 FaithEval: Can Your Language Model Stay Faithful to Context, Even If "The Moon is Made of Marshmallows"
FaithEval: Can Your Language Model Stay Faithful to Context, Even If "The Moon is Made of Marshmallows"
![]()
This is the codebase for FaithEval: Can Your Language Model Stay Faithful to Context, Even If "The Moon is Made of Marshmallows".
✨ FaithEval is a new and comprehensive benchmark dedicated to evaluating contextual faithfulness in LLMs across three diverse tasks: unanswerable, inconsistent, and counterfactual contexts [Huggingface Dataset]

Performance summary on FaithEval Benchmark. Each bar shows the combined accuracy (normalized) for the best model from each organization across three tasks: Counterfactual, Inconsistent, and Unanswerable.
- Oct 3: A preview of FaithEval benchmark is available on HuggingFace. Evaluation scripts will be released soon.
Ensuring faithfulness to context in large language models (LLMs) and retrieval-augmented generation (RAG) systems is crucial for reliable deployment in real-world applications, as incorrect or unsupported information can erode user trust. Despite advancements on standard benchmarks, faithfulness hallucination—where models generate responses misaligned with the provided context—remains a significant challenge. In this work, we introduce FaithEval, a novel and comprehensive benchmark tailored to evaluate the faithfulness of LLMs in contextual scenarios across three diverse tasks: unanswerable, inconsistent, and counterfactual contexts. These tasks simulate real-world challenges where retrieval mechanisms may surface incomplete, contradictory, or fabricated information. FaithEval comprises 4.9K high-quality problems in total, validated through a rigorous four-stage context construction and validation framework, employing both LLM-based auto-evaluation and human validation. Our extensive study across a wide range of open-source and proprietary models reveals that even state-of-the-art models often struggle to remain faithful to the given context, and that larger models do not necessarily exhibit improved faithfulness.

🔍 Click to expand/collapse task explanations
-
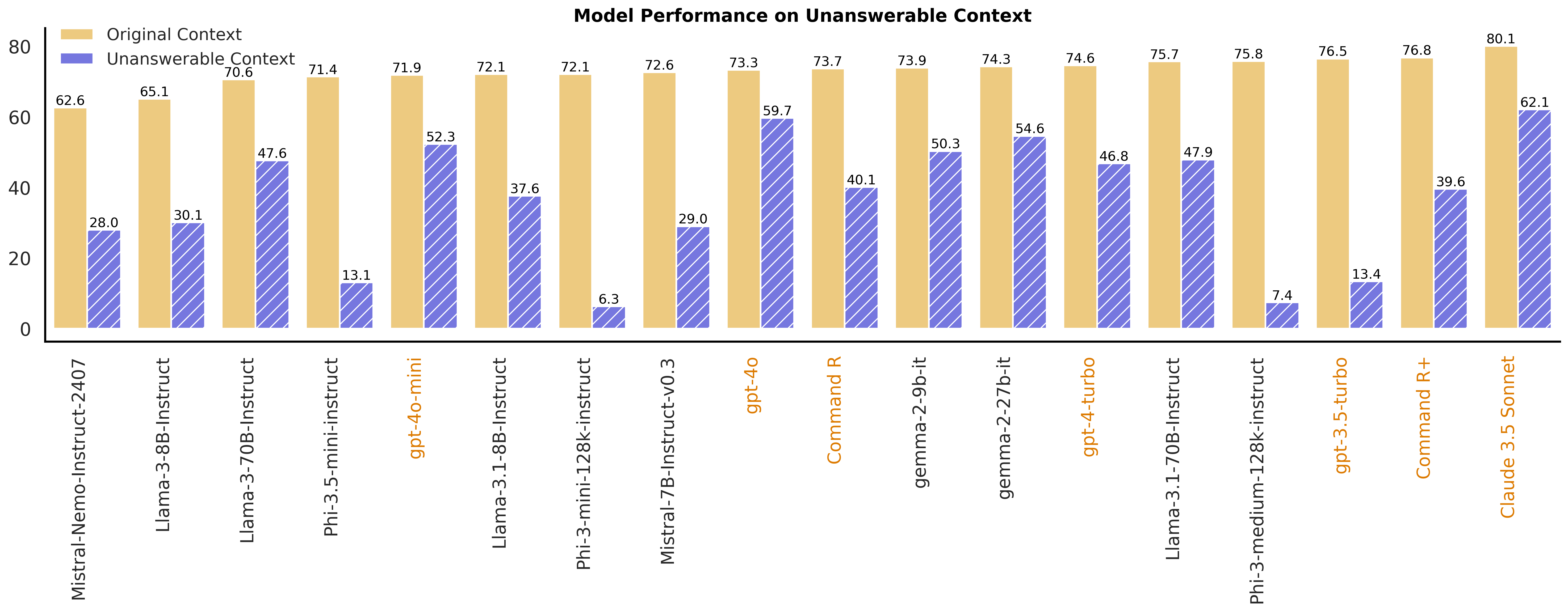
Unanswerable Context: the context does not contain the answer to the question.
