Here, specify an array of properties to be tracked. |
| $watchCollection() | Register a callback to be executed whenever model object or array property changes. |
| $digest() | Processes all of the watchers of the current scope and its children. |
| $destroy() | Removes the current scope (and all of its children) from the parent scope. |
| $eval() | Executes the expression on the current scope and returns the result. |
| $apply() | Executes an expression in angular outside the angular framework. |
| $on() | Register a callback for an event. |
| $emit() | Dispatches the specified event upwards till $rootScope. |
| $broadcast() | Dispatches the specified event downwards to all child scopes. |
- AngularJS event directives.
| Event Directive |
|---|
| ng-blur |
| --- |
| ng-change |
| ng-click |
| ng-dblclick |
| ng-focus |
| ng-keydown |
| ng-keyup |
| ng-keypress |
| ng-mousedown |
| ng-mouseenter |
| ng-mouseleave |
| ng-mousemove |
| ng-mouseover |
| ng-mouseup |
- built-in AngularJS services.
| $anchorScroll | $exceptionHandler | $interval | $rootScope |
|---|---|---|---|
| $animate | $filter | $locale | $sceDelegate |
| $cacheFactory | $httpParamSerializer | $location | $sce |
| $templateCache | $httpParamSerializerJQLike | $log | $templateRequest |
| $compile | $http | $parse | $timeout |
| $controller | $httpBackend | $q | $window |
| $document | $interpolate | $rootElement |
|
1. **$http is a service as an object. It includes following shortcut methods.**
| Method | Description |
|---|---|
| $http.get() | Perform Http GET request. |
| --- | --- |
| $http.head() | Perform Http HEAD request. |
| $http.post() | Perform Http POST request. |
| $http.put() | Perform Http PUT request. |
| $http.delete() | Perform Http DELETE request. |
| $http.jsonp() | Perform Http JSONP request. |
| $http.patch() | Perform Http PATCH request. |
2. **HTTP:**
var promise = $http.get("/demo/getdata").success(onSuccess).error(onError);
$http.post('/demo/submitData', { myData: 'Hello World!' })
.success(onSuccess)
.error(onError);
1. **LOG:**
$log.log('This is log.');
$log.error('This is error.');
$log.info('This is info.');
$log.warn('This is warning.');
$log.debug('This is debugging.');
9.5. Angularjs filters:
{{expression | filterName:parameter }}
| Filter Name | Description |
|---|---|
| Number | Formats a numeric data as text with comma and fraction. |
| --- | --- |
| Currency | Formats numeric data into specified currency format and fraction. |
| Date | Formats date to string in specified format. |
| Uppercase | Converts string to upper case. |
| Lowercase | Converts string to lower case. |
| Filter | Filters an array based on specified criteria and returns new array. |
| orderBy | Sorts an array based on specified predicate expression. |
| Json | Converts JavaScript object into JSON string |
| limitTo | Returns new array containing specified number of elements from an existing array. |
- Modules:
Different files:
app.js:
var myApp = angular.module("myApp", []);
myController.js:
myApp.controller("myController", function ($scope) {
$scope.message = "Hello Angular World!";
});
- Forms:
<form ng-submit** ="submitStudnetForm()"**>
<labelfor="firstName">First Name: </label><br/>
<inputtype="text"id="firstName"ng-model="student.firstName"/><br/>
<labelfor="gender">Gender</label><br/>
<selectid="gender"ng-model="student.gender">
<optionvalue="male">Male</option>
<optionvalue="female">Female</option>
</select><br/><br/>
<inputtype="submit"value="Submit"/>
<inputtype="reset"ng-click="resetForm()"value="Reset"/>
</form>
- AngularJS includes the following validation directives.
| Directive | Description |
|---|---|
| ng-required | Sets required attribute on an input field. |
| --- | --- |
| ng-minlength | Sets minlength attribute on an input field. |
| ng-maxlength | Sets maxlength attribute on an input field. Setting the attribute to a negative or non-numeric value, allows view values of any length. |
| ng-pattern | Sets pattern validation error key if the ngModel value does not match the specified RegEx expression. |
- Route:
var app = angular.module('ngRoutingDemo', ['ngRoute']);
app.config(function ($routeProvider) {
$routeProvider.when('/', {
templateUrl: '/login.html',
controller: 'loginController'
}).when('/student/:username', {
templateUrl: '/student.html',
controller: 'studentController'
}).otherwise({
redirectTo: "/"
});
app.controller("loginController", function ($scope, $location) {
$scope.authenticate = function (username) {
// write authentication code here..
$location.path('/student/' + username)
};
});
app.controller("studentController", function ($scope, $routeParams) {
$scope.username = $routeParams.username;
});
- Exception Handling:
app.config(function ($provide) {
$provide.decorator('$exceptionHandler', function ($delegate) {
return function (exception, cause) {
$delegate(exception, cause);
alert('Error occurred! Please contact admin.');
};
});
});
- Unit Testing
Unit Test
- namespace WebAPI.Tests
- {
-
**using** Microsoft.VisualStudio.TestTools.UnitTesting; -
**using** System.Net.Http; -
**using** System.Web.Http; -
**using** WebAPI.Controllers; -
**using** WebAPI.Models; -
[TestClass] -
publicclassEmployeeUnitTest -
{ -
[TestMethod] -
publicvoid EmployeeGetById() -
{ -
// Set up Prerequisites -
var controller = new EmployeeController(); -
controller.Request = new HttpRequestMessage(); -
controller.Configuration = new HttpConfiguration(); -
// Act on Test -
var response = controller.Get(1); -
// Assert the result -
Employee employee; -
Assert.IsTrue(response.TryGetContentValue \< Employee \> ( **out** employee)); -
Assert.AreEqual("Jignesh", employee.Name); -
} -
} - }
OKNegotiatedContentResult<T> - for HttpAction result
- var response = controller.Get(1);
-
var contentResult = response as OkNegotiatedContentResult\<Department\>; -
// Assert the result -
Assert.IsNotNull(contentResult); -
Assert.IsNotNull(contentResult.Content); -
Assert.AreEqual(1, contentResult.Content.DepartmentId); - Assert.AreEqual("DefaultApi", createdResult.RouteName);
-
Assert.IsNotNull(createdResult.RouteValues["id"]);
Assert.AreEqual(HttpStatusCode.Accepted, contentResult.StatusCode);
NUnit testing: MOK framework
usingMVC5_Testing_1.ModelAccess;
usingNUnit.Framework;
namespaceMVCModelTest
{
[TestFixture]
publicclassCheckDepartmentTest
{
[Test]
publicvoidCheckDepartmentExist()
{
var obj = newDepartmentAccess();
var Res = obj.CheckDeptExist(10);
Assert.That(Res, Is.True);
}
}
}
[Test]
publicvoidCheckDepartmentExistWithMoq()
{
//Create Fake Object
var fakeObject = newMock\<IDepartmentAccess\>();
//Set the Mock Configuration
//The CheckDeptExist() method is call is set with the Integer parameter type
//The Configuration also defines the Return type from the method
fakeObject.Setup(x =\> x.CheckDeptExist(It.IsAny\<int\>())).Returns(true);
//Call the methid
var Res = fakeObject.Object.CheckDeptExist(10);
Assert.That(Res,Is.True);
}
- Design Patterns:
Definition: - design patterns are time tested solution for architecture problems, time tested practices of OOP
Understandable – it helps people learn object-oriented thinking in much better manner.
The 23 Design patterns are defined by the Gang of Four programmers. These 23 patterns are divided into three groups depending on the nature of the design problem they intend to solve.
| OOP Phase | Design pattern category | Example |
|---|---|---|
| Template/class creation problem | Structural design pattern | Structural design patterns are Adapter, Bridge, Composite, Decorator, Facade, Flyweight, Private Class Data, and Proxy. |
| Instantiation problems | Creational design pattern | Creational design patterns are the Factory Method, Abstract Factory, Builder, Singleton, Object Pool, and Prototype. |
| Runtime problems | Behavioral design pattern | Behavioral patterns are Chain of responsibility, Command, Interpreter, Iterator, Mediator, Memento, Null Object, Observer, State, Strategy, Template method, Visitor |
These patterns deal with the composition of objects structures. The concept of inheritance is used to compose interfaces and define various ways to compose objects for obtaining new functionalities. There are as follows:
-
Adapter : Match interfaces of different classes
-
Bridge : Separates an object's abstraction from its implementation
-
Composite : A tree structure of simple and composite objects
-
Decorator : Add responsibilities to objects dynamically
-
Façade : A single class that represents an entire complex system
-
Flyweight : Minimize memory usage by sharing as much data as possible with similar objects
-
Proxy : Provides a surrogate object, which references to other object
These patterns deal with the process of objects creation in such a way that they can be decoupled from their implementing system. This provides more flexibility in deciding which objects need to be created for a given use case/ scenario. There are as follows:
- Factory Method : Create instances of derived classes
- Abstract Factory : Create instances of several classes belonging to different families
- Builder : Separates an object construction from its representation
- Prototype : Create a duplicate object or clone of the object
- Singleton : Ensures that a class can have only one instance
These patterns deal with the process of communication, managing relationships, and responsibilities between objects. There are as follows:
- Chain of Responsibility: Passes a request among a list or chain of objects.
- Command: Wraps a request under an object as a command and passed to invoker object.
- Interpreter: Implements an expression interface to interpret a particular context.
- Iterator: Provides a way to access the elements of a collection object in sequential manner without knowing its underlying structure.
- Mediator: Allows multiple objects to communicate with each other's without knowing each other's structure.
- Memento: Capture the current state of an object and store it in such a manner that it can be restored at a later time without breaking the rules of encapsulation.
- Observer: Allows an object (subject) to publish changes to its state and other objects (observer) that depend upon that object are automatically notified of any changes to the subject's state.
- State: Alters the behavior of an object when it's internal state changes.
- Strategy: Allows a client to choose an algorithm from a family of algorithms at run-time and gives it a simple way to access it.
- Visitor: Creates and performs new operations onto a set of objects without changing the object structure or classes.
- Template Method: Defines the basic steps of an algorithm and allow the implementation of the individual steps to be changed.
Class new instance – use it
Polymorphism – fundamental thing to achieve decoupling.
Simple Factory pattern – it helps centralize object creation and thus decoupling achieved – don't use direct obj creation in app
RIP – Replace IF with polymorphism - enum of customer type based on input type input in string return obj of customer
Lazy loading pattern – load objects on demand
- Differences:
-
Design pattern – code or pseudo code - eg.: Factory, iterator, singleton
-
Architecture pattern – block diagrams – view of diagram – eg.: MVC, MVP, MVVM
-
Architecture style – principles – eg.: REST(representational state transfer – http protocol crud operations), SOA(service oriented architctr)
- Differences:
-
Design pattern – code or pseudo code
- Unity:
Inversion of Control (IoC) is a design principle (although, some people refer to it as a pattern). As the name suggests, it is used to invert different kinds of controls in object-oriented design to achieve loose coupling. Here, controls refer to any additional responsibilities a class has, other than its main responsibility. This include control over the flow of an application, and control over the flow of an object creation or dependent object creation and binding.
- Dependency Injection (DI) is a design pattern used to implement IoC.
Constructor Injection: In the constructor injection, the injector supplies the service (dependency) through the client class constructor.
public CustomerBusinessLogic(ICustomerDataAccess custDataAccess)
{
_dataAccess = custDataAccess;
}
1. Property Injection: In the property injection (aka the Setter Injection), the injector supplies the dependency through a public property of the client class.
publicICustomerDataAccess DataAccess { get; set; }
1. Method Injection: In this type of injection, the client class implements an interface which declares the method(s) to supply the dependency and the injector uses this interface to supply the dependency to the client class.
publicvoid SetDependency(ICustomerDataAccess customerDataAccess)
{
_dataAccess = customerDataAccess;
}
The factory design pattern in C# is used to replace class constructors, abstracting the process of object generation so that the type of the object instantiated can be determined at run-time. In this article, you will learn how to implement Factory Method Design Pattern In C# and .NET.
UML Class Diagram

The classes and objects participating in the above UML class diagram are as follows:
-
Product This defines the interface of objects the factory method creates
-
ConcreteProduct This is a class which implements the Product interface.
-
Creator This is an abstract class and declares the factory method, which returns an object of type Product.
This may also define a default implementation of the factory method that returns a default ConcreteProduct object.
This may call the factory method to create a Product object.
- ConcreteCreator This is a class which implements the Creator class and overrides the factory method to return an instance of a ConcreteProduct.
The classes and objects participating in the above class diagram can be identified as follows:
-
Product - CreditCard
-
ConcreteProduct- MoneyBackCreditCard, TitaniumCreditCard, PlatinumCreditCard
-
Creator- CardFactory
-
ConcreteCreator- MoneyBackCardFactory, TitaniumCardFactory, PlatinumCardFactory
-
using System;
-
namespace FactoryMethodDesignPatternInCSharp
-
{
-
/// \<summary\> -
/// Factory Pattern Demo -
/// \</summary\> -
**public** **class** ClientApplication -
{ -
**static** **void** Main() -
{ -
CardFactory factory = **null** ; -
Console.Write("Enter the card type you would like to visit: "); -
string car = Console.ReadLine(); -
**switch** (car.ToLower()) -
{ -
**case** "moneyback": -
factory = **new** MoneyBackFactory(50000, 0); -
**break** ; -
**case** "titanium": -
factory = **new** TitaniumFactory(100000, 500); -
**break** ; -
**case** "platinum": -
factory = **new** PlatinumFactory(500000, 1000); -
**break** ; -
**default** : -
**break** ; -
} -
CreditCard creditCard = factory.GetCreditCard(); -
Console.WriteLine("\nYour card details are below : \n"); -
Console.WriteLine("Card Type: {0}\nCredit Limit: {1}\nAnnual Charge: {2}", -
creditCard.CardType, creditCard.CreditLimit, creditCard.AnnualCharge); -
Console.ReadKey(); -
} -
}
public class AirConditioner
{
private readonly Dictionary<Actions, AirConditionerFactory> _factories;
public AirConditioner()
{
_factories = new Dictionary<Actions, AirConditionerFactory>();
foreach (Actions action in Enum.GetValues(typeof(Actions)))
{
var factory = (AirConditionerFactory)Activator.CreateInstance(Type.GetType("FactoryMethod." + Enum.GetName(typeof(Actions), action) + "Factory"));
_factories.Add(action, factory);
}
}
}
- Under Creational Pattern
Abstract Factory use Factory design pattern for creating objects. It may also use Builder design pattern and prototype design pattern for creating objects. It completely depends upon your implementation for creating objects.
Abstract Factory patterns act a super-factory which creates other factories. This pattern is also called a Factory of factories. In Abstract Factory pattern an interface is responsible for creating a set of related objects, or dependent objects without specifying their concrete classes.

