- A python script
demo.pythat uses a pre-trained model to detect objects in a point cloud. (without downloading data | SUN RGB-D val set samples and pre-trained model provided indemofolder). CheckRun Demo. - A python script
fasterRCNN_detections.pythat uses a pre-trained Faster RCNN model trained on the Open Images V4 dataset to output 2D object detections in the format required by ImVoteNet. CheckFasterRCNN Detectionsat the end of the file. - Fixes to issues I ran into while training. Check
Fixesat the end of the file.
Boosting 3D Object Detection in Point Clouds with Image Votes
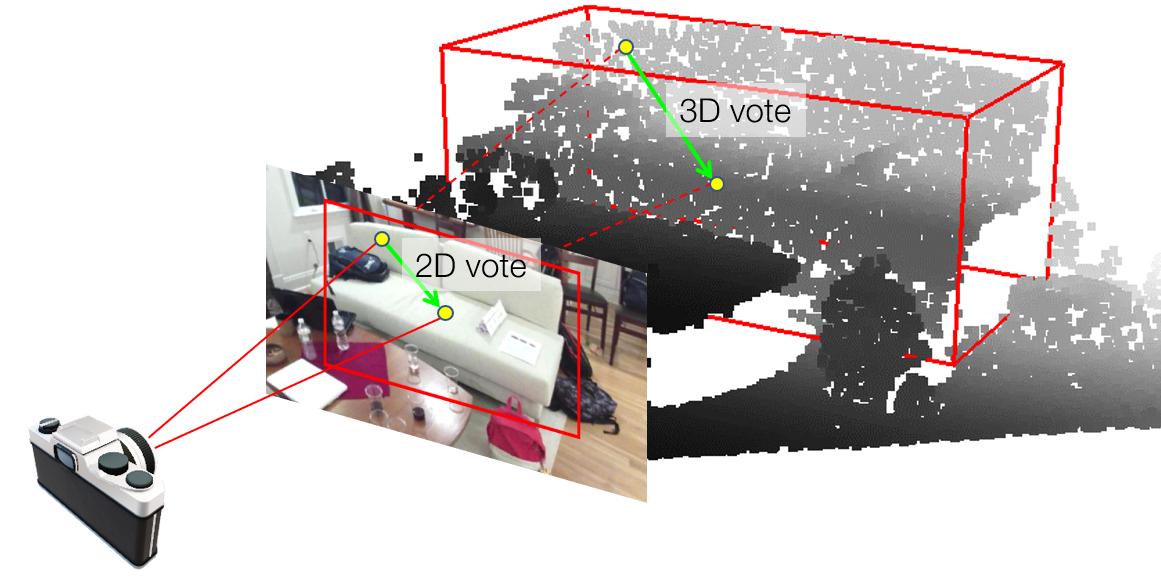
This repository contains the code release of the paper:
@inproceedings{qi2020imvotenet,
title={Imvotenet: Boosting 3d object detection in point clouds with image votes},
author={Qi, Charles R and Chen, Xinlei and Litany, Or and Guibas, Leonidas J},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2020}
}
Overall, the installation is similar to VoteNet. GPU is required. The code is tested with Ubuntu 18.04, Python 3.7.7, PyTorch 1.4.0, CUDA 10.0 and cuDNN v7.4.
First install PyTorch, for example through Anaconda:
conda install pytorch torchvision cudatoolkit=10.0 -c pytorchNext, install Python dependencies via pip (tensorboardX is used for for visualizations):
pip install matplotlib opencv-python plyfile tqdm networkx==2.2 trimesh==2.35.39
pip install tensorboardX --no-depsNow we are ready to clone this repository:
git clone git@github.com:Sakshee5/imvotenet.git
cd imvotenetThe code depends on PointNet++ as a backbone, which needs compilation:
cd pointnet2
python setup.py install
cd ..The pre-trained model with sample point clouds, RGB Images, Depth Maps, Camera Calib and the 2D bounding box detections are available in the demo folder. After completing installation, Run:
python demo.pyThe demo uses a pre-trained model (on SUN RGB-D) to detect objects in a point cloud from an indoor room (from SUN RGB-D val set). You can use 3D visualization software such as the MeshLab to open the dumped file under demo/results to see the 3D detection output. Specifically, open ***_pc.ply and ***_pred_confident_nms_bbox.ply to see the input point cloud and predicted 3D bounding boxes. Incase you want to check the class labels of the detected objects, set inference_switch = True in the second last line of demo.py. You can check the ***_pred_map_cls.txt to get the class labels.
The ImVoteNet model needs the point cloud as well as the geometric, semantic and texture cues extracted from the RGB Image as input. demo.py creates a pipeline that inputs the RGB Image, Depth Map, Camera Calib and the 2D bounding box detections (Faster RCNN 2d object detection backbone output) to output all necessary inputs for ImVoteNet model in the right format. It further uses the pre-trained model to detect objects.
