This project is primarily educational. It is designed to help understand the workings of various ensemble learning algorithms by building them from scratch. The implementations focus on fundamental concepts rather than on optimizing for speed or robustness, using only numpy for array processing and custom datasets for specific tasks.
This project includes implementations of custom random forest classifiers and regressors, as well as a gradient boosted decision tree regressor. The main Python files are:
-
dataPrep.py: Contains theDataPrepclass for preparing data for machine learning models, including functions for one-hot encoding non-numerical columns and writing data to CSV files. -
decisionTreeClassifier.py: Implements a decision tree classifier along with utility functions for computing entropy, partitioning classes, and calculating information gain. -
decisionTreeRegressor.py: Implements a decision tree regressor with utility functions for computing variance, partitioning classes, and calculating information gain. -
randomForestClassifier.py: Implements a custom random forest classifier with utility functions for computing entropy, partitioning classes, and calculating information gain. -
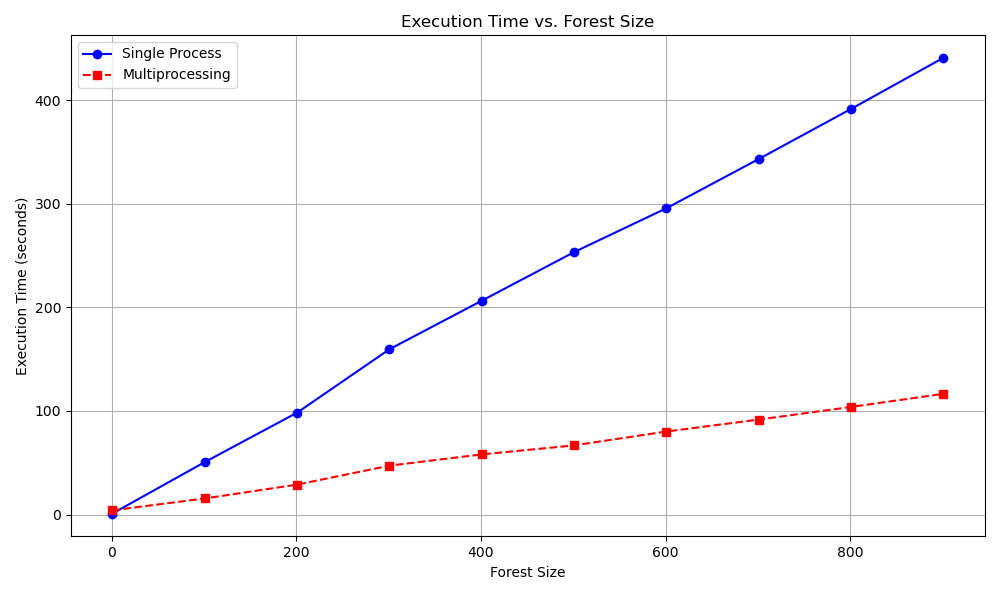
randomForestClassifierPar.py: Updated randomForestClassifier.py to implemented with multiprocessing for performance gain. -
randomForestRegressor.py: Implements a custom random forest regressor with utility functions for computing variance, partitioning classes, and calculating information gain. -
gradientBoostedRegressor.py: Implements a gradient boosted decision tree regressor for regression tasks. -
runRandomForest.py: Contains functions to run the random forest classifier and regressor on various datasets.
-
Wisconsin_breast_prognostic.csv: Dataset used for the Wisconsin Breast Prognostic dataset analysis. -
pima-indians-diabetes.csv: Dataset used for the Pima Indians Diabetes dataset analysis. -
output_May-06-2024_cleaned.csv: Car listing data scraped from cars.com via the repository "used_car_price_visualization".
The run function in gradientBoostedRegressor.py demonstrates how to prepare data, train the model, and evaluate its performance:
def run():
"""
Runs Gradient Boosted Decision Trees on the given dataset.