The classes, interfaces, and objects in the above UML class diagram are as follows:
This is an interface which is used to create abstract product
This is a class which implements the AbstractFactory interface to create concrete products.
This is an interface which declares a type of product.
This is a class which implements the AbstractProduct interface to create a product.
This is a class which uses AbstractFactory and AbstractProduct interfaces to create a family of related objects.
public interface AbstractFactory
{
AbstractProductA CreateProductA();
AbstractProductB CreateProductB();
}
public class ConcreteFactoryA : AbstractFactory
{
public AbstractProductA CreateProductA()
{
return new ProductA1();
}
public AbstractProductB CreateProductB()
{
return new ProductB1();
}
}
public class ConcreteFactoryB : AbstractFactory
{
public AbstractProductA CreateProductA()
{
return new ProductA2();
}
public AbstractProductB CreateProductB()
{
return new ProductB2();
}
}
public interface AbstractProductA { }
public class ProductA1 : AbstractProductA { }
public class ProductA2 : AbstractProductA { }
public interface AbstractProductB { }
public class ProductB1 : AbstractProductB { }
public class ProductB2 : AbstractProductB { }
public class Client
{
private AbstractProductA _productA;
private AbstractProductB _productB;
public Client(AbstractFactory factory)
{
_productA = factory.CreateProductA();
_productB = factory.CreateProductB();
}
}
The classes, interfaces, and objects in the above class diagram can be identified as follows:
- VehicleFactory - AbstractFactory interface
- HondaFactory & HeroFactory - Concrete Factories
- **Bike & Scooter ** - AbstractProduct interface
- **Regular Bike, Sports Bike, Regular Scooter & Scooty ** - Concrete Products
- **VehicleClient ** - Client
/// <summary>
/// Abstract Factory Pattern Demo
/// </summary>
class Program
{
static void Main(string[] args)
{
VehicleFactory honda = new HondaFactory();
VehicleClient hondaclient = new VehicleClient(honda, "Regular");
Console.WriteLine("******* Honda **********");
Console.WriteLine(hondaclient.GetBikeName());
Console.WriteLine(hondaclient.GetScooterName());
hondaclient = new VehicleClient(honda, "Sports");
Console.WriteLine(hondaclient.GetBikeName());
Console.WriteLine(hondaclient.GetScooterName());
VehicleFactory hero = new HeroFactory();
VehicleClient heroclient = new VehicleClient(hero, "Regular");
Console.WriteLine("******* Hero **********");
Console.WriteLine(heroclient.GetBikeName());
Console.WriteLine(heroclient.GetScooterName());
heroclient = new VehicleClient(hero, "Sports");
Console.WriteLine(heroclient.GetBikeName());
Console.WriteLine(heroclient.GetScooterName());
Console.ReadKey();
}
}
Builder pattern builds a complex object by using a step by step approach. Builder interface defines the steps to build the final object. This builder is independent of the objects creation process. A class that is known as Director, controls the object creation process.
Moreover, builder pattern describes a way to separate an object from its construction. The same construction method can create a different representation of the object.

The classes, interfaces, and objects in the above UML class diagram are as follows:
This is an interface which is used to define all the steps to create a product
This is a class which implements the Builder interface to create a complex product.
This is a class which defines the parts of the complex object which are to be generated by the builder pattern.
This is a class which is used to construct an object using the Builder interface.
/// <summary>
/// The 'Builder' interface
/// </summary>
public interface IVehicleBuilder
{
void SetModel();
void SetEngine();
void SetTransmission();
void SetBody();
void SetAccessories();
Vehicle GetVehicle();
}
/// <summary>
/// The 'ConcreteBuilder1' class
/// </summary>
public class HeroBuilder : IVehicleBuilder
{
Vehicle objVehicle = new Vehicle();
public void SetModel()
{
objVehicle.Model = "Hero";
}
public void SetEngine()
{
objVehicle.Engine = "4 Stroke";
}
public void SetTransmission()
{
objVehicle.Transmission = "120 km/hr";
}
public void SetBody()
{
objVehicle.Body = "Plastic";
}
public void SetAccessories()
{
objVehicle.Accessories.Add("Seat Cover");
objVehicle.Accessories.Add("Rear Mirror");
}
public Vehicle GetVehicle()
{
return objVehicle;
}
}
/// <summary>
/// The 'ConcreteBuilder2' class
/// </summary>
public class HondaBuilder : IVehicleBuilder
{
Vehicle objVehicle = new Vehicle();
public void SetModel()
{
objVehicle.Model = "Honda";
}
public void SetEngine()
{
objVehicle.Engine = "4 Stroke";
}
public void SetTransmission()
{
objVehicle.Transmission = "125 Km/hr";
}
public void SetBody()
{
objVehicle.Body = "Plastic";
}
public void SetAccessories()
{
objVehicle.Accessories.Add("Seat Cover");
objVehicle.Accessories.Add("Rear Mirror");
objVehicle.Accessories.Add("Helmet");
}
public Vehicle GetVehicle()
{
return objVehicle;
}
}
/// <summary>
/// The 'Product' class
/// </summary>
public class Vehicle
{
public string Model { get; set; }
public string Engine { get; set; }
public string Transmission { get; set; }
public string Body { get; set; }
public List<string> Accessories { get; set; }
public Vehicle()
{
Accessories = new List<string>();
}
public void ShowInfo()
{
Console.WriteLine("Model: {0}", Model);
Console.WriteLine("Engine: {0}", Engine);
Console.WriteLine("Body: {0}", Body);
Console.WriteLine("Transmission: {0}", Transmission);
Console.WriteLine("Accessories:");
foreach (var accessory in Accessories)
{
Console.WriteLine("\t{0}", accessory);
}
}
}
/// <summary>
/// The 'Director' class
/// </summary>
public class VehicleCreator
{
private readonly IVehicleBuilder objBuilder;
public VehicleCreator(IVehicleBuilder builder)
{
objBuilder = builder;
}
public void CreateVehicle()
{
objBuilder.SetModel();
objBuilder.SetEngine();
objBuilder.SetBody();
objBuilder.SetTransmission();
objBuilder.SetAccessories();
}
public Vehicle GetVehicle()
{
return objBuilder.GetVehicle();
}
}
/// <summary>
/// Builder Design Pattern Demo
/// </summary>
class Program
{
static void Main(string[] args)
{
var vehicleCreator = new VehicleCreator(new HeroBuilder());
vehicleCreator.CreateVehicle();
var vehicle = vehicleCreator.GetVehicle();
vehicle.ShowInfo();
Console.WriteLine("---------------------------------------------");
vehicleCreator = new VehicleCreator(new HondaBuilder());
vehicleCreator.CreateVehicle();
vehicle = vehicleCreator.GetVehicle();
vehicle.ShowInfo();
Console.ReadKey();
}
}
the repository pattern can be implemented, to separate the layers. Our purpose will be to separate the controller and the data access layer (database context) using an intermediate layer, in other words repository layer, for communication between the two.

A generic repository is a generic class, with basic CRUD methods in it (and of course other methods can be added as needed). This class and its member functions can be used for any entity of the database. This means, if we have entities Customers and Orders, this single generic class can be used for both of them.
.
 :
:
 :
:
 And, our controller method to fetch the records will look like the following:
And, our controller method to fetch the records will look like the following:
 :
:

Facade Pattern is used in hiding complexity of large systems and provide simpler interfaces,
A room is a façade and just by looking at it from outside the door, one can not predict what is inside the room and how the room is structured from inside. Thus, Façade is a general term for simplifying the outward appearance of a complex or large system.Facade is a structural design pattern that provides a simplified interface to a library, a framework, or any other complex set of classes.
UML diagram,

