VoiceFilter
Note from Seung-won (2020.10.25)
Hi everyone! It's Seung-won from MINDs Lab, Inc. It's been a long time since I've released this open-source, and I didn't expect this repository to grab such a great amount of attention for a long time. I would like to thank everyone for giving such attention, and also Mr. Quan Wang (the first author of the VoiceFilter paper) for referring this project in his paper.
Actually, this project was done by me when it was only 3 months after I started studying deep learning & speech separation without a supervisor in the relevant field. Back then, I didn't know what is a power-law compression, and the correct way to validate/test the models. Now that I've spent more time on deep learning & speech since then (I also wrote a paper published at Interspeech 2020 😊), I can observe some obvious mistakes that I've made. Those issues were kindly raised by GitHub users; please refer to the Issues and Pull Requests for that. That being said, this repository can be quite unreliable, and I would like to remind everyone to use this code at their own risk (as specified in LICENSE).
Unfortunately, I can't afford extra time on revising this project or reviewing the Issues / Pull Requests. Instead, I would like to offer some pointers to newer, more reliable resources:
- VoiceFilter-Lite: This is a newer version of VoiceFilter presented at Interspeech 2020, which is also written by Mr. Quan Wang (and his colleagues at Google). I highly recommend checking this paper, since it focused on a more realistic situation where VoiceFilter is needed.
- List of VoiceFilter implementation available on GitHub: In March 2019, this repository was the only available open-source implementation of VoiceFilter. However, much better implementations that deserve more attention became available across GitHub. Please check them, and choose the one that meets your demand.
- PyTorch Lightning: Back in 2019, I could not find a great deep-learning project template for myself, so I and my colleagues had used this project as a template for other new projects. For people who are searching for such project template, I would like to strongly recommend PyTorch Lightning. Even though I had done a lot of effort into developing my own template during 2019 (VoiceFilter -> RandWireNN -> MelNet -> MelGAN), I found PyTorch Lightning much better than my own template.
Thanks for reading, and I wish everyone good health during the global pandemic situation.
Best regards, Seung-won Park
Unofficial PyTorch implementation of Google AI's: VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking.

Result
- Training took about 20 hours on AWS p3.2xlarge(NVIDIA V100).
Audio Sample
- Listen to audio sample at webpage: http://swpark.me/voicefilter/
Metric
| Median SDR | Paper | Ours |
|---|---|---|
| before VoiceFilter | 2.5 | 1.9 |
| after VoiceFilter | 12.6 | 10.2 |