"""
# Source file location
file_orig = "data/carsDotCom.csv"
# Prepare and format data
df, file_loc = dp.DataPrep.prepare_data(file_orig, label_col_index=4, cols_to_encode=[1,2,3])
# Initialize GBDT object
gbdtDiab = gradientBoostedRegressor(file_loc, num_trees=10, random_seed=0, max_depth=3)
# Train GBDT model
gbdtDiab.fit(stats=True)
# Predict target values
predictions = gbdtDiab.predict()
# Get stats
stats = gbdtDiab.get_stats(predictions)
print(stats)
if __name__ == "__main__":
run()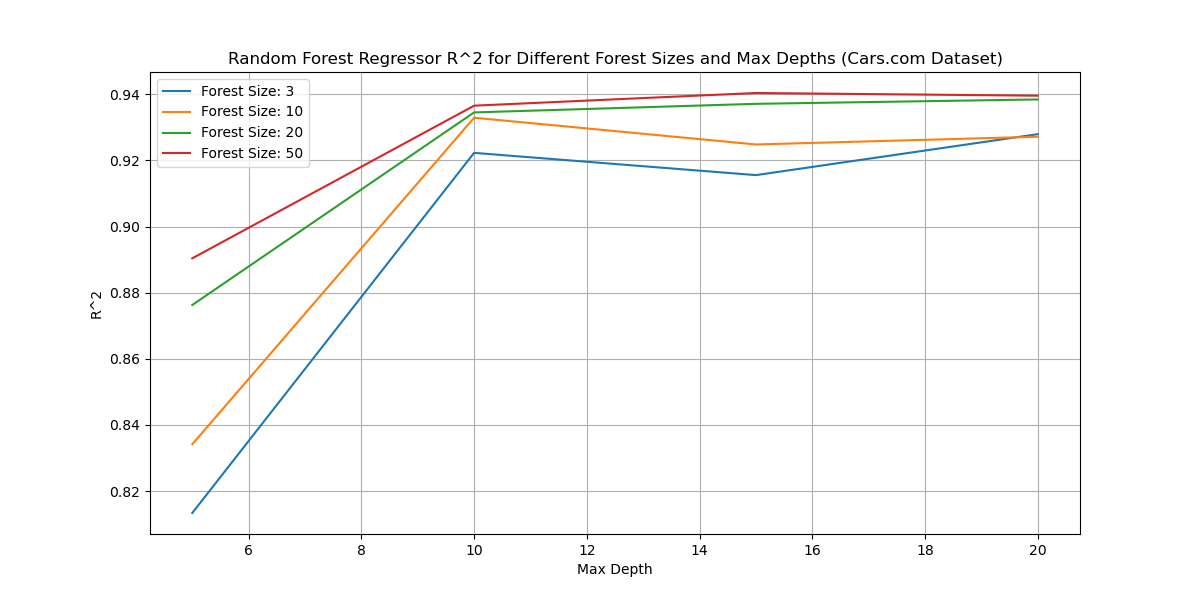
-
one_hot_encode(df, cols): One-hot encodes non-numerical columns in a DataFrame. -
write_data(df, csv_file): Writes the DataFrame to a CSV file. -
prepare_data(csv_file, label_col_index, cols_to_encode=[], write_to_csv=True): Prepares the data by loading a CSV file, one-hot encoding non-numerical columns, and optionally writing the prepared data to a new CSV file.
-
Utility: Utility class for computing entropy, partitioning classes, and calculating information gain. -
DecisionTree: Represents a decision tree for classification tasks. -
DecisionTreeWithInfoGain: ExtendsDecisionTreeto use information gain for splitting.
-
Utility: Utility class for computing variance, partitioning classes, and calculating information gain. -
DecisionTreeRegressor: Represents a decision tree for regression tasks.