Customers place their orders just by talking to the operator and they don't need to bother about how they will prepare the pizza, what all operations will they perform, on what temperature they will cook, etc.
Similarly, in our code sample, we can see that the client is using the restaurant façade class to order pizza and bread of different types without directly interacting with the subclasses.
This is the interface specific to the pizza.
- public interface IPizza {
-
**void** GetVegPizza(); -
**void** GetNonVegPizza(); - }
This is a pizza provider class which will get pizza for their clients. Here methods can have other private methods which client is not bothered about.
- public class PizzaProvider: IPizza {
-
**public** **void** GetNonVegPizza() { -
GetNonVegToppings(); -
Console.WriteLine("Getting Non Veg Pizza."); -
} -
**public** **void** GetVegPizza() { -
Console.WriteLine("Getting Veg Pizza."); -
} -
**private** **void** GetNonVegToppings() { -
Console.WriteLine("Getting Non Veg Pizza Toppings."); -
} - }
Similarly, this is the interface specific for the bread.
- public interface IBread {
-
**void** GetGarlicBread(); -
**void** GetCheesyGarlicBread(); - }
And this is a bread provider class.
- public class BreadProvider: IBread {
-
**public** **void** GetGarlicBread() { -
Console.WriteLine("Getting Garlic Bread."); -
} -
**public** **void** GetCheesyGarlicBread() { -
GetCheese(); -
Console.WriteLine("Getting Cheesy Garlic Bread."); -
} -
**private** **void** GetCheese() { -
Console.WriteLine("Getting Cheese."); -
} - }
Below is the restaurant façade class, which will be used by the client to order different pizzas or breads.
- public class RestaurantFacade {
-
**private** IPizza \_PizzaProvider; -
**private** IBread \_BreadProvider; -
**public** RestaurantFacade() { -
\_PizzaProvider = **new** PizzaProvider(); -
\_BreadProvider = **new** BreadProvider(); -
} -
**public** **void** GetNonVegPizza() { -
\_PizzaProvider.GetNonVegPizza(); -
} -
**public** **void** GetVegPizza() { -
\_PizzaProvider.GetVegPizza(); -
} -
**public** **void** GetGarlicBread() { -
\_BreadProvider.GetGarlicBread(); -
} -
**public** **void** GetCheesyGarlicBread() { -
\_BreadProvider.GetCheesyGarlicBread(); -
} - }
Finally, below is the main method of our program,
- void Main() {
-
Console.WriteLine("----------------------CLIENT ORDERS FOR PIZZA----------------------------\n"); -
var facadeForClient = **new** RestaurantFacade(); -
facadeForClient.GetNonVegPizza(); -
facadeForClient.GetVegPizza(); -
Console.WriteLine("\n----------------------CLIENT ORDERS FOR BREAD----------------------------\n"); -
facadeForClient.GetGarlicBread(); -
facadeForClient.GetCheesyGarlicBread(); - }
WHEN TO USE THIS PATTERN
Use this pattern to simplify the problem when there are multiple complex subsystems and interacting with them individually is really difficult/cumbersome.
REAL LIFE USE CASE – example - Redbus app
- The shopkeeper is a façade for all the items in the shop.
- Online travel portal is a façade for their customers for different holiday/travel packages.
- Customer care is a façade for their customers for different services.
- Ensures a class has only one instance and provides a global point of access to it.
- A singleton is a class that only allows a single instance of itself to be created, and usually gives simple access to that instance.
- Most commonly, singletons don't allow any parameters to be specified when creating the instance, since a second request of an instance with a different parameter could be problematic! (If the same instance should be accessed for all requests with the same parameter then the factory pattern is more appropriate.)
characteristics of a Singleton Pattern.
- A single constructor, that is private and parameterless.
- The class is sealed.
- A static variable that holds a reference to the single created instance, if any.
- A public static means of getting the reference to the single created instance, creating one if necessary.
Advantages of Singleton Pattern
The advantages of a Singleton Pattern are:
- Singleton pattern can be implemented interfaces.
- It can be also inherit from other classes.
- It can be lazy loaded.
- It has Static Initialization.
- It can be extended into a factory pattern.
- It helps to hide dependencies.
- It provides a single point of access to a particular instance, so it is easy to maintain.
Singleton class vs. Static methods
The following conpares Singleton class vs. Static methods:
- A Static Class cannot be extended whereas a singleton class can be extended.
- A Static Class can still have instances (unwanted instances) whereas a singleton class prevents it.
- A Static Class cannot be initialized with a STATE (parameter), whereas a singleton class can be.
- A Static class is loaded automatically by the CLR when the program or namespace containing the class is loaded.
How to Implement Singleton Pattern in your code
There are many way to implement a Singleton Pattern in C#.
- No Thread Safe Singleton.
- Thread-Safety Singleton.
- Thread-Safety Singleton using Double-Check Locking.
- Thread-Safe Singleton without using locks and no lazy instantiation.
- Fully lazy instantiation.
- Using .NET 4's Lazy<T> type.
1. No Thread Safe Singleton
Explanation of the following code:
-
The following code is not thread-safe.
-
Two different threads could both have evaluated the test (if instance == null) and found it to be true, then both creates instances, which violates the singleton pattern.
-
Note that in fact the instance may already have been created before the expression is evaluated, but the memory model doesn't guarantee that the new value of instance will be seen by other threads unless suitable memory barriers have been passed.
-
// Bad code! Do not use!
-
public sealed class Singleton
-
{
-
//Private Constructor. -
**private** Singleton() -
{ -
} -
**private** **static** Singleton instance = **null** ; -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**if** (instance == **null** ) -
{ -
instance = **new** Singleton(); -
} -
**return** instance; -
} -
} -
}
2. Thread Safety Singleton
Explanation of the following code:
-
This implementation is thread-safe.
-
In the following code, the thread is locked on a shared object and checks whether an instance has been created or not.
-
This takes care of the memory barrier issue and ensures that only one thread will create an instance.
-
For example: Since only one thread can be in that part of the code at a time, by the time the second thread enters it, the first thread will have created the instance, so the expression will evaluate to false.
-
The biggest problem with this is performance; performance suffers since a lock is required every time an instance is requested.
-
public sealed class Singleton
-
{
-
Singleton() -
{ -
} -
**private** **static** **readonly** **object** padlock = **new** **object** (); -
**private** **static** Singleton instance = **null** ; -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**lock** (padlock) -
{ -
**if** (instance == **null** ) -
{ -
instance = **new** Singleton(); -
} -
**return** instance; -
} -
} -
} -
}
3. Thread Safety Singleton using Double Check Locking
Explanation of the following code:
-
In the following code, the thread is locked on a shared object and checks whether an instance has been created or not with double checking.
-
public sealed class Singleton
-
{
-
Singleton() -
{ -
} -
**private** **static** **readonly** **object** padlock = **new** **object** (); -
**private** **static** Singleton instance = **null** ; -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**if** (instance == **null** ) -
{ -
**lock** (padlock) -
{ -
**if** (instance == **null** ) -
{ -
instance = **new** Singleton(); -
} -
} -
} -
**return** instance; -
} -
} -
}
4. Thread Safe Singleton without using locks and no lazy instantiation
Explanation of the following code:
-
The preceding implementation looks like very simple code.
-
This type of implementation has a static constructor, so it executes only once per Application Domain.
-
It is not as lazy as the other implementation.
-
public sealed class Singleton
-
{
-
**private** **static** **readonly** Singleton instance = **new** Singleton(); -
// Explicit static constructor to tell C# compiler -
// not to mark type as beforefieldinit -
**static** Singleton() -
{ -
} -
**private** Singleton() -
{ -
} -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**return** instance; -
} -
} -
}
5. Fully lazy instantiation
Explanation of the following code:
-
Here, instantiation is triggered by the first reference to the static member of the nested class, that only occurs in Instance.
-
This means the implementation is fully lazy, but has all the performance benefits of the previous ones.
-
Note that although nested classes have access to the enclosing class's private members, the reverse is not true, hence the need for instance to be internal here.
-
That doesn't raise any other problems, though, as the class itself is private.
-
The code is more complicated in order to make the instantiation lazy.
-
public sealed class Singleton
-
{
-
**private** **static** **readonly** Singleton instance = **new** Singleton(); -
// Explicit static constructor to tell C# compiler -
// not to mark type as beforefieldinit -
**static** Singleton() -
{ -
} -
**private** Singleton() -
{ -
} -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**return** instance; -
} -
} -
}
6. Using .NET 4's Lazy<T> type
Explanation of the following code:
-
If you're using .NET 4 (or higher) then you can use the System.Lazy<T> type to make the laziness really simple.
-
All you need to do is pass a delegate to the constructor that calls the Singleton constructor, which is done most easily with a lambda expression.
-
It also allows you to check whether or not the instance has been created with the IsValueCreated property.
-
public sealed class Singleton
-
{
-
**private** Singleton() -
{ -
} -
**private** **static** **readonly** Lazy\<Singleton\> lazy = **new** Lazy\<Singleton\>(() =\> **new** Singleton()); -
**public** **static** Singleton Instance -
{ -
**get** -
{ -
**return** lazy.Value; -
} -
} -
}
In Object Oriented Programming (OOP), SOLID is an acronym, introduced by Michael Feathers, for five design principles used to make software design more understandable, flexible, and maintainable.
There are five SOLID principles:
- Single Responsibility Principle (SRP)
- Open Closed Principle (OCP)
- Liskov Substitution Principle (LSP)
- Interface Segregation Principle (ISP)
- Dependency Inversion Principle (DIP)
Definition: A class should have only one reason to change.
In layman terminology, this means that a class should not be loaded with multiple responsibilities and a single responsibility should not be spread across multiple classes or mixed with other responsibilities. The reason is that more changes requested in the future, the more changes the class need to apply.
In simple terms, a module or class should have a very small piece of responsibility in the entire application. Or as it states, a class/module should have not more than one reason to change.
If a class has only a single responsibility, it is likely to be very robust. It's easy to verify its working as per logic defined. And it's easy to change in class as it has single responsibility.
The Single Responsibility Principle provides another benefit. Classes, software components and modules that have only one responsibility are much easier to explain, implement and understand than ones that give a solution for everything.
This also reduces number of bugs and improves development speed and most importantly makes developer's life lot easier.
Definition: Software entities (classes, modules, functions, etc.) should be open for extension, but closed for modification.
This principle suggests that the class should be easily extended but there is no need to change its core implementations.
The application or software should be flexible to change. How change management is implemented in a system has a significant impact on the success of that application/ software. The OCP states that the behaviors of the system can be extended without having to modify its existing implementation.
i.e. New features should be implemented using the new code, but not by changing existing code. The main benefit of adhering to OCP is that it potentially streamlines code maintenance and reduces the risk of breaking the existing implementation.
Let's take an example of bank accounts like regular savings, salary saving, corporate etc. for different customers. As for each customer type, there are different rules and different interest rates. The code below violates OCP principle if the bank introduces a new Account type. Said code modifies this method for adding a new account type.
We can apply OCP by using interface, abstract class, abstract methods and virtual methods when you want to extend functionality. Here I have used interface for example only but you can go as per your requirement.
interface IAccount
{
// members and function declaration, properties
decimal Balance { get; set; }
decimal CalcInterest();
}
//regular savings account
public class RegularSavingAccount : IAccount
{
public decimal Balance { get; set; } = 0;
public decimal CalcInterest()
{
decimal Interest = (Balance * 4) / 100;
if (Balance < 1000) Interest -= (Balance * 2) / 100;
if (Balance < 50000) Interest += (Balance * 4) / 100;
return Interest;
}
}
//Salary savings account
public class SalarySavingAccount : IAccount
{
public decimal Balance { get; set; } = 0;
public decimal CalcInterest()
{
decimal Interest = (Balance * 5) / 100;
return Interest;
}
}
//Corporate Account
public class CorporateAccount : IAccount
{
public decimal Balance { get; set; } = 0;
public decimal CalcInterest()
{
decimal Interest = (Balance * 3) / 100;
return Interest;
}
}
In the above code three new classes are created; regular saving account, SalarySavingAccount, and CorporateAccount, by extending them from IAccount.
This solves the problem of modification of class and by extending interface, we can extend functionality.
Above code is implementing both OCP and SRP principle, as each class has single is doing a single task and we are not modifying class and only doing an extension.
Definition by Robert C. Martin: Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.
The Liskov substitution principle (LSP) is a definition of a subtyping relation, called (strong) behavioral subtyping, that was initially introduced by Barbara Liskov in a 1987 conference keynote address titled Data abstraction and hierarchy.
LSP states that the child class should be perfectly substitutable for their parent class. If class C is derived from P then C should be substitutable for P.
We can check using LSP that inheritance is applied correctly or not in our code.
LSP is a fundamental principle of SOLID Principles and states that if program or module is using base class then derived class should be able to extend their base class without changing their original implementation.
Let's consider the code below where LSP is violated. We cannot simply substitute a Triangle, which results in printing shape of a triangle, with Circle.
namespace Demo
{
public class Program
{
static void Main(string[] args)
{
Triangle triangle = new Circle();
Console.WriteLine(triangle.GetColor());
}
}
public class Triangle
{
public virtual string GetShape()
{
return " Triangle ";
}
}
public class Circle : Triangle
{
public override string GetShape()
{
return "Circle";
}
}
}
To correct above implementation, we need to refactor this code by introducing interface with method called GetShape.
namespace Demo
{
class Program
{
static void Main(string[] args)
{
Shape shape = new Circle();
Console.WriteLine(shape.GetShape());
shape = new Triangle ();
Console.WriteLine(shape.GetShape());
}
}
public abstract class Shape
{
public abstract string GetShape();
}
public class Triangle: Fruit
{
public override string GetShape()
{
return "Triangle";
}
}
public class Circle : Triangle
{
public override string GetShape()
{
return "Circle";
}
}
}
Definition: No client should be forced to implement methods which it does not use, and the contracts should be broken down to thin ones.
Interface segregation principle is required to solve the design problem of the application. When all the tasks are done by a single class or in other words, one class is used in almost all the application classes then it has become a fat class with overburden. Inheriting such class will results in having sharing methods which are not relevant to derived classes but its there in the base class so that will inherit in the derived class.
Using ISP, we can create separate interfaces for each operation or requirement rather than having a single class to do the same work.
In below code, ISP is broken as process method is not required by OfflineOrder class but is forced to implement.
public interface IOrder
{
void AddToCart();
void CCProcess();
}
public class OnlineOrder : IOrder
{
public void AddToCart()
{
//Do Add to Cart
}
public void CCProcess()
{
//process through credit card
}
}
public class OfflineOrder : IOrder
{
public void AddToCart()
{
//Do Add to Cart
}
public void CCProcess()
{
//Not required for Cash/ offline Order
throw new NotImplementedException();
}
}
We can resolve this violation by dividing IOrder Interface.
public interface IOrder
{
void AddToCart();
}
public interface IOnlineOrder
{
void CCProcess();
}
public class OnlineOrder : IOrder, IOnlineOrder
{
public void AddToCart()
{
//Do Add to Cart
}
public void CCProcess()
{
//process through credit card
}
}
public class OfflineOrder : IOrder
{
public void AddToCart()
{
//Do Add to Cart
}
}
This principle is about dependencies among components. The definition of DIP is given by Robert C. Martin is as follows:
- High-level modules should not depend on low-level modules. Both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
The principle says that high-level modules should depend on abstraction, not on the details, of low-level modules. In simple words, the principle says that there should not be a tight coupling among components of software and to avoid that, the components should depend on abstraction.
The terms Dependency Injection (DI) and Inversion of Control (IoC) are generally used as interchangeably to express the same design pattern. The pattern was initially called IoC, but Martin Fowler (known for designing the enterprise software) anticipated the name as DI because all frameworks or runtime invert the control in some way and he wanted to know which aspect of control was being inverted.
Inversion of Control (IoC) is a technique to implement the Dependency Inversion Principle in C#. Inversion of control can be implemented using either an abstract class or interface. The rule is that the lower level entities should join the contract to a single interface and the higher-level entities will use only entities that are implementing the interface. This technique removes the dependency between the entities.
In below implementation, I have used interface as a reference, but you can use abstract class or interface as per your requirement.
In below code, we have implemented DIP using IoC using injection constructor. There are different ways to implement Dependency injection. Here, I have use injection thru constructor but you inject the dependency into class's constructor (Constructor Injection), set property (Setter Injection), method (Method Injection), events, index properties, fields and basically any members of the class which are public.
public interface IAutomobile
{
void Ignition();
void Stop();
}
public class Jeep : IAutomobile
{
#region IAutomobile Members
public void Ignition()
{
Console.WriteLine("Jeep start");
}
public void Stop()
{
Console.WriteLine("Jeep stopped.");
}
#endregion
}
public class SUV : IAutomobile
{
#region IAutomobile Members
public void Ignition()
{
Console.WriteLine("SUV start");
}
public void Stop()
{
Console.WriteLine("SUV stopped.");
}
#endregion
}
public class AutomobileController
{
IAutomobile m_Automobile;
public AutomobileController(IAutomobile automobile)
{
this.m_Automobile = automobile;
}
public void Ignition()
{
m_Automobile.Ignition();
}
public void Stop()
{
m_Automobile.Stop();
}
}
class Program
{
static void Main(string[] args)
{
IAutomobile automobile = new Jeep();
//IAutomobile automobile = new SUV();
AutomobileController automobileController = new AutomobileController(automobile);
automobile.Ignition();
automobile.Stop();
Console.Read();
}
}
- MVC:
MVC stands for Model, View and Controller. MVC separates application into three components - Model, View and Controller.
-
Model: Model represents shape of the data and business logic. It maintains the data of the application. Model objects retrieve and store model state in a database.
-
Model is a data and business logic.
-
View: View is a user interface. View display data using model to the user and also enables them to modify the data.
-
View is a User Interface.
-
