This repository contains an implementation of Generating Videos with Scene Dynamics by Carl Vondrick, Hamed Pirsiavash, Antonio Torralba, to appear at NIPS 2016. The model learns to generate tiny videos using adversarial networks.
Below are some selected videos that are generated by our model. These videos are not real; they are hallucinated by a generative video model. While they are not photo-realistic, the motions are fairly reasonable for the scene category they are trained on.
Beach



 



 




|
Golf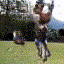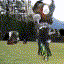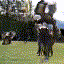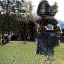
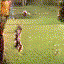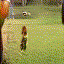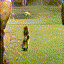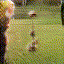


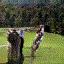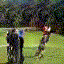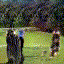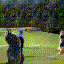 

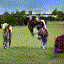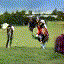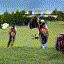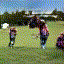

 
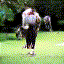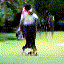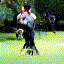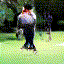

|
Train Station



 
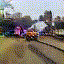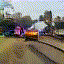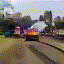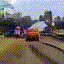






|
Baby






 




|
The code requires a Torch7 installation.
To train a generator for video, see main.lua. This file will construct the networks, start many threads to load data, and train the networks.
For the conditional version, see main_conditional.lua. This is similar to main.lua, except the input to the model is a static image.
To generate videos, see generate.lua. This file will also output intermediate layers, such as the mask and background image, which you can inspect manually.
The data loading is designed assuming videos have been stabilized and flattened into JPEG images. We do this for efficiency. Stabilization is computationally slow and must be done offline, and reading one file per video is more efficient on NFS.
For our stabilization code, see the 'extra' directory. Essentially, this will convert each video into an image of vertically concatenated frames. After doing this, you create a text file listing all the frames, which you pass into the data loader.
You can download our pre-trained models here (1 GB ZIP file).
The code is based on DCGAN and our starter code in Torch7.
If you find this useful for your research, please consider citing our NIPS paper.
MIT