- SDR converged at 10, which is slightly lower than paper's.
Dependencies
-
Python and packages
This code was tested on Python 3.6 with PyTorch 1.0.1. Other packages can be installed by:
pip install -r requirements.txt
-
Miscellaneous
ffmpeg-normalize is used for resampling and normalizing wav files. See README.md of ffmpeg-normalize for installation.
Prepare Dataset
-
Download LibriSpeech dataset
To replicate VoiceFilter paper, get LibriSpeech dataset at http://www.openslr.org/12/.
train-clear-100.tar.gz(6.3G) contains speech of 252 speakers, andtrain-clear-360.tar.gz(23G) contains 922 speakers. You may use either, but the more speakers you have in dataset, the more better VoiceFilter will be. -
Resample & Normalize wav files
First, unzip
tar.gzfile to desired folder:tar -xvzf train-clear-360.tar.gz
Next, copy
utils/normalize-resample.shto root directory of unzipped data folder. Then:vim normalize-resample.sh # set "N" as your CPU core number. chmod a+x normalize-resample.sh ./normalize-resample.sh # this may take long
-
Edit
config.yamlcd config cp default.yaml config.yaml vim config.yaml -
Preprocess wav files
In order to boost training speed, perform STFT for each files before training by:
python generator.py -c [config yaml] -d [data directory] -o [output directory] -p [processes to run]
This will create 100,000(train) + 1000(test) data. (About 160G)
Train VoiceFilter
-
Get pretrained model for speaker recognition system
VoiceFilter utilizes speaker recognition system (d-vector embeddings). Here, we provide pretrained model for obtaining d-vector embeddings.
This model was trained with VoxCeleb2 dataset, where utterances are randomly fit to time length [70, 90] frames. Tests are done with window 80 / hop 40 and have shown equal error rate about 1%. Data used for test were selected from first 8 speakers of VoxCeleb1 test dataset, where 10 utterances per each speakers are randomly selected.
Update: Evaluation on VoxCeleb1 selected pair showed 7.4% EER.
The model can be downloaded at this GDrive link.
-
Run
After specifying
train_dir,test_diratconfig.yaml, run:python trainer.py -c [config yaml] -e [path of embedder pt file] -m [name]
This will create
chkpt/nameandlogs/nameat base directory(-boption,.in default) -
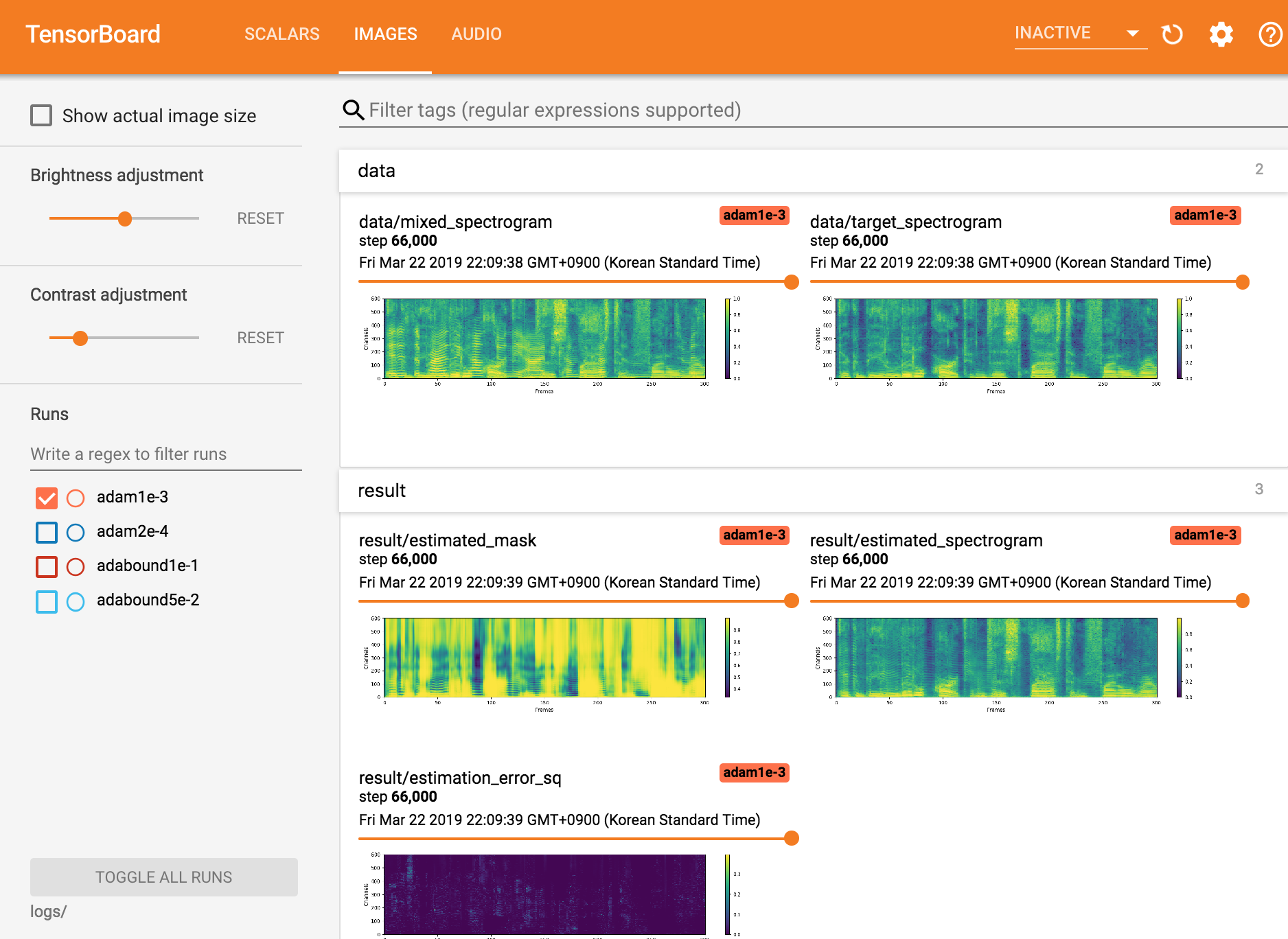
View tensorboardX
tensorboard --logdir ./logs
-
Resuming from checkpoint
python trainer.py -c [config yaml] --checkpoint_path [chkpt/name/chkpt_{step}.pt] -e [path of embedder pt file] -m name

Evaluate
python inference.py -c [config yaml] -e [path of embedder pt file] --checkpoint_path [path of chkpt pt file] -m [path of mixed wav file] -r [path of reference wav file] -o [output directory]Possible improvments
- Try power-law compressed reconstruction error as loss function, instead of MSE. (See #14)
Author
Seungwon Park at MINDsLab (yyyyy@snu.ac.kr, swpark@mindslab.ai)
License
Apache License 2.0
This repository contains codes adapted/copied from the followings:
- utils/adabound.py from https://github.com/Luolc/AdaBound (Apache License 2.0)
- utils/audio.py from https://github.com/keithito/tacotron (MIT License)
- utils/hparams.py from https://github.com/HarryVolek/PyTorch_Speaker_Verification (No License specified)
- utils/normalize-resample.sh from https://unix.stackexchange.com/a/216475