Controller: Controller handles the user request. Typically, user interact with View, which in-turn raises appropriate URL request, this request will be handled by a controller. The controller renders the appropriate view with the model data as a response.
- ActionResult
| Result Class | Description |
|---|---|
| ViewResult | Represents HTML and markup. |
| --- | --- |
| EmptyResult | Represents No response. |
| ContentResult | Represents string literal. |
| FileContentResult/FilePathResult/ FileStreamResult | Represents the content of a file |
| JavaScriptResult | Represent a JavaScript script. |
| JsonResult | Represent JSON that can be used in AJAX |
| RedirectResult | Represents a redirection to a new URL |
| RedirectToRouteResult | Represent another action of same or other controller |
| PartialViewResult | Returns HTML from Partial view |
| HttpUnauthorizedResult | Returns HTTP 403 status |
- Action verbs:
| Http method | Usage |
|---|---|
| GET | To retrieve the information from the server. Parameters will be appended in the query string. |
| --- | --- |
| POST | To create a new resource. |
| PUT | To update an existing resource. |
| HEAD | Identical to GET except that server do not return message body. |
| OPTIONS | OPTIONS method represents a request for information about the communication options supported by web server. |
| DELETE | To delete an existing resource. |
| PATCH | To full or partial update the resource. |
- ViewData VS ViewBag VS TempData:
| ViewData | ViewBag | TempData |
|---|---|---|
| It is Key-Value Dictionary collection | It is a type object | It is Key-Value Dictionary collection |
| ViewData is a dictionary object and it is property of ControllerBase class | ViewBag is Dynamic property of ControllerBase class. | TempData is a dictionary object and it is property of controllerBase class. |
| ViewData is Faster than ViewBag | ViewBag is slower than ViewData | NA |
| ViewData is introduced in MVC 1.0 and available in MVC 1.0 and above | ViewBag is introduced in MVC 3.0 and available in MVC 3.0 and above | TempData is also introduced in MVC1.0 and available in MVC 1.0 and above. |
| ViewData also works with .net framework 3.5 and above | ViewBag only works with .net framework 4.0 and above | TempData also works with .net framework 3.5 and above |
| Type Conversion code is required while enumerating | In depth, ViewBag is used dynamic, so there is no need to type conversion while enumerating. | Type Conversion code is required while enumerating |
| Its value becomes null if redirection has occurred. | Same as ViewData | TempData is used to pass data between two consecutive requests. |
| It lies only during the current request. | Same as ViewData | TempData only works during the current and subsequent request |
In the case of the MVC internal DynamicViewDataDictionary class - it ultimately ends up binding to this:
publicoverrideboolTryGetMember(GetMemberBinder binder, outobject result)
{
result = this.ViewData[binder.Name];
returntrue;
}
For var a = ViewBag.Foo
And
publicoverrideboolTrySetMember(SetMemberBinder binder, object value)
{
this.ViewData[binder.Name] = value;
returntrue;
}
For ViewBag.Foo = Bar;
In other words - the statements are effectively being rewritten to wrappers around the dictionary indexer.
Because of that, there's certainly no way it could be faster than doing it yourself.
Tempdata – peek and keep
-
Peek – reads it and mark it for non deletion
-
Keep – mark it for non deletion.
-
Just read tempdata it will mark it for deletion.
- Web api
- http protocol
- controller – action – routing
- (GET/POST/PUT/PATCH/DELETE)
Eg:
[HttpPost]
publicvoid SaveNewValue([FromBody]stringvalue)
{
}
Codes are grouped into five categories based upon the first number.
| S. No. | HTTP Status Code | Description |
|---|---|---|
| 1. | 1XX | Informational |
| 2. | 2XX | Success |
| 3. | 3XX | Redirection |
| 4. | 4XX | Client-Side Error |
| 5. | 5XX | Server-Side Error |
Table: HTTP Status Code with Description
Some of the commonly seen HTTP Status Codes are: 200 (Request is Ok), 201 (Created), 202 (Accepted), 204 (No Content), 301 (Moved Permanently), 400 (Bad Request), 401 (Unauthorized), 403 (Forbidden), 404 (Not Found), 500 (Internal Server Error), 502 (Bad Gateway), 503 (Service Unavailable) etc.
1. Difference between Web API and MVC controller
| Web API Controller | MVC Controller |
|---|---|
| Derives from System.Web.Http.ApiController class | Derives from System.Web.Mvc.Controller class. |
| --- | --- |
| Method name must start with Http verbs otherwise apply http verbs attribute. | Must apply appropriate Http verbs attribute. |
| Specialized in returning data. | Specialized in rendering view. |
| Return data automatically formatted based on Accept-Type header attribute. Default to json or xml. | Returns ActionResult or any derived type. |
| Requires .NET 4.0 or above | Requires .NET 3.5 or above |
1. ASP.NET Web API vs WCF
| Web API | WCF |
|---|---|
| Open source and ships with .NET framework. | Ships with .NET framework |
| --- | --- |
| Supports only HTTP protocol. | Supports HTTP, TCP, UDP and custom transport protocol. |
| Maps http verbs to methods | Uses attributes based programming model. |
| Uses routing and controller concept similar to ASP.NET MVC. | Uses Service, Operation and Data contracts. |
| Does not support Reliable Messaging and transaction. | Supports Reliable Messaging and Transactions. |
| Web API can be configured using HttpConfiguration class but not in web.config. | Uses web.config and attributes to configure a service. |
| Ideal for building RESTful services. | Supports RESTful services but with limitations. |
-
OData
-
The Open Data Protocol (OData) is a data access protocol for the web. OData provides a uniform way to query and manipulate data sets through CRUD operations (create, read, update, and delete).
-
OData defines parameters that can be used to modify an OData query. The client sends these parameters in the query string of the request URI. For example, to sort the results, a client uses the $orderby parameter:
-
The OData specification calls these parameters query options. You can enable OData query options for any Web API controller in your project — the controller does not need to be an OData endpoint. This gives you a convenient way to add features such as filtering and sorting to any Web API application.
- Web API 5.2
- OData v4
- Visual Studio 2017 (download Visual Studio 2017 here)
- Entity Framework 6
- .NET 4.7.2
Open the file App_Start/WebApiConfig.cs. Add the following using statements:
C#Copy
using ProductService.Models;
using Microsoft.AspNet.OData.Builder;
using Microsoft.AspNet.OData.Extensions;
Then add the following code to the Register method:
C#Copy
publicstaticclassWebApiConfig
{
publicstaticvoidRegister(HttpConfiguration config)
{
// New code:
ODataModelBuilder builder = new ODataConventionModelBuilder();
builder.EntitySet<Product>("Products");
config.MapODataServiceRoute(
routeName: "ODataRoute",
routePrefix: null,
model: builder.GetEdmModel());
}
}
public** class **ProductsController : ODataController
publicasync Task<IHttpActionResult> Patch([FromODataUri] int key, Delta<Product> product)
{
OData supports two different semantics for updating an entity, PATCH and PUT.
-
PATCH performs a partial update. The client specifies just the properties to update.
-
PUT replaces the entire entity.
- Query Options
The following are the OData query options that ASP.NET WebAPI supports:
- $orderby: Sorts the fetched record in particular order like ascending or descending.
$orderby=ProductName asc
- $select: Selects the columns or properties in the result set. Specifies which all attributes or properties to include in the fetched result.
- $skip: Used to skip the number of records or results. For example, I want to skip first 100 records from the database while fetching complete table data, then I can make use of $skip.
$orderby=ProductName asc &$skip=6
- $top: Fetches only top n records. For e.g. I want to fetch top 10 records from the database, then my particular service should be OData enabled to support $top query option. - "? $top=2"
$orderby=ProductId asc&$top=5
- $expand: Expands the related domain entities of the fetched entities.
- $filter: Filters the result set based on certain conditions, it is like where clause of LINQ. For e.g. I want to fetch the records of 50 students who have scored more than 90% marks, and then I can make use of this query option.
$filter=ProductName eq 'computer'
$filter=ProductId ge 3 and ProductId le 5
$filter=substringof('IPhone',ProductName)
- $inlinecount: This query option is mostly used for pagination at client side. It tells the count of total entities fetched from the server to the client.
[Queryable]
[GET("allproducts")]
[GET("all")]
public HttpResponseMessage Get()
{
var products = _productServices.GetAllProducts().AsQueryable();
var productEntities = products as List<ProductEntity> ?? products.ToList();
if (productEntities.Any())
returnRequest.CreateResponse(HttpStatusCode.OK, productEntities.AsQueryable());
throw new ApiDataException(1000, "Products not found", HttpStatusCode.NotFound);
}
- Standard filter operators
The Web API supports the standard OData filter operators listed in the following table.
| Operator | Description | Example |
|---|---|---|
| Comparison Operators | ||
| --- | ||
| Eq | Equal | $filter=revenue eq 100000 |
| Ne | Not Equal | $filter=revenue ne 100000 |
| Gt | Greater than | $filter=revenue gt 100000 |
| Ge | Greater than or equal | $filter=revenue ge 100000 |
| Lt | Less than | $filter=revenue lt 100000 |
| Le | Less than or equal | $filter=revenue le 100000 |
| Logical Operators | ||
| And | Logical and | $filter=revenue lt 100000 and revenue gt 2000 |
| Or | Logical or | $filter=contains(name,'(sample)') or contains(name,'test') |
| Not | Logical negation | $filter=not contains(name,'sample') |
| Grouping Operators | ||
| ( ) | Precedence grouping | (contains(name,'sample') or contains(name,'test')) and revenue gt 5000 |
- Standard query functions
The web API supports these standard OData string query functions.
| Function | Example |
|---|---|
| contains | $filter=contains(name,'(sample)') |
| --- | --- |
| endswith | $filter=endswith(name,'Inc.') |
| startswith | $filter=startswith(name,'a') |
Paging:
[Queryable(PageSize = 10)]
- Query Constraints:
[Queryable(AllowedQueryOptions =AllowedQueryOptions.Filter | AllowedQueryOptions.OrderBy)]
[GET("allproducts")]
[GET("all")]
public HttpResponseMessage Get()
- ABC in WCF:
-
Address: This lets you know the location on server. Different bindings support different address types.
-
Binding: Defines which protocol is being used.
-
Contract: This defines each method exposed from service.
- Contract:
-
ServiceContract
-
OperationContract
-
DataContract
-
MessageContract
- BINDING:
-
HTTP-based: If we want our service to be accessed across multiple OS or multiple programming architectures, HTTP based bindings are our obvious choice. Let's see the bindings supported.
- BasicHttpBinding: It is used in case of web service, offers backward compatibility, the message encoding used is Text/XML, supports WS-basic profile.
- WsHttpBinding: It gives all functionality which BasicHttpBinding offers, apart from that it offers transaction support, reliable message and WS-Addressing.
- WSDualHttpBinding: Offers all functionality offered by WsHttpBinding, but the main purpose is to be used with duplex communication.
- WsFederationHttpBinding: This is used when security within the organization is the most important aspect.
-
TCP-based: If we want to share the data in compact binary format, these bindings are of best use.
- NetNamedPipeBinding: This is best binding to be used if our service and client both are hosted on the same machine, use TCP protocol to exchange data. It supports transaction, reliable session and secure communication.
- NetPeerTcpBinding: This binding provided secure binding for P2P network, offers all functionality fro NetNamedPipeBinding.
- NetTcpBinding: Used for secure and optimized binding for cross-machine communication between .NET application.
-
MSMQ-based: If we want to use MSMQ server to exchange data, we can use these bindings:
- MsmqIntegrationBinding: We can use this binding to send and receive data from existing MSMQ applications that use COM, C++.
- NetMsmqBinding: This is used to communicate between cross-machine using queue. This is preferred binding when using MSMQ.
- Exception handling:
Wcf exception handling – fault exception
Wep api exception handling – custom exception
1.What are different parameters to consider the database performance of Application?
Answer:
There are lot of parameters to consider the performance of application:
1.What size of images we are using in application.The images we are using on application should not be maximum size.
2.What is the data volume used to fetch the data
3.Data cardinality: The most important factor is data cardinality of the data in application.Data should be divided in proper manner and the database should be in well normalized form
4.Indexing done:Indexing should be done properly in database (Click here for index info)
2.What are indexes in SQL?(90 % asked in Performance Tuning Interview Questions)
Answer:
Learn more
_" Index is optional structure associated with the table which may or may not improve the performance of Query" _
In simple words suppose we want to search the topic in to book we go to index page of that book and search the topic which we want.Just like that to search the values from the table when indexing is there you need not use the full table scan.
Click Here to Get 20 most important complex sql queries…
3.What are advantages of Indexes?
Answer:
Indexes are memory objects which are used to improve the performance of queries which allows faster retrieval of records.
Following are advantages of Indexes:
1.It allows faster retrieval of data
2.It avoids the Full table scan so that the performance of retrieving data from the table is faster.
3.It avoids the table access alltogether
4.Indexes always speeds up the select statement.
5.Indexes used to improve the Execution plan of the database
4.What are disadvantages of Indexes?(80 % asked in Performance Tuning Interview Questions)
Disadvantages:
1.Indexes slows down the performance of insert and update statements.So always we need follow best practice of disabling indexes before insert and update the table
2.Indexes takes additional disk space so by considering memory point indexes are costly.
5.What is parser?
Answer:
When SQL Statement has been written and generated then first step is parsing of that SQL Statement.Parsing is nothing but checking the syntaxes of SQL query.All the syntax of Query is correct or not is checked by SQL Parser.
There are 2 functions of parser:
1.Syntax analysis
2.Semantic analysis
Click Here to know more about Parser….
6.What are functions of Parser?
1.Syntax Analysis:
The parser checks for SQL statement syntaxs.If the syntax is incorrect then parser gives the incorrect syntax error.
2.Semantic Analysis:
This checks for references of object and object attributes referenced are correct.
7.What is mean by implicit index.Explain with example.
Answer:
Whenever we define unique key or primary key constraints on the table the index will automatically create on the table.These indexes are known as implicit indexes because these are created implicitly whenever the constraint has been applied to the table.These indexes are normal indexes not unique indexes.The indexes are normal because the columns already have defined as unique so uniqueness is already been applied.
Example:
Create table Employee
(Employee_ID varchar2(20) primary key,
Employee name varchar2(50),
salary number(10,0) not null);
If We check description of table:
_ Desc Employee; _
Name Null Type
——————————————–
Employee_ID not null varchar2
Employee_name varchar2
Salary not null number
Here you will see index is already created for Employee_ID as it has defined primary key.
Click Here to get information about indexes….
8.What are Explicit Indexes?
Answer:
The indexes which is created by user are called as explicit indexes.You can say the indexes which are created by 'Create Index' statement are called as Explicit indexes.
_ Syntax: _
create index indexname on tablename(columnname);
_ Example: _
Create index IND_Employee_ID on Employee(Employee_ID);
9.What are different types of indexes?
Answer:
There are following types of indexes:
1.Normal Indexes
2.Bit map indexes
3.B-tree Indexes
4.Unique Indexes
5.Function Based Indexes
10.What is mean by Unique Indexes?
Answer:
1.To create unique index you must have CREATE ANY INDEX privilege.Here the concept is bit different.User needs to check the values of the table to create unique index.If table contains uniquely identified values in specified column then you should use unique index.
2.Especially while creating the table if we specify the primary key then unique index is automatically created on that column.
3.But for Unique key constaint columns you separately need to do indexing.Kindly make sure that Unique key indexes created on the columns which has unique values only.
4.The unique indexes are also called as clustered indexes when primary key is defined on the column.
Example:
Create Unique index Index_name on Table_name(Unique column name);
_ Example: _
CREATE UNIQUE INDEX UI1_EMP on EMP(EMP_ID);
Click Here to get information on basics of Performance Tuning..
11.What are functional Based indexes?Explain with Example
Answer:
1.Function based indexes allows us to index on the functional columns so that oracle engine will take the index and improves the performance of the query.
2.As per requirements we are using lot of SQL functions to fetch the results.Function based indexs gives ability to index the computed columns.
3.Function based indexes are easy to implement and it also provides immediate value.These indexes speeds up the application without changing application code or query.
_ Example: _
_ Syntax: _
Create index indexname on tablename(Function_name(column_name));
_ Example: _
Create index FI_Employee on Employee(trunc(Hire_date));
12.What is Bit-map index?Explain with Example.(90 % Asked in Performance Tuning Interview Questions)
Answer:
1.If Table contains the distinct values which are not more than 20 distinct values then user should go for Bit map indexes.
2.User should avoid the indexing on each and every row and do the indexing only on distinct records of the table column.You should able to check drastic change in query cost after changing the normal index to Bit map index.
3.The bit map indexes are very much useful in dataware housing where there are low level of concurrent transactions.Bit map index stores row_id as associated key value with bitmap and did the indexing only distinct values.
4.Means If in 1 million records only 20 distinct values are there so Bitmap index only stores 20 values as bitmap and fetches the records from that 20 values only.
_ Syntax: _
Create bitmap index Index_name on Table_name(Columns which have distinct values);
_ Example: _
CREATE BITMAP index BM_DEPT_NAME on DEPT(Department_name);
13.What is Optimizer?
Answer:
Optimizer is nothing but the execution of query in optimum manner.Optimizer is most efficient way of processing the query.SQL parser ,SQL Optimizer and source code generator compiles the SQL statement.
14.What are types of SQL Optimizer?
Answer:
There are following types of optimizer:
1.Rule Based Optimizer
2.Cost Based Optimizer
15.Explain Rule Based Optimizer?
Answer:
When we execute any SQL statement ,the optimizer uses the predefined rules which defines what indexes are present in the database and which indexes needs to be executed during the execution.Rule Based optimizer is used to specify which table is been full scanned and which tables are taking the indexes during the execution.In Earlier the only optimizer which is used by Oracle is Rule Based optimizer
_" Rule Based Optimizer specifies the rules for how to execute the query." _
16.What is composite index?(90% asked in Performance Tuning Interview Questions)
Answer:
When 2 or more columns are related to each other in the table and the same columns are used in where condition of the query then user can create index on both columns.These indexes are known as composite indexes.
Example:
Create index CI_Employee on Employee(Eno,Deptno);
17.What is cost based optimizer?
Answer:
Cost Based Optimizer (CBO) uses the artificial intelligence to execute the Query. The Optimizer itself decides the execution plan based on the cost of query. The cost based method means the database must decide which query execution plan to choose. It decides the query execution plan by deciding the statistical information based on the database objects.(tables, indexes and clusters).The Oracle cost based optimizer is designed to determine the most effective way to carry out the SQL statement.
_" Cost based optimizer considers the statastical information of the table for query execution" _