Please follow the steps listed here to set up the SUN RGB-D dataset in the sunrgbd folder. The expected dataset structure under sunrgbd is:
sunrgbd/
sunrgbd_pc_bbox_votes_50k_{v1,v2}_{train,val}/
sunrgbd_trainval/
# raw image data and camera used by ImVoteNet
calib/*.txt
image/*.jpg
For ImVoteNet, we provide 2D detection results from a pre-trained Faster R-CNN detector here. Please download the file, uncompress it, and place the resulting folders (sunrgbd_2d_bbox_50k_v1_{train,val}) under sunrgbd as well.
Once the code and data are set up, one can train ImVoteNet by the following command:
CUDA_VISIBLE_DEVICES=0 python train.py --use_imvotenet --log_dir log_imvotenetThe setting CUDA_VISIBLE_DEVICES=0 forces the model to be trained on a single GPU (GPU 0 in this case). With the default batch size of 8, it takes about 7G memory during training.
To reproduce the experimental results in the paper and in general have faster development cycles, one can use a shorter learning schedule:
CUDA_VISIBLE_DEVICES=1 python train.py --use_imvotenet --log_dir log_140ep --max_epoch 140 --lr_decay_steps 80,120 --lr_decay_rates 0.1,0.1As a baseline, this code also supports training of the original VoteNet, which is launched by:
CUDA_VISIBLE_DEVICES=2 python train.py --log_dir log_votenetIn fact, the code is based on the VoteNet repository at commit 2f6d6d3, as a reference, it gives around 58 mAP@0.25.
For other training options, one can use python train.py -h for assistance.
After the model is trained, the checkpoint can be tested and evaluated on the val set via:
python eval.py --use_imvotenet --checkpoint_path log_imvotenet/checkpoint.tar --dump_dir eval_imvotenet --cluster_sampling seed_fps --use_3d_nms --use_cls_nms --per_class_proposalFor reference, ImVoteNet gives around 63 mAP@0.25.
- Add docs for some functions
- Investigate the 0.5 mAP@0.25 gap after moving to PyTorch 1.4.0. (Originally the code is based on PyTorch 1.0.)
The code is released under the MIT license.
The official ImVoteNet repository does not provide the pre-trained Faster RCNN model. Instead you are directly supposed to download the .txt files and use them for training.
(Refer: For ImVoteNet, we provide 2D detection results from a pre-trained Faster R-CNN detector here.)
Currently the demo.py script directly uses RGB Images from the SUN RGB-D val dataset and thus the 2D bbox detections can directly be downloaded and used. But incase we want to run the demo script on a custom RGB Image, we need the 2D bbox detection in the right format to run the demo script.
fasterRCNN_detections.py uses a pretrained Faster RCNN on Open Images V4 Dataset from the tensorflow-hub. It's been trained on 600 categories with ImageNet pre-trained Inception Resnet V2 as image feature extractor. The inference block added in the script makes sure that only objects of interest are detected and saved in a .txt file as required by ImvoteNet.
Firtly install dependencies:
pip install tensorflow-gpu
pip install tensorflow-hub
Run:
python fasterRCNN_detections.pyCheck demo/FasterRCNN_labels to get the corresponding text file which can inturn be used with the demo.py script.
Categories of interest from sun rgbd | possible category from the 600 categories of Open Images Dataset
bed | Bed
table | Table
sofa | Sofa bed
chair | Chair
toilet | Toilet
desk | Desk
dresser | Filing cabinet
night_stand | Nightstand
bookshelf | Bookcase
bathtub | Bathtub
-
Error while compiling PointNet2 with newer/higher CUDA version (like CUDA>=11.0)
FIX:- Change all instances of AT_CHECK to TORCH_CHECK inside all the source files inside
pointnet2/_ext_src/src and pointnet2/_ext_src/include. This is due to an API change in PyTorch. - Change pointnet2/setup.py:
# Copyright (c) Facebook, Inc. and its affiliates. # # This source code is licensed under the MIT license found in the # LICENSE file in the root directory of this source tree. from setuptools import setup from torch.utils.cpp_extension import BuildExtension, CUDAExtension import glob import os _ext_src_root = "_ext_src" _ext_sources = glob.glob("{}/src/*.cpp".format(_ext_src_root)) + glob.glob( "{}/src/*.cu".format(_ext_src_root) ) _ext_headers = glob.glob("{}/include/*".format(_ext_src_root)) headers = "-I" + os.path.join(os.path.dirname(os.path.abspath(__file__)), '_ext_src', 'include') setup( name='pointnet2', ext_modules=[ CUDAExtension( name='pointnet2._ext', sources=_ext_sources, extra_compile_args={ "cxx": ["-O2", headers], "nvcc": ["-O2", headers] }, ) ], cmdclass={ 'build_ext': BuildExtension } )
- Change all instances of AT_CHECK to TORCH_CHECK inside all the source files inside
-
Error message before training: ImportError: No module named 'google'
FIX: Runpip install --upgrade google-api-python-client
-
Error message: AttributeError: ‘Fraction’ object has no attribute ‘gcd’
FIX:
A minor change is needed in the site-packages of your virtual environment.
Openpath to env/lib/python_3.8/site-packages/networkx/algorithms/dag.py
Changefrom fractions import gcdtoimport math
Change the one gcd instance in the file fromgcd()tomath.gcd()