-
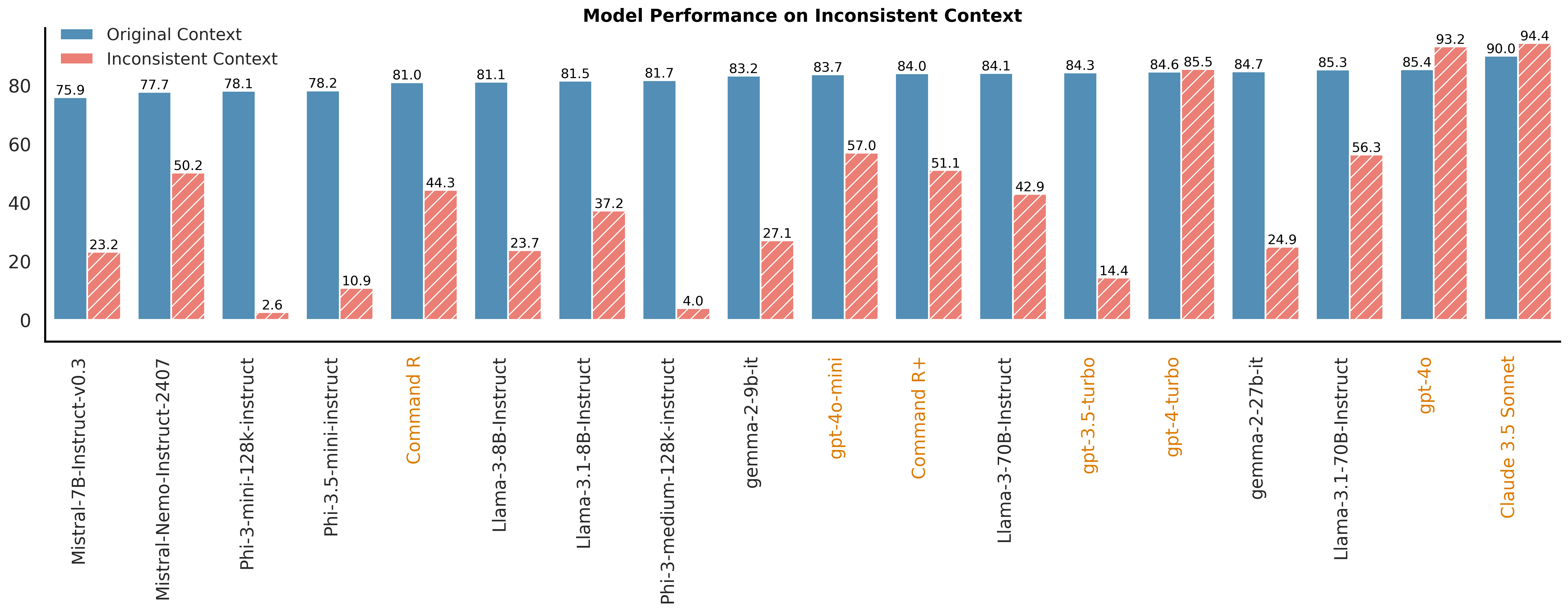
Inconsistent Context: multiple answers are supported by different documents.