Click here to get most important questions asked in Tech Mahindra..
17.What is visible/invisible property of index?
Answer:
User can make the indexes visible and invisible by altering the indexes.Following statement is used to make indexes visible and invisible.
ALTER INDEX index_name VISIBLE;
18.What is mean by Clustered index?
Answer:
1.The clustered indexes are indexes which are physically stored in order means it stores in ascending or descending order in Database.
2.Clustered indexes are created once for each table.When primary key is created then clustered index has been automatically created in the table.
3.If table is under heavy data modifications the clustered indexes are preferable to use.
19.Can Index be Renamed?If Yes How?(90% asked inPerformance Tuning Interview Questions)
Answer:
Yes we can rename the indexes.User should have create any index privilege to rename the index.
Alter index Index_name Rename to New_indexname;
20.What is mean by non clustered indexes?(90 % asked in Performance Tuning Interview Questions)
Answer:
1.The clustered indexes are used for searching purpose as we can create clustered indexes where primary is is defined.But Non clustered indexes are indexes which will be created on the multiple joining conditions,multiple filters used in query.
2.We can create 0 to 249 non-clustered indexes on single table.Foreign keys should be non clustered.
3.When user wants to retrieve heavy data from fields other than primary key the non clustered indexes are useful.
Q:-1. What is SQL Query Optimization?
Ans. Query Optimization is the process of writing the query in a way so that it could execute quickly. It is a significant step for any standard application.
Q:-2. What are some tips to improve the performance of SQL queries?
Ans. Optimizing SQL queries can bring substantial positive impact on the performance. It also depends on the level of RDBMS knowledge you have. Let's now go over some of the tips for tuning SQL queries.
-
Prefer to use views and stored procedures in spite of writing long queries. It'll also help in minimizing network load.
-
It's better to introduce constraints instead of triggers. They are more efficient than triggers and can increase performance.
-
Make use of table-level variables instead of temporary tables.
-
The UNION ALL clause responds faster than UNION. It doesn't look for duplicate rows whereas the UNION statement does that regardless of whether they exist or not.
-
Prevent the usage of DISTINCT and HAVING clauses.
-
Avoid excessive use of SQL cursors.
-
Make use of SET NOCOUNT ON clause while building stored procedures. It represents the rows affected by a T-SQL statement. It would lead to reduced network traffic.
-
It's a good practice to return the required column instead of all the columns of a table.
-
Prefer not to use complex joins and avoid disproportionate use of triggers.
-
Create indexes for tables and adhere to the standards.
Q:-3. What are the bottlenecks that affect the performance of a Database?
Ans. In a web application, the database tier can prove to be a critical bottleneck in achieving the last mile of scalability. If a database has performance leakage, that can become a bottleneck and likely to cause the issue. Some of the common performance issues are as follows.
-
Abnormal CPU usage is the most obvious performance bottleneck. However, you can fix it by extending CPU units or replacing with an advanced CPU. It may look like a simple issue but abnormal CPU usage can lead to other problems.
-
Low memory is the next most common bottleneck. If the server isn't able to manage the peak load, then it poses a big question mark on the performance. For any application, memory is very critical to perform as it's way faster than the persistent memory. Also, when the RAM goes down to a specific threshold, then the OS turns to utilize the swap memory. But it makes the application to run very slow.
You can resolve it by expanding the physical RAM, but it won't solve memory leaks if there is any. In such a case, you need to profile the application to identify the potential leaks within its code.
- Too much dependency on external storage like SATA disk could also come as a bottleneck. Its impact gets visible while writing large data to the disk. If output operations are very slow, then it is a clear indication an issue becoming the bottleneck.
In such cases, you need to do scaling. Replace the existing drive with a faster one. Try upgrading to an SSD hard drive or something similar.
Q:-4. What are the steps involved in improving the SQL performance?
Ans.
Discover – First of all, find out the areas of improvement. Explore tools like Profiler, Query execution plans, SQL tuning advisor, dynamic views, and custom stored procedures.
Review – Brainstorm the data available to isolate the main issues.
Propose – Here is a standard approach one can adapt to boost the performance. However, you can customize it further to maximize the benefits.
- Identify fields and create indexes.
- Modify large queries to make use of indexes created.
- Refresh table and views and update statistics.
- Reset existing indexes and remove unused ones.
- Look for dead blocks and remove them.
Validate – Test the SQL performance tuning approach. Monitor the progress at a regular interval. Also, track if there is any adverse impact on other parts of the application.
Publish – Now, it's time to share the working solution with everyone in the team. Let them know all the best practices so that they can use it with ease.
Q:-5. What is a explain plan?
Ans. It's a term used in Oracle. And it is a type of SQL clause in Oracle which displays the execution plan that its optimizer plans for executing the SELECT/UPDATE/INSERT/DELETE statements.
Q:-6. How do you analyze an explain plan?
Ans. While analyzing the explain plan, check the following areas.
- Driving Table
- Join Order
- Join Method
- Unintentional cartesian product
- Nested loops, merge sort, and hash join
- Full Table Scan
- Unused indexes
- Access paths
Q:-7. How do you tune a query using the explain plan?
Ans. The explain plan shows a complete output of the query costs including each subquery. The cost is directly proportional to the query execution time. The plan also depicts the problem in queries or sub-queries while fetching data from the query.
Q:-8. What is Summary advisor and what type of information does it provide?
Ans. Summary advisor is a tool for filtering and materializing the views. It can help in elevating the SQL performance by selecting the proper set of materialized views for a given workload. And it also provides data about the Materialized view recommendations.
Q:-9. What could most likely cause a SQL query to run as slow as 5 minutes?
Ans. Most probably, a sudden surge in the volume of data in a particular table could slow down the output of a SQL query. So collect the required stats for the target table. Also, monitor any change in the DB level or within the underlying object level.
Q:-10. What is a Latch Free Event? And when does it occur? Alos, how does the system handles it?
Ans. In Oracle, Latch Free wait event occurs when a session requires a latch, attempts to get it but fails because someone else has it.
So it sleeps with a wait eying for the latch to get free, wakes up and tries again. The time duration for it was inactive is the wait time for Latch Free. Also, there is no ordered queue for the waiters on a latch, so the one who comes first gets it.
Q:-11. What is Proactive tuning and Reactive tuning?
Ans.
Proactive tuning – The architect or the DBA determines which combination of system resources and available Oracle features fulfill the criteria during Design and Development.
Reactive tuning – It is the bottom-up approach to discover and eliminate the bottlenecks. The objective is to make Oracle respond faster.
Q:-12. What are Rule-based Optimizer and Cost-based Optimizer?
Ans. Oracle determines how to get the required data for processing a valid SQL statement. It uses one of following two methods to take this decision.
Rule-based Optimizer – When a server doesn't have internal statistics supporting the objects referenced by the statement, then the RBO method gets preference. However, Oracle will deprecate this method in the future releases.
Cost-based Optimizer – When there is an abundance of the internal statistics, the CBO gets the precedence. It verifies several possible execution plans and chooses the one with the lowest cost based on the system resources.
Q:-13. What are several SQL performance tuning enhancements in Oracle?
Ans. Oracle provides many performance enhancements, some of them are:
- Automatic Performance Diagnostic and Tuning Features
- Automatic Shared Memory Management – It gives Oracle control of allocating memory within the SGA.
- Wait-model improvements – A number of views have come to boost the Wait-model.
- Automatic Optimizer Statistics Collection – Collects optimizer statistics using a scheduled job called GATHER_STATS_JOB.
- Dynamic Sampling – Enables the server to enhance performance.
- CPU Costing – It's the basic cost model for the optimizer (CPU+I/O), with the cost unit as time optimizer notifies.
- Rule Based Optimizer Obsolescence – No more used.
- Tracing Enhancements – End to End tracing which allows a client process to be identified via the Client Identifier instead of using the typical Session ID.
Q:-14. What are the tuning indicators Oracle proposes?
Ans. The following high-level tuning indicators are available to establish if a database is experiencing bottlenecks or not:
1. Buffer Cache Hit Ratio.
It uses the following formula.
Hit Ratio = (Logical Reads – Physical Reads) / Logical Reads
Action: Advance the DB_CACHE_SIZE (DB_BLOCK_BUFFERS prior to 9i) to improve the hit ratio.
2. Library Cache Hit Ratio.
Action: Advance the SHARED_POOL_SIZE to increase the hit ratio.
Q:-15. What do you check first if there are multiple fragments in the SYSTEM tablespace?
Ans. First of all, check if the users don't have the SYSTEM tablespace as their TEMPORARY or DEFAULT tablespace assignment by verifying the DBA_USERS view.
Q:-16. When would you add more Copy Latches? What are the parameters that control the Copy Latches?
Ans. If there is excessive contention for the Copy Latches, check from the "redo copy" latch hit ratio.
In such a case, add more Copy Latches via the initialization parameter LOG_SIMULTANEOUS_COPIES to double the number of CPUs available.
Q:-17. How do you confirm if a tablespace has disproportionate fragmentation?
Ans. You can confirm it by checking the output of SELECT against the dba_free_space table. If it points that the no. of a tablespaces extents is more than the count of its data files, then it proves excessive fragmentation.
Q:-18. What can you do to optimize the %XYZ% queries?
Ans. First of all, set the optimizer to scan all the entries from the index instead of the table. You can achieve it by specifying hints.
Please note that crawling the smaller index takes less time than to scan the entire table.
Q:-19. Where does the I/O statistics per table exist in Oracle?
Ans. There is a report known as UTLESTAT which displays the I/O per tablespace. But it doesn't help to find the table which has the most I/O.
Q:-20. When is the right time to rebuild an index?
Ans. First of all, select the target index and run the 'ANALYZE INDEX VALIDATE STRUCTURE' command. Every time you run it, a single row will get created in the INDEX_STATS view.
But the row gets overwritten the next time you run the ANALYZE INDEX command. So better move the contents of the view to a local table. Thereafter, analyze the ratio of 'DEL_LF_ROWS' to 'LF_ROWS' and see if you need to rebuild the index.
Q:-21. What exactly would you do to check the performance issue of SQL queries?
Ans. Mostly the database isn't slow, but it's the worker session which drags the performance. And it's the abnormal session accesses which cause the bottlenecks.
- Review the events that are in wait or listening mode.
- Hunt down the locked objects in a particular session.
- Check if the SQL query is pointing to the right index or not.
- Launch SQL Tuning Advisor and analyze the target SQL_ID for making any performance recommendation.
- Run the "free" command to check the RAM usage. Also, use TOP command to identify any process hogging the CPU.
Q:-22. What is the information you get from the STATSPACK Report?
Ans. We can get the following statistics from the STATSPACK report.
- WAIT notifiers
- Load profile
- Instance Efficiency Hit Ratio
- Latch Waits
- Top SQL
- Instance Action
- File I/O and Segment Stats
- Memory allocation
- Buffer Waits
Q:-23. What are the factors to consider for creating Index on Table? Also, How to select a column for Index?
Ans. Creation of index depends on the following factors.
- Size of table,
- Volume of data
If Table size is large and we need a smaller report, then it's better to create Index.
Regarding the column to be used for Index, as per the business rule, you should use a primary key or a unique key for creating a unique index.
Q:-24. What is the main difference between Redo, Rollback, and Undo?
Ans.
Redo – Log that records all changes made to data, including both uncommitted and committed changes.
Rollback – Segments to store the previous state of data before the changes.
Undo – Helpful in building a read consistent view of data. The data gets stored in the undo tablespace.
Q:-25. How do you identify the shared memory and semaphores of a particular DB instance if there are running multiple servers?
Ans. Set the following parameters to distinguish between the in-memory resources of a DB instance.
- SETMYPID
- IPC
- TRACEFILE_NAME
Use the ORADEBUG command to explore their underlying options.
SQL is Structured Query Language, which is a computer language for storing, manipulating and retrieving data stored in a relational database.
SQL is the standard language for Relational Database System.
| Sr.No. | Command & Description |
|---|---|
| 1 | CREATE Creates a new table, a view of a table, or other object in the database. |
| 2 | ALTER Modifies an existing database object, such as a table. |
| 3 | DROP Deletes an entire table, a view of a table or other objects in the database. |
| Sr.No. | Command & Description |
|---|---|
| 1 | SELECT Retrieves certain records from one or more tables. |
| 2 | INSERT Creates a record. |
| 3 | UPDATE Modifies records. |
| 4 | DELETE Deletes records. |
| Sr.No. | Command & Description |
|---|---|
| 1 | GRANT Gives a privilege to user. |
| 2 | REVOKE Takes back privileges granted from user. |
- Constraints:
Following are some of the most commonly used constraints available in SQL −
-
NOT NULL Constraint − Ensures that a column cannot have a NULL value.
-
DEFAULT Constraint − Provides a default value for a column when none is specified.
-
UNIQUE Constraint − Ensures that all the values in a column are different.
-
PRIMARY Key − Uniquely identifies each row/record in a database table.
-
FOREIGN Key − Uniquely identifies a row/record in any another database table.
-
CHECK Constraint − The CHECK constraint ensures that all values in a column satisfy certain conditions.
-
INDEX − Used to create and retrieve data from the database very quickly.
- SYNTAX:
SELECT column1, column2....columnN
FROM table_name;
SELECT DISTINCT column1, column2....columnN
FROM table_name;
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION;
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION-1 {AND|OR} CONDITION-2;
SELECT column1, column2....columnN
FROM table_name
WHERE column_name IN (val-1, val-2,...val-N);
SELECT column1, column2....columnN
FROM table_name
WHERE column_name BETWEEN val-1 AND val-2;
SELECT column1, column2....columnN
FROM table_name
WHERE column_name LIKE { PATTERN };
SELECT column1, column2....columnN
FROM table_name
WHERE CONDITION
ORDER BY column_name {ASC|DESC};
SELECT SUM(column_name)
FROM table_name
WHERE CONDITION
GROUP BY column_name;
SELECT COUNT(column_name)
FROM table_name
WHERE CONDITION;
SELECT SUM(column_name)
FROM table_name
WHERE CONDITION
GROUP BY column_name
HAVING (arithematic function condition);
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( one or more columns )
);
DROP TABLE table_name;
CREATE UNIQUE INDEX index_name
ON table_name ( column1, column2,...columnN);
ALTER TABLE table_name
DROP INDEX index_name;
DESC table_name;
TRUNCATE TABLE table_name;
ALTER TABLE table_name {ADD|DROP|MODIFY} column_name {data_ype};
ALTER TABLE table_name RENAME TO new_table_name;
INSERT INTO table_name( column1, column2....columnN)
VALUES ( value1, value2....valueN);
UPDATE table_name
SET column1 = value1, column2 = value2....columnN=valueN
[WHERE CONDITION];
DELETE FROM table_name
WHERE {CONDITION};
CREATE DATABASE database_name;
DROP DATABASE database_name;
USE database_name;
COMMIT;
ROLLBACK;
Here is a list of all the logical operators available in SQL.
| Sr.No. | Operator & Description |
|---|---|
| 1 | ALL The ALL operator is used to compare a value to all values in another value set. |
| 2 | AND The AND operator allows the existence of multiple conditions in an SQL statement's WHERE clause. |
| 3 | ANY The ANY operator is used to compare a value to any applicable value in the list as per the condition. |
| 4 | BETWEEN The BETWEEN operator is used to search for values that are within a set of values, given the minimum value and the maximum value. |
| 5 | EXISTS The EXISTS operator is used to search for the presence of a row in a specified table that meets a certain criterion. |
| 6 | IN The IN operator is used to compare a value to a list of literal values that have been specified. |
| 7 | LIKE The LIKE operator is used to compare a value to similar values using wildcard operators. |
| 8 | NOT The NOT operator reverses the meaning of the logical operator with which it is used. Eg: NOT EXISTS, NOT BETWEEN, NOT IN, etc. This is a negate operator. |
| 9 | OR The OR operator is used to combine multiple conditions in an SQL statement's WHERE clause. |
| 10 | IS NULL The NULL operator is used to compare a value with a NULL value. |
| 11 | UNIQUE The UNIQUE operator searches every row of a specified table for uniqueness (no duplicates). |
- Create Table syntax:
The basic syntax of the CREATE TABLE statement is as follows −
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY( one or more columns )
);
The SQL INSERT INTO syntax will be as follows −
INSERT INTO TABLE_NAME VALUES (value1,value2,value3,...valueN);
The basic syntax of the UPDATE query with a WHERE clause is as follows −
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
DELETE FROM table_name
WHERE [condition];
The basic syntax of % and _ is as follows −
SELECT FROM table_name
WHERE column LIKE 'XXXX%'
or
SELECT FROM table_name
WHERE column LIKE '%XXXX%'
or
SELECT FROM table_name
WHERE column LIKE 'XXXX_'
or
SELECT FROM table_name
WHERE column LIKE '_XXXX'
or
SELECT FROM table_name
WHERE column LIKE '_XXXX_'
The basic syntax of the TOP clause with a SELECT statement would be as follows.
SELECT TOP number|percent column_name(s)
FROM table_name
WHERE [condition]
GROUP BY clause must follow the conditions in the WHERE clause and must precede the ORDER BY clause if one is used.
SELECT column1, column2
FROM table_name
WHERE [conditions]
GROUP BY column1, column2
ORDER BY column1, column2
The basic syntax of DISTINCT keyword to eliminate the duplicate records is as follows −
SELECT DISTINCT column1, column2,.....columnN
FROM table_name
WHERE [condition]
JOINS:
There are different types of joins available in SQL −
- INNER JOIN − returns rows when there is a match in both tables.
- LEFT JOIN − returns all rows from the left table, even if there are no matches in the right table.
- RIGHT JOIN − returns all rows from the right table, even if there are no matches in the left table.
- FULL JOIN − returns rows when there is a match in one of the tables.
- SELF JOIN − is used to join a table to itself as if the table were two tables, temporarily renaming at least one table in the SQL statement.
- CARTESIAN JOIN − returns the Cartesian product of the sets of records from the two or more joined tables.
INDEX:
A single-column index is created based on only one table column. The basic syntax is as follows.
CREATE INDEX index_name
ON table_name (column_name);
Unique indexes are used not only for performance, but also for data integrity. A unique index does not allow any duplicate values to be inserted into the table. The basic syntax is as follows.
CREATE UNIQUE INDEX index_name
on table_name (column_name);
A composite index is an index on two or more columns of a table. Its basic syntax is as follows.
CREATE INDEX index_name
on table_name (column1, column2);
Implicit indexes are indexes that are automatically created by the database server when an object is created. Indexes are automatically created for primary key constraints and unique constraints.
We have the following rank functions.
- ROW_NUMBER() -ROW_Number() SQL RANK function to get a unique sequential number for each row