-
RandomForest: Implements a custom random forest classifier with bootstrapping and voting mechanisms. -
RandomForestWithInfoGain: ExtendsRandomForestto use information gain for splitting. -
runRandomForest: Contains functions to run the random forest classifier.
Performance on Wisconsin Breast Prognostic dataset by Forest Size
-
RandomForest: Implements a custom random forest regressor with bootstrapping and aggregation mechanisms. -
runRandomForest: Contains functions to run the random forest regressor.
-
gradientBoostedRegressor: Represents a gradient boosted decision tree regressor for regression tasks.-
Attributes:
random_seed: Random seed for the random number generator.num_trees: Number of decision trees in the ensemble.max_depth: Maximum depth of each decision tree.X: List of input data features.y: List of target values.XX: Combined list of input data features and target values.numerical_cols: Set of indices for numeric columns.
-
Methods:
__init__(file_loc, num_trees=5, random_seed=0, max_depth=10): Initializes the GBDT object.reset(): Resets the GBDT object.fit(stats=False): Fits the GBDT model to the training data.predict(): Predicts the target values for the input data.get_stats(y_predicted): Calculates evaluation metrics for the predicted target values.
-
This file contains functions to run the custom random forest classifier and regressor on various datasets:
-
randomForestDiabetes(): Runs the random forest classifier on the Pima Indians Diabetes dataset. -
randomForestBreastCancer(): Runs the random forest classifier on the Wisconsin Breast Prognostic dataset. -
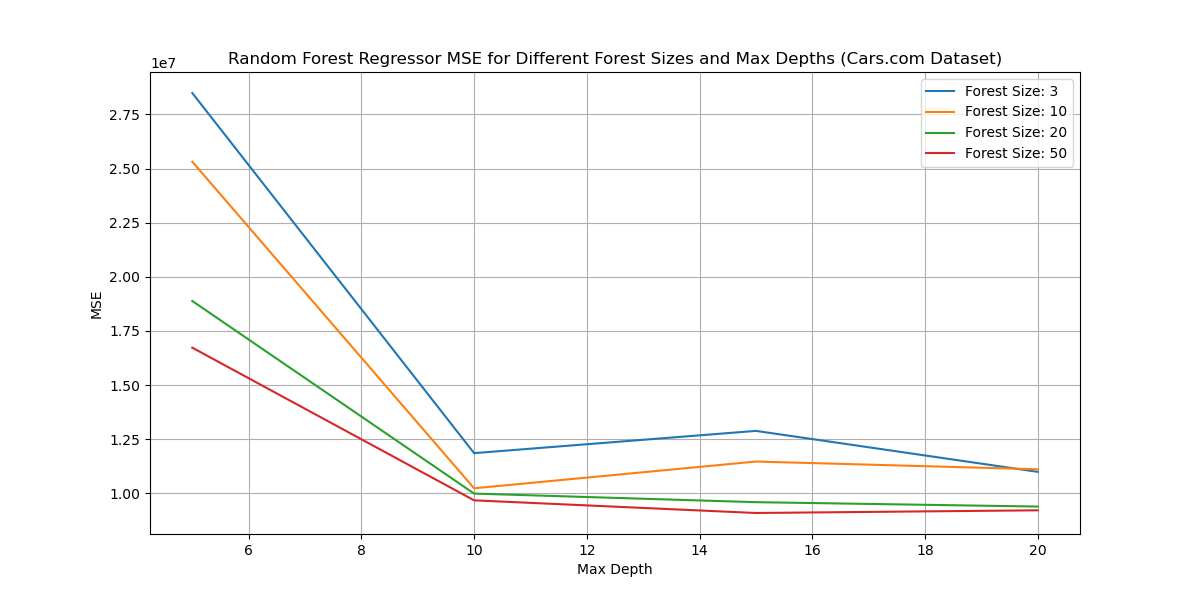
randomForestReg(): Runs the random forest regressor on the cars.com dataset (output_May-06-2024_cleaned.csv).