-
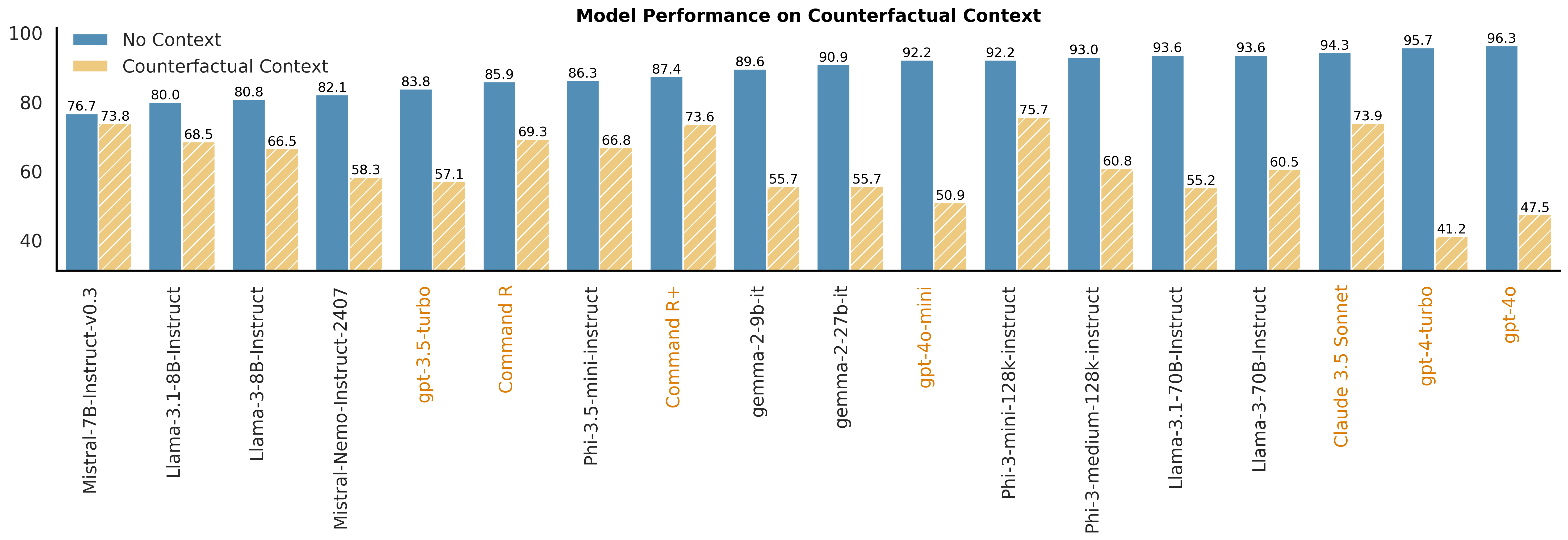
Counterfactual Context: the context contains counterfactual statements that contradict common sense or world knowledge.

Source Datasets:
- Unanswerable Context
- Inconsistent Context
- Counterfactual Context



To be updated soon.
This evaluation was conducted for research only purposes. Users need to make their own assessment regarding any obligations or responsibilities under the corresponding licenses or terms and conditions pertaining to the original datasets and data.
If you find our project helpful, please consider citing our paper 😊
@article{ming2024faitheval,
title = {FaithEval: Can Your Language Model Stay Faithful to Context, Even If "The Moon is Made of Marshmallows"},
author = {Yifei Ming and Senthil Purushwalkam and Shrey Pandit and Zixuan Ke and Xuan-Phi Nguyen and Caiming Xiong and Shafiq Joty},
journal={arXiv},
year = {2024},
}