A Model, selected at random, from the dataset of the paper Taskonomy: Disentangling Task Transfer Learning. See the main repository of Taskonomy dataset for more details about the full data here.
This is only a single model (a small fraction of the dataset) as a sample. The full dataset includes > 4.5 million images from > 500 buildings with a similar format. Each image has annotations for every one of the 2D, 3D, and semantic tasks in Taskonomy's dictionary (see below).
For more details, please see the CVPR 2018 paper. Please also see the main repository and project website.
- Intro
- Website and sample model
- Data Statistics
- Image-level statistics
- Point-level statistics
- Camera-level statistics
- Model-level statistics
- Explanation of folder structure and points
The dataset consists of over 4.6 million images from 537 different buildings. The images are from indoor scenes. Images with people visible were exluded and we didn't include camera roll (pitch and yaw included). Below are some statistics about the images which comprise the dataset.
| Property | Mean | Distribution |
|---|---|---|
| Camera Pitch | 0.24° | 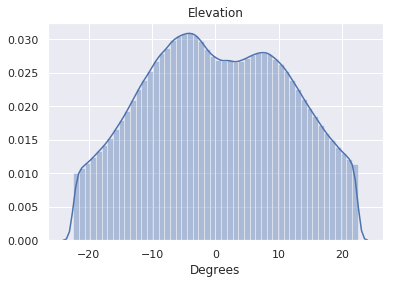 |
| Camera Roll | 0.0° | 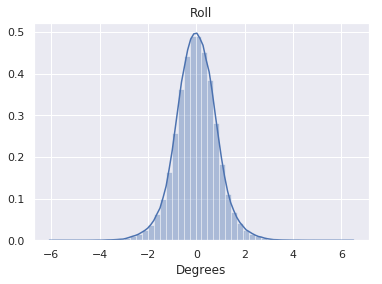 |
| Camera Field of View | 61.2° | 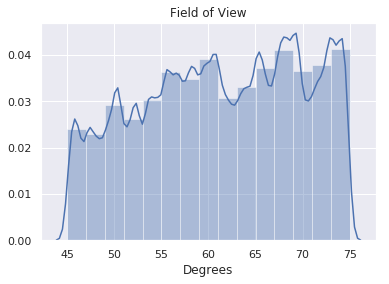 |
| Distance (from camera to scene content) | 5.3m | 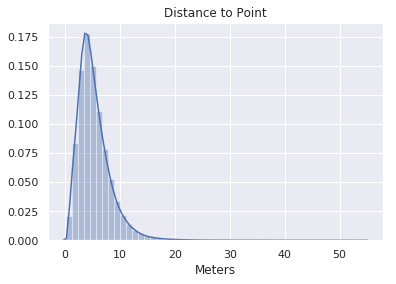 |
| 3D Obliqueness of Scene Content (wrt camera) | 52.9° | 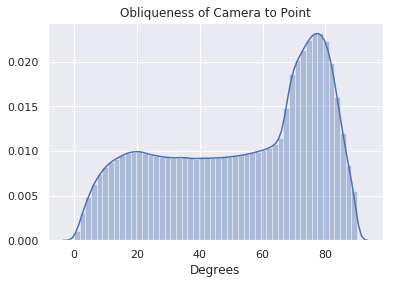 |
| Points in View (for point correspondences) | (median) 55 | 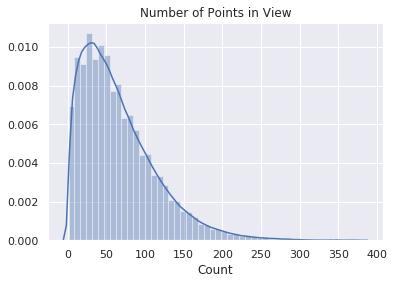 |
| Property | Mean | Distribution |
|---|---|---|
| Cameras per Point | (median) 5 | 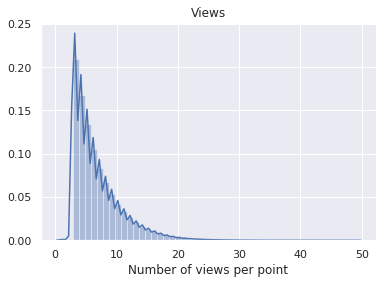 |
| Property | Mean | Distribution |
|---|---|---|
| Points/Camera | 20.8 | 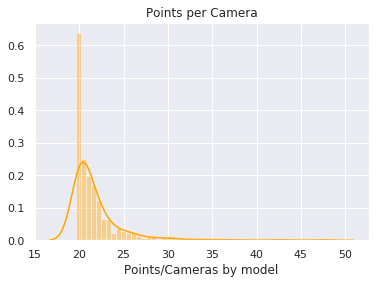 |
| Property | Mean | Distribution |
|---|---|---|
| Image Count | 0.0° | 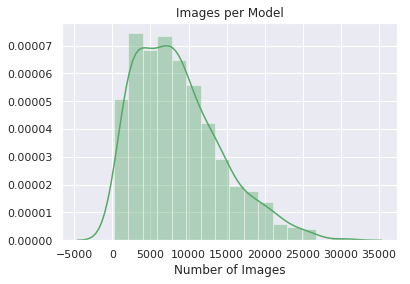 |
| Point Count | -0.77° | 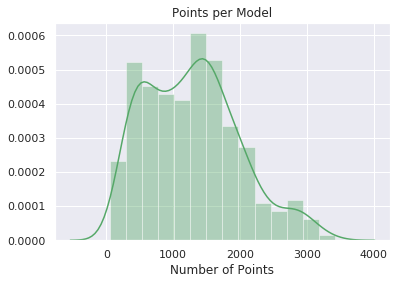 |
| Camera Count | 75° | 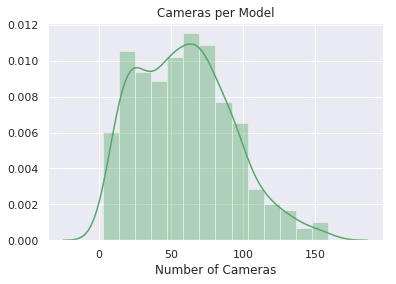 |