- RANK()

- DENSE_RANK() - if we have duplicate values, SQL assigns different ranks to those rows as well. Ideally, we should get the same rank for duplicate or similar values.

- NTILE()
SELECT
product_id,
product_name,
list_price,
RANK () OVER (
ORDER BY list_price DESC
) price_rank
FROM
production.products;
Here is the result set:





















































































- Concurrency













-
Microsoft Interview Questions:
-
Time complexity is a concept in computer science that deals with the quantification of the amount of time taken by a set of code or algorithm to process or run as a function of the amount of input. In other words, time complexity is essentially efficiency, or how long a program function takes to process a given input.
-
Auxiliary Space is the extra space or temporary space used by an algorithm. Space Complexity of an algorithm is total space taken by the algorithm with respect to the input size. Space complexity includes both Auxiliary space and space used by input. ... Space complexity of all these sorting algorithms is O(n) though.
-
A program to check if a binary tree is BST or not
METHOD 3 (Correct and Efficient): Method 2 above runs slowly since it traverses over some parts of the tree many times. A better solution looks at each node only once. The trick is to write a utility helper function isBSTUtil(struct node* node, int min, int max) that traverses down the tree keeping track of the narrowing min and max allowed values as it goes, looking at each node only once. The initial values for min and max should be INT_MIN and INT_MAX — they narrow from there.
Below is the implementation of the above approach:
using System;
// C# implementation to check if given Binary tree
//is a BST or not
/* Class containing left and right child of current
node and key value*/
public class Node
{
public int data;
public Node left, right;
public Node(int item)
{
data = item;
left = right = null;
}
}
public class BinaryTree
{
//Root of the Binary Tree
public Node root;
/* can give min and max value according to your code or
can write a function to find min and max value of tree. */
/* returns true if given search tree is binary
search tree (efficient version) */
public virtual bool BST
{
get
{
return isBSTUtil(root, int.MinValue, int.MaxValue);
}
}
/* Returns true if the given tree is a BST and its
values are >= min and <= max. */
public virtual bool isBSTUtil(Node node, int min, int max)
{
/* an empty tree is BST */
if (node == null)
{
return true;
}
/* false if this node violates the min/max constraints */
if (node.data < min || node.data > max)
{
return false;
}
/* otherwise check the subtrees recursively
tightening the min/max constraints */
// Allow only distinct values
return (isBSTUtil(node.left, min, node.data - 1) && isBSTUtil(node.right, node.data + 1, max));
}
/* Driver program to test above functions */
public static void Main(string[] args)
{
BinaryTree tree = new BinaryTree();
tree.root = new Node(4);
tree.root.left = new Node(2);
tree.root.right = new Node(5);
tree.root.left.left = new Node(1);
tree.root.left.right = new Node(3);
if (tree.BST)
{
Console.WriteLine("IS BST");
}
else
{
Console.WriteLine("Not a BST");
}
}
}
Output:
IS BST
Time Complexity: O(n) Auxiliary Space : O(1) if Function Call Stack size is not considered, otherwise O(n)
Simplified Method 3 We can simplify method 2 using NULL pointers instead of INT_MIN and INT_MAX values.
// C# program to check if a given tree is BST.
using System;
class GFG
{
// A binary tree node has data, pointer to
//left child && a pointer to right child /
public class Node
{
public int data;
public Node left, right;
};
// Returns true if given tree is BST.
static Boolean isBST(Node root, Node l, Node r)
{
// Base condition
if (root == null)
return true;
// if left node exist then check it has
// correct data or not i.e. left node's data
// should be less than root's data
if (l != null && root.data <= l.data)
return false;
// if right node exist then check it has
// correct data or not i.e. right node's data
// should be greater than root's data
if (r != null && root.data >= r.data)
return false;
// check recursively for every node.
return isBST(root.left, l, root) &&
isBST(root.right, root, r);
}
// Helper function that allocates a new node with the
//given data && null left && right pointers. /
static Node newNode(int data)
{
Node node = new Node();
node.data = data;
node.left = node.right = null;
return (node);
}
// Driver code
public static void Main(String []args)
{
Node root = newNode(3);
root.left = newNode(2);
root.right = newNode(5);
root.left.left = newNode(1);
root.left.right = newNode(4);
if (isBST(root,null,null))
Console.Write("Is BST");
else
Console.Write("Not a BST");
}
}
- Remove duplicates from a given string
// C# program to remove duplicate character
// from character array and print in sorted
// order
using System;
using System.Collections.Generic;
class GFG
{
static String removeDuplicate(char []str, int n)
{
// Used as index in the modified string
int index = 0;
// Traverse through all characters
for (int i = 0; i < n; i++)
{
// Check if str[i] is present before it
int j;
for (j = 0; j < i; j++)
{
if (str[i] == str[j])
{
break;
}
}
// If not present, then add it to
// result.
if (j == i)
{
str[index++] = str[i];
}
}
char [] ans = new char[index];
Array.Copy(str, ans, index);
return String.Join("", ans);
}
// Driver code
public static void Main(String[] args)
{
char []str = "geeksforgeeks".ToCharArray();
int n = str.Length;
Console.WriteLine(removeDuplicate(str, n));
}
}
- Remove duplicates from a given string
METHOD 1 (Simple)
// C# program to remove duplicate character
// from character array and print in sorted
// order
using System;
using System.Collections.Generic;
class GFG
{
static String removeDuplicate(char []str, int n)
{
// Used as index in the modified string
int index = 0;
// Traverse through all characters
for (int i = 0; i < n; i++)
{
// Check if str[i] is present before it
int j;
for (j = 0; j < i; j++)
{
if (str[i] == str[j])
{
break;
}
}
// If not present, then add it to
// result.
if (j == i)
{
str[index++] = str[i];
}
}
char [] ans = new char[index];
Array.Copy(str, ans, index);
return String.Join("", ans);
}
// Driver code
public static void Main(String[] args)
{
char []str = "geeksforgeeks".ToCharArray();
int n = str.Length;
Console.WriteLine(removeDuplicate(str, n));
}
}
Output:
geksfor
Time Complexity : O(n * n) Auxiliary Space : O(1)
METHOD 3 (Use Sorting) Algorithm:
-
Sort the elements.
-
Now in a loop, remove duplicates by comparing the
current character with previous character.
- Remove extra characters at the end of the resultant string.
Example:
Input string: geeksforgeeks
- Sort the characters
eeeefggkkorss
- Remove duplicates
efgkorskkorss
- Remove extra characters
efgkors
Note that, this method doesn't keep the original order of the input string. For example, if we are to remove duplicates for geeksforgeeks and keep the order of characters same, then output should be geksfor, but above function returns efgkos. We can modify this method by storing the original order. METHOD 2 keeps the order same.
Implementation:
// C# program to remove duplicates, the order of
// characters is not maintained in this program
using System;
class GFG
{
/* Method to remove duplicates in a sorted array */
static String removeDupsSorted(String str)
{
int res_ind = 1, ip_ind = 1;
// Character array for removal of duplicate characters
char []arr = str.ToCharArray();
/* In place removal of duplicate characters*/
while (ip_ind != arr.Length)
{
if(arr[ip_ind] != arr[ip_ind-1])
{
arr[res_ind] = arr[ip_ind];
res_ind++;
}
ip_ind++;
}
str = new String(arr);
return str.Substring(0,res_ind);
}
/* Method removes duplicate characters from the string
This function work in-place and fills null characters
in the extra space left */
static String removeDups(String str)
{
// Sort the character array
char []temp = str.ToCharArray();
Array.Sort(temp);
str = String.Join("",temp);
// Remove duplicates from sorted
return removeDupsSorted(str);
}
// Driver Method
public static void Main(String[] args)
{
String str = "geeksforgeeks";
Console.WriteLine(removeDups(str));
}
}
Output:
efgkors
Time Complexity: O(n log n) If we use some nlogn sorting algorithm instead of quicksort.
METHOD 4 (Use Hashing ) Algorithm:
1: Initialize:
str = "test string" /* input string */
ip_ind = 0 /* index to keep track of location of next
character in input string */
res_ind = 0 /* index to keep track of location of
next character in the resultant string */
bin_hash[0..255] = {0,0, ….} /* Binary hash to see if character is
already processed or not */
2: Do following for each character *(str + ip_ind) in input string:
(a) if bin_hash is not set for *(str + ip_ind) then
// if program sees the character *(str + ip_ind) first time
(i) Set bin_hash for *(str + ip_ind)
(ii) Move *(str + ip_ind) to the resultant string.
This is done in-place.
(iii) res_ind++
(b) ip_ind++
/* String obtained after this step is "te sringng" */
3: Remove extra characters at the end of the resultant string.
/* String obtained after this step is "te sring" */
Implementation:
- C++
- C
- Java
- Python
- C#
// C# program to remove duplicates
using System;
using System.Collections.Generic;
class GFG
{
/* Function removes duplicate characters
from the string. This function work in-place */
void removeDuplicates(String str)
{
HashSet<char> lhs = new HashSet<char>();
for(int i = 0; i < str.Length; i++)
lhs.Add(str[i]);
// print string after deleting
// duplicate elements
foreach(char ch in lhs)
Console.Write(ch);
}
// Driver Code
public static void Main(String []args)
{
String str = "geeksforgeeks";
GFG r = new GFG();
r.removeDuplicates(str);
}
}
Output:
geksfor
**Time Complexity: ** O(n)
Important Points:
- Method 1 doesn't maintain order of characters as original string, but method 2 does.
- It is assumed that number of possible characters in input string are 256. NO_OF_CHARS should be changed accordingly.
- calloc is used instead of malloc for memory allocations of counting array (count) to initialize allocated memory to '\0'. malloc() followed by memset() could also be used.
- Above algorithm also works for an integer array inputs if range of the integers in array is given. Example problem is to find maximum occurring number in an input array given that the input array contain integers only between 1000 to 1100
Method 5 (Using IndexOf() method) : Prerequisite : Java IndexOf() method
// C# program too create a unique string
using System;
public class IndexOf
{
// Function to make the string unique
public static String unique(String s)
{
String str = "";
int len = s.Length;
// loop to traverse the string and
// check for repeating chars using
// IndexOf() method in Java
for (int i = 0; i < len; i++)
{
// character at i'th index of s
char c = s[i];
// if c is present in str, it returns
// the index of c, else it returns -1
if (str.IndexOf(c) < 0)
{
// adding c to str if -1 is returned
str += c;
}
}
return str;
}
// Driver code
public static void Main(String[] args)
{
// Input string with repeating chars
String s = "geeksforgeeks";
Console.WriteLine(unique(s));
}
}
- Search an element in a sorted and rotated array:
An element in a sorted array can be found in O(log n) time via binary search. But suppose we rotate an ascending order sorted array at some pivot unknown to you beforehand. So for instance, 1 2 3 4 5 might become 3 4 5 1 2. Devise a way to find an element in the rotated array in O(log n) time.

Input : arr[] = {5, 6, 7, 8, 9, 10, 1, 2, 3};
key = 3
Output : Found at index 8
Input : arr[] = {5, 6, 7, 8, 9, 10, 1, 2, 3};
key = 30
Output : Not found
Input : arr[] = {30, 40, 50, 10, 20}
key = 10
Output : Found at index 3
The idea is to find the pivot point, divide the array in two sub-arrays and call binary search. The main idea for finding pivot is – for a sorted (in increasing order) and pivoted array, pivot element is the only element for which next element to it is smaller than it. Using above criteria and binary search methodology we can get pivot element in O(logn) time
Input arr[] = {3, 4, 5, 1, 2}
Element to Search = 1
- Find out pivot point and divide the array in two
sub-arrays. (pivot = 2) /*Index of 5*/
- Now call binary search for one of the two sub-arrays.
(a) If element is greater than 0th element then
search in left array
(b) Else Search in right array
(1 will go in else as 1 < 0th element(3))
- If element is found in selected sub-array then return index
Else return -1.
Below is the implementation of the above approach :
// C# program to search an element
// in a sorted and pivoted array
using System;
class main {
// Searches an element key in a
// pivoted sorted array arrp[]
// of size n
static int pivotedBinarySearch(int[] arr,
int n, int key)
{
int pivot = findPivot(arr, 0, n - 1);
// If we didn't find a pivot, then
// array is not rotated at all
if (pivot == -1)
return binarySearch(arr, 0, n - 1, key);
// If we found a pivot, then first
// compare with pivot and then
// search in two subarrays around pivot
if (arr[pivot] == key)
return pivot;
if (arr[0] <= key)
return binarySearch(arr, 0, pivot - 1, key);
return binarySearch(arr, pivot + 1, n - 1, key);
}
/* Function to get pivot. For array
3, 4, 5, 6, 1, 2 it returns
3 (index of 6) */
static int findPivot(int[] arr, int low, int high)
{
// base cases
if (high < low)
return -1;
if (high == low)
return low;
/* low + (high - low)/2; */
int mid = (low + high) / 2;
if (mid < high && arr[mid] > arr[mid + 1])
return mid;
if (mid > low && arr[mid] < arr[mid - 1])
return (mid - 1);
if (arr[low] >= arr[mid])
return findPivot(arr, low, mid - 1);
return findPivot(arr, mid + 1, high);
}
/* Standard Binary Search function */
static int binarySearch(int[] arr, int low,
int high, int key)
{
if (high < low)
return -1;
/* low + (high - low)/2; */
int mid = (low + high) / 2;
if (key == arr[mid])
return mid;
if (key > arr[mid])
return binarySearch(arr, (mid + 1), high, key);
return binarySearch(arr, low, (mid - 1), key);
}
// Driver Code
public static void Main()
{
// Let us search 3 in below array
int[] arr1 = { 5, 6, 7, 8, 9, 10, 1, 2, 3 };
int n = arr1.Length;
int key = 3;
Console.Write("Index of the element is : "
+ pivotedBinarySearch(arr1, n, key));
}
}
Improved Solution: We can search an element in one pass of Binary Search. The idea is to search
-
Find middle point mid = (l + h)/2
-
If key is present at middle point, return mid.
-
Else If arr[l..mid] is sorted
a) If key to be searched lies in range from arr[l]
to arr[mid], recur for arr[l..mid].
b) Else recur for arr[mid+1..h]
- Else (arr[mid+1..h] must be sorted)
a) If key to be searched lies in range from arr[mid+1]
to arr[h], recur for arr[mid+1..h].
b) Else recur for arr[l..mid]
Below is the implementation of above idea :
/* C# program to search an element in
sorted and rotated array using
single pass of Binary Search*/
using System;
class GFG {
// Returns index of key in arr[l..h]
// if key is present, otherwise
// returns -1
static int search(int []arr, int l, int h,
int key)
{
if (l > h)
return -1;
int mid = (l + h) / 2;
if (arr[mid] == key)
return mid;
/* If arr[l...mid] is sorted */
if (arr[l] <= arr[mid])
{
/* As this subarray is sorted, we
can quickly check if key lies in
half or other half */
if (key >= arr[l] && key <= arr[mid])
return search(arr, l, mid - 1, key);
return search(arr, mid + 1, h, key);
}
/* If arr[l..mid] is not sorted,
then arr[mid... r] must be sorted*/
if (key >= arr[mid] && key <= arr[h])
return search(arr, mid + 1, h, key);
return search(arr, l, mid - 1, key);
}
// main function
public static void Main()
{
int []arr = {4, 5, 6, 7, 8, 9, 1, 2, 3};
int n = arr.Length;
int key = 6;
int i = search(arr, 0, n - 1, key);
if (i != -1)
Console.WriteLine("Index: " + i);
else
Console.WriteLine("Key not found");
}
}
17.5. Add two numbers represented by linked lists | Set 2:
Given two numbers represented by two linked lists, write a function that returns the sum list. The sum list is linked list representation of the addition of two input numbers. It is not allowed to modify the lists. Also, not allowed to use explicit extra space (Hint: Use Recursion).
Example
Input:
First List: 5->6->3 // represents number 563
Second List: 8->4->2 // represents number 842
Output
Resultant list: 1->4->0->5 // represents number 1405
Recommended: Please solve it on "PRACTICE " first, before moving on to the solution.
We have discussed a solution here which is for linked lists where a least significant digit is the first node of lists and the most significant digit is the last node. In this problem, the most significant node is the first node and the least significant digit is the last node and we are not allowed to modify the lists. Recursion is used here to calculate sum from right to left.
Following are the steps. 1) Calculate sizes of given two linked lists. 2) If sizes are same, then calculate sum using recursion. Hold all nodes in recursion call stack till the rightmost node, calculate the sum of rightmost nodes and forward carry to the left side. 3) If size is not same, then follow below steps: ….a) Calculate difference of sizes of two linked lists. Let the difference be diff ….b) Move _diff _nodes ahead in the bigger linked list. Now use step 2 to calculate the sum of the smaller list and right sub-list (of the same size) of a larger list. Also, store the carry of this sum. ….c) Calculate the sum of the carry (calculated in the previous step) with the remaining left sub-list of a larger list. Nodes of this sum are added at the beginning of the sum list obtained the previous step.
Below is a dry run of the above approach:

Below image is the implementation of the above approach.
// Java program to add two linked lists
public class linkedlistATN
{
class node
{
int val;
node next;
public node(int val)
{
this.val = val;
}
}
// Function to print linked list
void printlist(node head)
{
while (head != null)
{
System.out.print(head.val + " ");
head = head.next;
}
}
node head1, head2, result;
int carry;
/* A utility function to push a value to linked list */
void push(int val, int list)
{
node newnode = new node(val);
if (list == 1)
{
newnode.next = head1;
head1 = newnode;
}
else if (list == 2)
{
newnode.next = head2;
head2 = newnode;
}
else
{
newnode.next = result;
result = newnode;
}
}
// Adds two linked lists of same size represented by
// head1 and head2 and returns head of the resultant
// linked list. Carry is propagated while returning
// from the recursion
void addsamesize(node n, node m)
{
// Since the function assumes linked lists are of
// same size, check any of the two head pointers
if (n == null)
return;
// Recursively add remaining nodes and get the carry
addsamesize(n.next, m.next);
// add digits of current nodes and propagated carry
int sum = n.val + m.val + carry;
carry = sum / 10;
sum = sum % 10;
// Push this to result list
push(sum, 3);
}
node cur;
// This function is called after the smaller list is
// added to the bigger lists's sublist of same size.
// Once the right sublist is added, the carry must be
// added to the left side of larger list to get the
// final result.
void propogatecarry(node head1)
{
// If diff. number of nodes are not traversed, add carry
if (head1 != cur)
{
propogatecarry(head1.next);
int sum = carry + head1.val;
carry = sum / 10;
sum %= 10;
// add this node to the front of the result
push(sum, 3);
}
}
int getsize(node head)
{
int count = 0;
while (head != null)
{
count++;
head = head.next;
}
return count;
}
// The main function that adds two linked lists
// represented by head1 and head2. The sum of two
// lists is stored in a list referred by result
void addlists()
{
// first list is empty
if (head1 == null)
{
result = head2;
return;
}
// first list is empty
if (head2 == null)
{
result = head1;
return;
}
int size1 = getsize(head1);
int size2 = getsize(head2);
// Add same size lists
if (size1 == size2)
{
addsamesize(head1, head2);
}
else
{
// First list should always be larger than second list.
// If not, swap pointers
if (size1 < size2)
{
node temp = head1;
head1 = head2;
head2 = temp;
}
int diff = Math.abs(size1 - size2);
// move diff. number of nodes in first list
node temp = head1;
while (diff-- >= 0)
{
cur = temp;
temp = temp.next;
}
// get addition of same size lists
addsamesize(cur, head2);
// get addition of remaining first list and carry
propogatecarry(head1);
}
// if some carry is still there, add a new node to
// the front of the result list. e.g. 999 and 87
if (carry > 0)
push(carry, 3);
}
// Driver program to test above functions
public static void main(String args[])
{
linkedlistATN list = new linkedlistATN();
list.head1 = null;
list.head2 = null;
list.result = null;
list.carry = 0;
int arr1[] = { 9, 9, 9 };
int arr2[] = { 1, 8 };
// Create first list as 9->9->9
for (int i = arr1.length - 1; i >= 0; --i)
list.push(arr1[i], 1);
// Create second list as 1->8
for (int i = arr2.length - 1; i >= 0; --i)
list.push(arr2[i], 2);
list.addlists();
list.printlist(list.result);
}
}
Given some text lines in one string, each line is separated by '\n' character. Print the last ten lines. If number of lines is less than 10, then print all lines.
Source: Microsoft Interview | Set 10
Following are the steps 1) Find the last occurrence of DELIM or '\n' 2) Initialize target position as last occurrence of '\n' and count as 0 , and do following while count < 10 ……2.a) Find the next instance of '\n' and update target position …..2.b) Skip '\n' and increment count of '\n' and update target position **3) **Print the sub-string from target position.
The idea is to use Hashing. Below is algorithm.
- Traverse the original linked list and make a copy in terms of data.
- Make a hash map of key value pair with original linked list node and copied linked list node.
- Traverse the original linked list again and using the hash map adjust the next and random reference of cloned linked list nodes.
You are given a Double Link List with one pointer of each node pointing to the next node just like in a single link list. The second pointer however CAN point to any node in the list and not just the previous node. Now write a program in** O(n) time **to duplicate this list. That is, write a program which will create a copy of this list.
Let us call the second pointer as arbit pointer as it can point to any arbitrary node in the linked list.

Below is the implementation of above approach.
// Java program to clone a linked list with random pointers
import java.util.HashMap;
import java.util.Map;
// Linked List Node class
class Node
{
int data;//Node data
Node next, random;//Next and random reference
//Node constructor
public Node(int data)
{
this.data = data;
this.next = this.random = null;
}
}
// linked list class
class LinkedList
{
Node head;//Linked list head reference
// Linked list constructor
public LinkedList(Node head)
{
this.head = head;
}
// push method to put data always at the head
// in the linked list.
public void push(int data)
{
Node node = new Node(data);
node.next = this.head;
this.head = node;
}
// Method to print the list.
void print()
{
Node temp = head;
while (temp != null)
{
Node random = temp.random;
int randomData = (random != null)? random.data: -1;
System.out.println("Data = " + temp.data +
", Random data = "+ randomData);
temp = temp.next;
}
}
// Actual clone method which returns head
// reference of cloned linked list.
public LinkedList clone()
{
// Initialize two references, one with original
// list's head.
Node origCurr = this.head, cloneCurr = null;
// Hash map which contains node to node mapping of
// original and clone linked list.
Map<Node, Node> map = new HashMap<Node, Node>();
// Traverse the original list and make a copy of that
// in the clone linked list.
while (origCurr != null)
{
cloneCurr = new Node(origCurr.data);
map.put(origCurr, cloneCurr);
origCurr = origCurr.next;
}
// Adjusting the original list reference again.
origCurr = this.head;
// Traversal of original list again to adjust the next
// and random references of clone list using hash map.
while (origCurr != null)
{
cloneCurr = map.get(origCurr);
cloneCurr.next = map.get(origCurr.next);
cloneCurr.random = map.get(origCurr.random);
origCurr = origCurr.next;
}
//return the head reference of the clone list.
return new LinkedList(map.get(this.head));
}
}
// Driver Class
class Main
{
// Main method.
public static void main(String[] args)
{
// Pushing data in the linked list.
LinkedList list = new LinkedList(new Node(5));
list.push(4);
list.push(3);
list.push(2);
list.push(1);
// Setting up random references.
list.head.random = list.head.next.next;
list.head.next.random =
list.head.next.next.next;
list.head.next.next.random =
list.head.next.next.next.next;
list.head.next.next.next.random =
list.head.next.next.next.next.next;
list.head.next.next.next.next.random =
list.head.next;
// Making a clone of the original linked list.
LinkedList clone = list.clone();
// Print the original and cloned linked list.
System.out.println("Original linked list");
list.print();
System.out.println("\nCloned linked list");
clone.print();
}
}
Write a function to connect all the adjacent nodes at the same level in a binary tree. Structure of the given Binary Tree node is like following.
struct node{
intdata;
structnode* left;
structnode* right;
structnode* nextRight;
}
Initially, all the nextRight pointers point to garbage values. Your function should set these pointers to point next right for each node.
Example:
Input Tree
A
/ \
B C
/ \ \
D E F
Output Tree
A--->NULL
/ \
B-->C-->NULL
/ \ \
D-->E-->F-->NULL
Recommended: Please solve it on "PRACTICE" first, before moving on to the solution.
Method 1 (Extend Level Order Traversal or BFS) Consider the method 2 of Level Order Traversal. The method 2 can easily be extended to connect nodes of same level. We can augment queue entries to contain level of nodes also which is 0 for root, 1 for root's children and so on. So a queue node will now contain a pointer to a tree node and an integer level. When we enqueue a node, we make sure that correct level value for node is being set in queue. To set nextRight, for every node N, we dequeue the next node from queue, if the level number of next node is same, we set the nextRight of N as address of the dequeued node, otherwise we set nextRight of N as NULL.
Please refer connect Nodes at same Level (Level Order Traversal) for implementation.
Time Complexity: O(n)
// Connect nodes at same level using level order
// traversal.
using System;
using System.Collections.Generic;
public class Connect_node_same_level
{
// Node class
class Node
{
public int data;
public Node left, right, nextRight;
public Node(int data)
{
this.data = data;
left = null;
right = null;
nextRight = null;
}
};
// Sets nextRight of all nodes of a tree
static void connect(Node root)
{
Queue<Node> q = new Queue<Node>();
q.Enqueue(root);
// null marker to represent end of current level
q.Enqueue(null);
// Do Level order of tree using NULL markers
while (q.Count!=0)
{
Node p = q.Peek();
q.Dequeue();
if (p != null)
{
// next element in queue represents next
// node at current Level
p.nextRight = q.Peek();
// push left and right children of current
// node
if (p.left != null)
q.Enqueue(p.left);
if (p.right != null)
q.Enqueue(p.right);
}
// if queue is not empty, push NULL to mark
// nodes at this level are visited
else if (q.Count!=0)
q.Enqueue(null);
}
}
/* Driver code*/
public static void Main()
{
/* Constructed binary tree is
10
/ \
8 2
/ \
3 90
*/
Node root = new Node(10);
root.left = new Node(8);
root.right = new Node(2);
root.left.left = new Node(3);
root.right.right = new Node(90);
// Populates nextRight pointer in all nodes
connect(root);
// Let us check the values of nextRight pointers
Console.WriteLine("Following are populated nextRight pointers in \n" +
"the tree (-1 is printed if there is no nextRight)");
Console.WriteLine("nextRight of "+ root.data +" is "+
((root.nextRight != null) ? root.nextRight.data : -1));
Console.WriteLine("nextRight of "+ root.left.data+" is "+
((root.left.nextRight != null) ? root.left.nextRight.data : -1));
Console.WriteLine("nextRight of "+ root.right.data+" is "+
((root.right.nextRight != null) ? root.right.nextRight.data : -1));
Console.WriteLine("nextRight of "+ root.left.left.data+" is "+
((root.left.left.nextRight != null) ? root.left.left.nextRight.data : -1));
Console.WriteLine("nextRight of "+ root.right.right.data+" is "+
((root.right.right.nextRight != null) ? root.right.right.nextRight.data : -1));
}
}
Method 2 (Extend Pre Order Traversal) This approach works only for Complete Binary Trees. In this method we set nextRight in Pre Order fashion to make sure that the nextRight of parent is set before its children. When we are at node p, we set the nextRight of its left and right children. Since the tree is complete tree, nextRight of p's left child (p->left->nextRight) will always be p's right child, and nextRight of p's right child (p->right->nextRight) will always be left child of p's nextRight (if p is not the rightmost node at its level). If p is the rightmost node, then nextRight of p's right child will be NULL.
using System;
// C# program to connect nodes at same level using extended
// pre-order traversal
// A binary tree node
public class Node
{
public int data;
public Node left, right, nextRight;
public Node(int item)
{
data = item;
left = right = nextRight = null;
}
}
public class BinaryTree
{
public Node root;
// Sets the nextRight of root and calls connectRecur()
// for other nodes
public virtual void connect(Node p)
{
// Set the nextRight for root
p.nextRight = null;
// Set the next right for rest of the nodes (other
// than root)
connectRecur(p);
}
/* Set next right of all descendents of p.
Assumption: p is a compete binary tree */
public virtual void connectRecur(Node p)
{
// Base case
if (p == null)
{
return;
}
// Set the nextRight pointer for p's left child
if (p.left != null)
{
p.left.nextRight = p.right;
}
// Set the nextRight pointer for p's right child
// p->nextRight will be NULL if p is the right most child
// at its level
if (p.right != null)
{
p.right.nextRight = (p.nextRight != null) ? p.nextRight.left : null;
}
// Set nextRight for other nodes in pre order fashion
connectRecur(p.left);
connectRecur(p.right);
}
// Driver program to test above functions
public static void Main(string[] args)
{
BinaryTree tree = new BinaryTree();
/* Constructed binary tree is
10
/ \
8 2
/
3
*/
tree.root = new Node(10);
tree.root.left = new Node(8);
tree.root.right = new Node(2);
tree.root.left.left = new Node(3);
// Populates nextRight pointer in all nodes
tree.connect(tree.root);
// Let us check the values of nextRight pointers
Console.WriteLine("Following are populated nextRight pointers in " + "the tree" + "(-1 is printed if there is no nextRight)");
int a = tree.root.nextRight != null ? tree.root.nextRight.data : -1;
Console.WriteLine("nextRight of " + tree.root.data + " is " + a);
int b = tree.root.left.nextRight != null ? tree.root.left.nextRight.data : -1;
Console.WriteLine("nextRight of " + tree.root.left.data + " is " + b);
int c = tree.root.right.nextRight != null ? tree.root.right.nextRight.data : -1;
Console.WriteLine("nextRight of " + tree.root.right.data + " is " + c);
int d = tree.root.left.left.nextRight != null ? tree.root.left.left.nextRight.data : -1;
Console.WriteLine("nextRight of " + tree.root.left.left.data + " is " + d);
}
}
Given a binary tree (not a binary search tree) and two values say n1 and n2, write a program to find the least common ancestor.
_Following is definition of LCA from _ _ Wikipedia _ : Let T be a rooted tree. The lowest common ancestor between two nodes n1 and n2 is defined as the lowest node in T that has both n1 and n2 as descendants (where we allow a node to be a descendant of itself).
The LCA of n1 and n2 in T is the shared ancestor of n1 and n2 that is located farthest from the root. Computation of lowest common ancestors may be useful, for instance, as part of a procedure for determining the distance between pairs of nodes in a tree: the distance from n1 to n2 can be computed as the distance from the root to n1, plus the distance from the root to n2, minus twice the distance from the root to their lowest common ancestor. (Source Wiki)
using System;
// c# implementation to find lowest common ancestor of
// n1 and n2 using one traversal of binary tree
// It also handles cases even when n1 and n2 are not there in Tree
/* Class containing left and right child of current node and key */
public class Node
{
public int data;
public Node left, right;
public Node(int item)
{
data = item;
left = right = null;
}
}
public class BinaryTree
{
// Root of the Binary Tree
public Node root;
public static bool v1 = false, v2 = false;
// This function returns pointer to LCA of two given
// values n1 and n2.
// v1 is set as true by this function if n1 is found
// v2 is set as true by this function if n2 is found
public virtual Node findLCAUtil(Node node, int n1, int n2)
{
// Base case
if (node == null)
{
return null;
}
//Store result in temp, in case of key match so that we can search for other key also.
Node temp = null;
// If either n1 or n2 matches with root's key, report the presence
// by setting v1 or v2 as true and return root (Note that if a key
// is ancestor of other, then the ancestor key becomes LCA)
if (node.data == n1)
{
v1 = true;
temp = node;
}
if (node.data == n2)
{
v2 = true;
temp = node;
}
// Look for keys in left and right subtrees
Node left_lca = findLCAUtil(node.left, n1, n2);
Node right_lca = findLCAUtil(node.right, n1, n2);
if (temp != null)
{
return temp;
}
// If both of the above calls return Non-NULL, then one key
// is present in once subtree and other is present in other,
// So this node is the LCA
if (left_lca != null && right_lca != null)
{
return node;
}
// Otherwise check if left subtree or right subtree is LCA
return (left_lca != null) ? left_lca : right_lca;
}
// Finds lca of n1 and n2 under the subtree rooted with 'node'
public virtual Node findLCA(int n1, int n2)
{
// Initialize n1 and n2 as not visited
v1 = false;
v2 = false;
// Find lca of n1 and n2 using the technique discussed above
Node lca = findLCAUtil(root, n1, n2);
// Return LCA only if both n1 and n2 are present in tree
if (v1 && v2)
{
return lca;
}
// Else return NULL
return null;
}
/* Driver program to test above functions */
public static void Main(string[] args)
{
BinaryTree tree = new BinaryTree();
tree.root = new Node(1);
tree.root.left = new Node(2);
tree.root.right = new Node(3);
tree.root.left.left = new Node(4);
tree.root.left.right = new Node(5);
tree.root.right.left = new Node(6);
tree.root.right.right = new Node(7);
Node lca = tree.findLCA(4, 5);
if (lca != null)
{
Console.WriteLine("LCA(4, 5) = " + lca.data);
}
else
{
Console.WriteLine("Keys are not present");
}
lca = tree.findLCA(4, 10);
if (lca != null)
{
Console.WriteLine("LCA(4, 10) = " + lca.data);
}
else
{
Console.WriteLine("Keys are not present");
}
}
}
Given an input string, write a function that returns the Run Length Encoded string for the input string.
For example, if the input string is "wwwwaaadexxxxxx", then the function should return "w4a3d1e1x6".
- Pick the first character from source string. b) Append the picked character to the destination string. c) Count the number of subsequent occurrences of the picked character and append the count to destination string. d) Pick the next character and repeat steps b) c) and d) if end of string is NOT reached.
// Java program to implement run length encoding
public class RunLength_Encoding {
public static void printRLE(String str)
{
int n = str.length();
for (int i = 0; i < n; i++) {
// Count occurrences of current character
int count = 1;
while (i < n - 1 &&
str.charAt(i) == str.charAt(i + 1)) {
count++;
i++;
}
// Print character and its count
System.out.print(str.charAt(i));
System.out.print(count);
}
}
public static void main(String[] args)
{
String str = "wwwwaaadexxxxxxywww";
printRLE(str);
}
}
Write a function detectAndRemoveLoop() that checks whether a given Linked List contains loop and if loop is present then removes the loop and returns true. If the list doesn't contain loop then it returns false. Below diagram shows a linked list with a loop. detectAndRemoveLoop() must change the below list to 1->2->3->4->5->NULL.
Idea is simple: the very first node whose next is already visited (or hashed) is the last node.
**Method 1 (Check one by one) **We know that Floyd's Cycle detection algorithm terminates when fast and slow pointers meet at a common point. We also know that this common point is one of the loop nodes (2 or 3 or 4 or 5 in the above diagram). Store the address of this in a pointer variable say ptr2. After that start from the head of the Linked List and check for nodes one by one if they are reachable from ptr2. Whenever we find a node that is reachable, we know that this node is the starting node of the loop in Linked List and we can get the pointer to the previous of this node.
// C# program to detect and remove loop in linked list
using System;
public class LinkedList {
public Node head;
public class Node {
public int data;
public Node next;
public Node(int d)
{
data = d;
next = null;
}
}
// Function that detects loop in the list
int detectAndRemoveLoop(Node node)
{
Node slow = node, fast = node;
while (slow != null && fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
// If slow and fast meet at same point then loop is present
if (slow == fast) {
removeLoop(slow, node);
return 1;
}
}
return 0;
}
// Function to remove loop
void removeLoop(Node loop, Node curr)
{
Node ptr1 = null, ptr2 = null;
/* Set a pointer to the beging of the Linked List and
move it one by one to find the first node which is
part of the Linked List */
ptr1 = curr;
while (1 == 1) {
/* Now start a pointer from loop_node and check if it ever
reaches ptr2 */
ptr2 = loop;
while (ptr2.next != loop && ptr2.next != ptr1) {
ptr2 = ptr2.next;
}
/* If ptr2 reahced ptr1 then there is a loop. So break the
loop */
if (ptr2.next == ptr1) {
break;
}
/* If ptr2 did't reach ptr1 then try the next node after ptr1 */
ptr1 = ptr1.next;
}
/* After the end of loop ptr2 is the last node of the loop. So
make next of ptr2 as NULL */
ptr2.next = null;
}
// Function to print the linked list
void printList(Node node)
{
while (node != null) {
Console.Write(node.data + " ");
node = node.next;
}
}
// Driver program to test above functions
public static void Main(String[] args)
{
LinkedList list = new LinkedList();
list.head = new Node(50);
list.head.next = new Node(20);
list.head.next.next = new Node(15);
list.head.next.next.next = new Node(4);
list.head.next.next.next.next = new Node(10);
// Creating a loop for testing
list.head.next.next.next.next.next = list.head.next.next;
list.detectAndRemoveLoop(list.head);
Console.WriteLine("Linked List after removing loop : ");
list.printList(list.head);
}
}
Method 2 (Better Solution)
- This method is also dependent on Floyd's Cycle detection algorithm.
- Detect Loop using Floyd's Cycle detection algorithm and get the pointer to a loop node.
- Count the number of nodes in loop. Let the count be k.
- Fix one pointer to the head and another to a kth node from the head.
- Move both pointers at the same pace, they will meet at loop starting node.
- Get a pointer to the last node of the loop and make next of it as NULL.
Thanks to WgpShashank for suggesting this method.
Below image is a dry run of 'remove loop' function in the code :

