⭐Please star the repository if you happen to like the project
The .ipynb file contains the solution to the attached Problem Statement.The utils.py file contains the code for the Perceptron Training Algorithm and it is imported in the driver code.
About the Perceptron Training Algorithm (PTA)
The Perceptron Training Algorithm was introduced by Frank Rosenblatt in 1943.
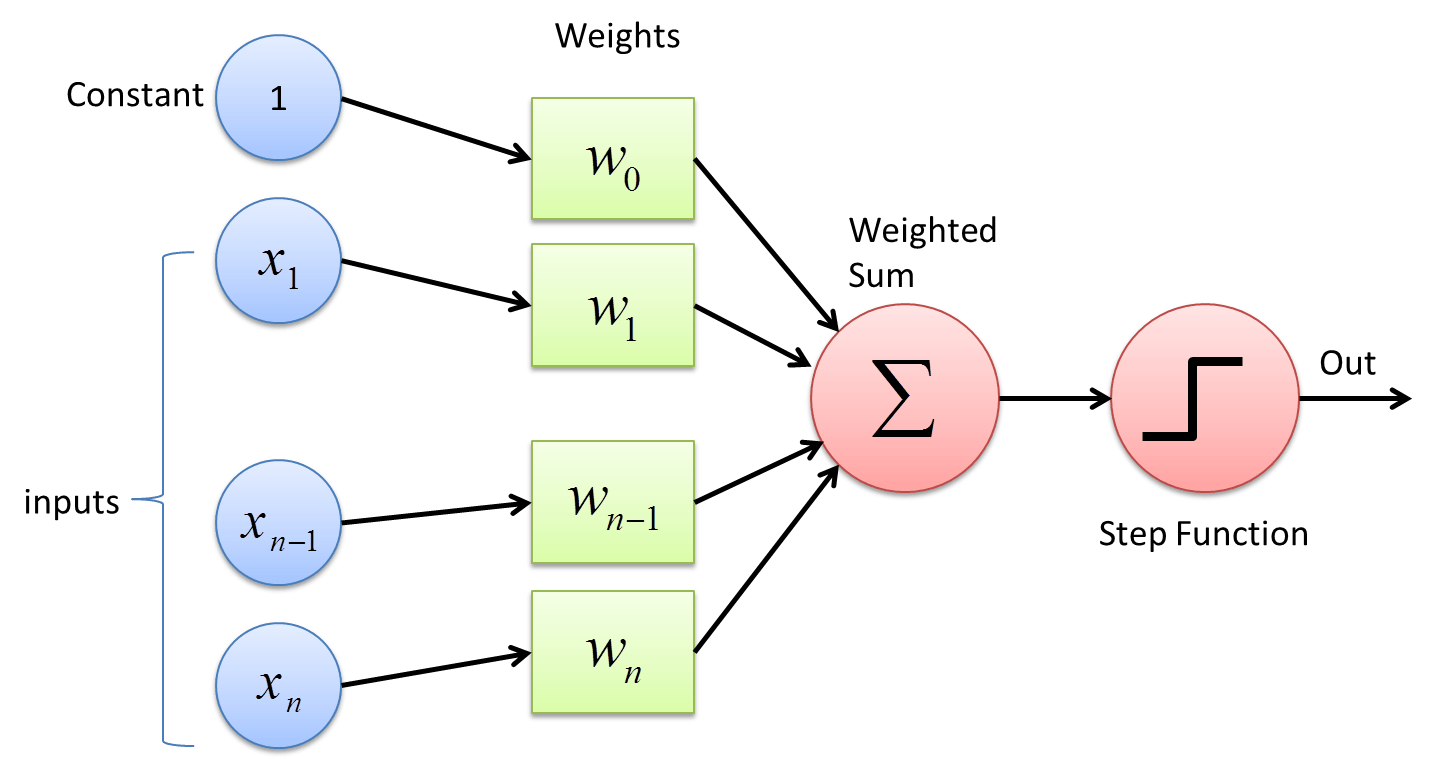
The algorithm takes the data as input namely (x1,x2,...,xn) as the columns or features of the data.It then performs an affine combination of the data with the weights of the perceptron.There are various ways to initialize the weighs,one of them being Random initialization.After performing the affine combination the resulting weighted sum is passed on to a threshold function to obtain the output.
The function can be chosen from a range of activation functions.Here we will discuss about the sign function only.
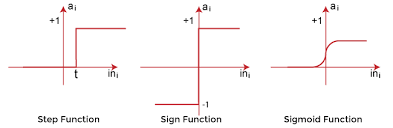
If the weighted sum is above zero then the perceptron is said to activate and returns a 1, whereas if the weighted sum is less than or equal to zero then it returns a -1. The above constitutes a forward pass of the Perceptron Training Algorithm.

In the backward pass if the above error condition is met then weight update as described in the above image takes place.
Both the forward and the backward passes comprise one epoch of the Perceptron Training Algorithm. We keep on iterating over the samples untill all the datapoints have been correctly classified. However note that a single perceptron can only classify linearly separable data.This was shown by Minsky and Papert in 1968.
You can read more about PTA here