A model, selected at random, from the training set of the paper is shared in the repository. The folder structure is described below:
class_object/
Object classification (Imagenet 1000) annotation distilled from ResNet-152
class_scene/
Scene classification annotations distilled from PlaceNet
depth_euclidean/
Euclidian distance images.
Units of 1/512m with a max range of 128m.
depth_zbuffer/
Z-buffer depth images.
Units of 1/512m with a max range of 128m.
edge_occlusion/
Occlusion (3D) edge images.
edge_texture/
2D texture edge images.
keypoints2d/
2D keypoint heatmaps.
keypoints3d/
3D keypoint heatmaps.
nonfixated_matches/
All (point', view') which have line-of-sight and a view of "point" within the camera frustum
normal/
Surface normal images.
127-centered
points/
Metadata about each (point, view).
For each image, we keep track of the optical center of the image.
This is uniquely identified by the pair (point, view).
Contains annotations for:
Room layout
Vanishing point
Point matching
Relative camera pose esimation (fixated)
Egomotion
And other low-dimensional geometry tasks.
principal_curvature/
Curvature images.
Principal curvatures are encoded in the first two channels.
Zero curvature is encoded as the pixel value 127
reshading/
Images of the mesh rendered with new lighting.
rgb/
RGB images in 512x512 resolution.
rgb_large/
RGB images in 1024x1024 resolution.
segment_semantic/
Semantic segmentation annotations distilled from [FCIS](https://arxiv.org/pdf/1611.07709.pdf)
segment_unsup2d/
Pixel-level unsupervised superpixel annotations based on RGB.
segment_unsup25d/
Pixel-level unsupervised superpixel annotations based on RGB + Normals + Depth + Curvature.
If you find the code, data, or the models useful, please cite this paper:
@inproceedings{zamir2018taskonomy,
title={Taskonomy: Disentangling Task Transfer Learning},
author={Zamir, Amir R and Sax, Alexander and Shen, William B and Guibas, Leonidas and Malik, Jitendra and Savarese, Silvio},
booktitle={2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2018},
organization={IEEE}
}