Below is the implementation of the above approach:
// A C# program to detect and remove loop in linked list
using System;
public class LinkedList {
Node head;
public class Node {
public int data;
public Node next;
public Node(int d)
{
data = d;
next = null;
}
}
// Function that detects loop in the list
int detectAndRemoveLoop(Node node)
{
Node slow = node, fast = node;
while (slow != null && fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
// If slow and fast meet at same
// point then loop is present
if (slow == fast) {
removeLoop(slow, node);
return 1;
}
}
return 0;
}
// Function to remove loop
void removeLoop(Node loop, Node head)
{
Node ptr1 = loop;
Node ptr2 = loop;
// Count the number of nodes in loop
int k = 1, i;
while (ptr1.next != ptr2) {
ptr1 = ptr1.next;
k++;
}
// Fix one pointer to head
ptr1 = head;
// And the other pointer to k nodes after head
ptr2 = head;
for (i = 0; i < k; i++) {
ptr2 = ptr2.next;
}
/* Move both pointers at the same pace,
they will meet at loop starting node */
while (ptr2 != ptr1) {
ptr1 = ptr1.next;
ptr2 = ptr2.next;
}
// Get pointer to the last node
while (ptr2.next != ptr1) {
ptr2 = ptr2.next;
}
/* Set the next node of the loop ending node
to fix the loop */
ptr2.next = null;
}
// Function to print the linked list
void printList(Node node)
{
while (node != null) {
Console.Write(node.data + " ");
node = node.next;
}
}
// Driver program to test above functions
public static void Main(String[] args)
{
LinkedList list = new LinkedList();
list.head = new Node(50);
list.head.next = new Node(20);
list.head.next.next = new Node(15);
list.head.next.next.next = new Node(4);
list.head.next.next.next.next = new Node(10);
// Creating a loop for testing
list.head.next.next.next.next.next = list.head.next.next;
list.detectAndRemoveLoop(list.head);
Console.WriteLine("Linked List after removing loop : ");
list.printList(list.head);
}
}
Given an unsorted array of size n. Array elements are in the range from 1 to n. One number from set {1, 2, …n} is missing and one number occurs twice in the array. Find these two numbers.
Examples:
Input: arr[] = {3, 1, 3}
Output: Missing = 2, Repeating = 3
Explanation: In the array,
2 is missing and 3 occurs twice
Input: arr[] = {4, 3, 6, 2, 1, 1}
Output: Missing = 5, Repeating = 1
Method 7 (Make two equations using sum and sum of squares)
Approach:
- Let x be the missing and y be the repeating element.
- Let N is the size of array.
- Get the sum of all numbers using formula S = N(N+1)/2
- Get product of all numbers using formula Sum_Sq = N(N+1)(2N+1)/6
- Iterate through a loop from i=1….N
- S -= A[i]
- Sum_Sq -= (A[i]*A[i])
- It will give two equations
x-y = S – (1) x^2 – y^2 = Sum_sq x+ y = (Sum_sq/S) – (2)
Time Complexity: O(n)
#include <bits/stdc++.h>
using namespace std;
vector<int>repeatedNumber(const vector<int> &A) {
long long int len = A.size();
long long int Sum_N = (len * (len+1) ) /2, Sum_NSq = (len * (len +1) *(2*len +1) )/6;
long long int missingNumber=0, repeating=0;
for(int i=0;i<A.size(); i++){
Sum_N -= (long long int)A[i];
Sum_NSq -= (long long int)A[i]*(long long int)A[i];
}
missingNumber = (Sum_N + Sum_NSq/Sum_N)/2;
repeating= missingNumber - Sum_N;
vector <int> ans;
ans.push_back(repeating);
ans.push_back(missingNumber);
return ans;
}
int main(void){
std::vector<int> v = {4, 3, 6, 2, 1, 6,7};
vector<int> res = repeatedNumber(v);
for(int x: res){
cout<< x<<" ";
}
cout<<endl;
}
Write a program to Validate an IPv4 Address.
According to Wikipedia, IPv4 addresses are canonically represented in dot-decimal notation, which consists of four decimal numbers, each ranging from 0 to 255, separated by dots, e.g., 172.16.254.1
step 1) Parse string with "." as delimiter using "strtok()" function.
filter_none
edit
play_arrow
brightness_4
| e.g. ptr = strtok(str, DELIM); |
|---|
step 2) ……..a) If ptr contains any character which is not digit then return 0 ……..b) Convert "ptr" to decimal number say 'NUM' ……..c) If NUM is not in range of 0-255 return 0 ……..d) If NUM is in range of 0-255 and ptr is non-NULL increment "dot_counter" by 1 ……..e) if ptr is NULL goto step 3 else goto step 1
step 3) if dot_counter != 3 return 0 else return 1.
A tree where no leaf is much farther away from the root than any other leaf. Different balancing schemes allow different definitions of "much farther" and different amounts of work to keep them balanced.
Consider a height-balancing scheme where following conditions should be checked to determine if a binary tree is balanced. An empty tree is height-balanced. A non-empty binary tree T is balanced if:
- Left subtree of T is balanced
- Right subtree of T is balanced
- The difference between heights of left subtree and right subtree is not more than 1.
The above height-balancing scheme is used in AVL trees. The diagram below shows two trees, one of them is height-balanced and other is not. The second tree is not height-balanced because height of left subtree is 2 more than height of right subtree.

using System;
/* C# program to determine if binary tree is
height balanced or not */
/* A binary tree node has data, pointer to left child,
and a pointer to right child */
public class Node {
public int data;
public Node left, right;
public Node(int d)
{
data = d;
left = right = null;
}
}
// A wrapper class used to modify height across
// recursive calls.
public class Height {
public int height = 0;
}
public class BinaryTree {
public Node root;
/* Returns true if binary tree with root as root is height-balanced */
public virtual bool isBalanced(Node root, Height height)
{
/* If tree is empty then return true */
if (root == null) {
height.height = 0;
return true;
}
/* Get heights of left and right sub trees */
Height lheight = new Height(), rheight = new Height();
bool l = isBalanced(root.left, lheight);
bool r = isBalanced(root.right, rheight);
int lh = lheight.height, rh = rheight.height;
/* Height of current node is max of heights of
left and right subtrees plus 1*/
height.height = (lh > rh ? lh : rh) + 1;
/* If difference between heights of left and right
subtrees is more than 2 then this node is not balanced
so return 0 */
if ((lh - rh >= 2) || (rh - lh >= 2)) {
return false;
}
/* If this node is balanced and left and right subtrees
are balanced then return true */
else {
return l && r;
}
}
/* The function Compute the "height" of a tree. Height is the
number of nodes along the longest path from the root node
down to the farthest leaf node.*/
public virtual int height(Node node)
{
/* base case tree is empty */
if (node == null) {
return 0;
}
/* If tree is not empty then height = 1 + max of left
height and right heights */
return 1 + Math.Max(height(node.left), height(node.right));
}
public static void Main(string[] args)
{
Height height = new Height();
/* Constructed binary tree is
1
/ \
2 3
/ \ /
4 5 6
/
7 */
BinaryTree tree = new BinaryTree();
tree.root = new Node(1);
tree.root.left = new Node(2);
tree.root.right = new Node(3);
tree.root.left.left = new Node(4);
tree.root.left.right = new Node(5);
tree.root.right.right = new Node(6);
tree.root.left.left.left = new Node(7);
if (tree.isBalanced(tree.root, height)) {
Console.WriteLine("Tree is balanced");
}
else {
Console.WriteLine("Tree is not balanced");
}
}
}
Two of the nodes of a Binary Search Tree (BST) are swapped. Fix (or correct) the BST.
Input Tree:
10
/ \
5 8
/ \
2 20
In the above tree, nodes 20 and 8 must be swapped to fix the tree.
Following is the output tree
10
/ \
5 20
/ \
2 8
Recommended: Please solve it on "PRACTICE" first, before moving on to the solution.
The inorder traversal of a BST produces a sorted array. So a simple method is to store inorder traversal of the input tree in an auxiliary array. Sort the auxiliary array. Finally, insert the auxiilary array elements back to the BST, keeping the structure of the BST same. Time complexity of this method is O(nLogn) and auxiliary space needed is O(n).
We can solve this in O(n) time and with a single traversal of the given BST. Since inorder traversal of BST is always a sorted array, the problem can be reduced to a problem where two elements of a sorted array are swapped. There are two cases that we need to handle:
1. The swapped nodes are not adjacent in the inorder traversal of the BST.
For example, Nodes 5 and 25 are swapped in {3 5 7 8 10 15 20 25}.
The inorder traversal of the given tree is 3 25 7 8 10 15 20 5
If we observe carefully, during inorder traversal, we find node 7 is smaller than the previous visited node 25. Here save the context of node 25 (previous node). Again, we find that node 5 is smaller than the previous node 20. This time, we save the context of node 5 ( current node ). Finally swap the two node's values.
2. The swapped nodes are adjacent in the inorder traversal of BST.
For example, Nodes 7 and 8 are swapped in {3 5 7 8 10 15 20 25}.
The inorder traversal of the given tree is 3 5 8 7 10 15 20 25
Unlike case #1, here only one point exists where a node value is smaller than previous node value. e.g. node 7 is smaller than node 8.
How to Solve? We will maintain three pointers, first, middle and last. When we find the first point where current node value is smaller than previous node value, we update the first with the previous node & middle with the current node. When we find the second point where current node value is smaller than previous node value, we update the last with the current node. In case #2, we will never find the second point. So, last pointer will not be updated. After processing, if the last node value is null, then two swapped nodes of BST are adjacent.
Following is the implementation of the given code.
// Java program to correct the BST
// if two nodes are swapped
import java.util.*;
import java.lang.*;
import java.io.*;
class Node {
int data;
Node left, right;
Node(int d) {
data = d;
left = right = null;
}
}
class BinaryTree
{
Node first, middle, last, prev;
// This function does inorder traversal
// to find out the two swapped nodes.
// It sets three pointers, first, middle
// and last. If the swapped nodes are
// adjacent to each other, then first
// and middle contain the resultant nodes
// Else, first and last contain the
// resultant nodes
void correctBSTUtil( Node root)
{
if( root != null )
{
// Recur for the left subtree
correctBSTUtil( root.left);
// If this node is smaller than
// the previous node, it's
// violating the BST rule.
if (prev != null && root.data <
prev.data)
{
// If this is first violation,
// mark these two nodes as
// 'first' and 'middle'
if (first == null)
{
first = prev;
middle = root;
}
// If this is second violation,
// mark this node as last
else
last = root;
}
// Mark this node as previous
prev = root;
// Recur for the right subtree
correctBSTUtil( root.right);
}
}
// A function to fix a given BST where
// two nodes are swapped. This function
// uses correctBSTUtil() to find out
// two nodes and swaps the nodes to
// fix the BST
void correctBST( Node root )
{
// Initialize pointers needed
// for correctBSTUtil()
first = middle = last = prev = null;
// Set the poiters to find out
// two nodes
correctBSTUtil( root );
// Fix (or correct) the tree
if( first != null && last != null )
{
int temp = first.data;
first.data = last.data;
last.data = temp;
}
// Adjacent nodes swapped
else if( first != null && middle !=
null )
{
int temp = first.data;
first.data = middle.data;
middle.data = temp;
}
// else nodes have not been swapped,
// passed tree is really BST.
}
/* A utility function to print
Inoder traversal */
void printInorder(Node node)
{
if (node == null)
return;
printInorder(node.left);
System.out.print(" " + node.data);
printInorder(node.right);
}
// Driver program to test above functions
public static void main (String[] args)
{
/* 6
/ \
10 2
/ \ / \
1 3 7 12
10 and 2 are swapped
*/
Node root = new Node(6);
root.left = new Node(10);
root.right = new Node(2);
root.left.left = new Node(1);
root.left.right = new Node(3);
root.right.right = new Node(12);
root.right.left = new Node(7);
System.out.println("Inorder Traversal"+
" of the original tree");
BinaryTree tree = new BinaryTree();
tree.printInorder(root);
tree.correctBST(root);
System.out.println("\nInorder Traversal"+
" of the fixed tree");
tree.printInorder(root);
}
}