Note on the top: the project is unmaintained.
Transformer-based dialog models work better and we recommend using them instead of RNN-based CakeChat. See, for example https://github.com/microsoft/DialoGPT
CakeChat: Emotional Generative Dialog System
CakeChat is a backend for chatbots that are able to express emotions via conversations.
CakeChat is built on Keras and Tensorflow.
The code is flexible and allows to condition model's responses by an arbitrary categorical variable. For example, you can train your own persona-based neural conversational model[1] or create an emotional chatting machine[2].
Main requirements
- python 3.5.2
- tensorflow 1.12.2
- keras 2.2.4
Table of contents
- Network architecture and features
- Quick start
- Setup for training and testing
- Getting the pre-trained model
- Training data
- Training the model
- Running CakeChat server
- Repository overview
- Example use cases
- References
- Credits & Support
- License
Network architecture and features

Model:
- Hierarchical Recurrent Encoder-Decoder (HRED) architecture for handling deep dialog context[3].
- Multilayer RNN with GRU cells. The first layer of the utterance-level encoder is always bidirectional. By default, CuDNNGRU implementation is used for ~25% acceleration during inference.
- Thought vector is fed into decoder on each decoding step.
- Decoder can be conditioned on any categorical label, for example, emotion label or persona id.
Word embedding layer:
- May be initialized using w2v model trained on your corpus.
- Embedding layer may be either fixed or fine-tuned along with other weights of the network.
Decoding
- 4 different response generation algorithms: "sampling", "beamsearch", "sampling-reranking" and "beamsearch-reranking". Reranking of the generated candidates is performed according to the log-likelihood or MMI-criteria[4]. See configuration settings description for details.
Metrics:
- Perplexity
- n-gram distinct metrics adjusted to the samples size[4].
- Lexical similarity between samples of the model and some fixed dataset. Lexical similarity is a cosine distance between TF-IDF vector of responses generated by the model and tokens in the dataset.
- Ranking metrics: mean average precision and mean recall@k.[5]
Quick start
In case you are familiar with Docker here is the easiest way to run a pre-trained CakeChat
model as a server. You may need to run the following commands with sudo.
CPU version:
docker pull lukalabs/cakechat:latest && \
docker run --name cakechat-server -p 127.0.0.1:8080:8080 -it lukalabs/cakechat:latest bash -c "python bin/cakechat_server.py"
GPU version:
docker pull lukalabs/cakechat-gpu:latest && \
nvidia-docker run --name cakechat-gpu-server -p 127.0.0.1:8080:8080 -it lukalabs/cakechat-gpu:latest bash -c "CUDA_VISIBLE_DEVICES=0 python bin/cakechat_server.py"
That's it! Now test your CakeChat server by running the following command on your host machine:
python tools/test_api.py -f localhost -p 8080 -c "hi!" -c "hi, how are you?" -c "good!" -e "joy"
The response dict may look like this:
{'response': "I'm fine!"}
Setup for training and testing
Docker
Docker is the easiest way to set up the environment and install all the dependencies for training and testing.
CPU-only setup
Note: We strongly recommend using GPU-enabled environment for training CakeChat model. Inference can be made both on GPUs and CPUs.
-
Install Docker.
-
Pull a CPU-only docker image from dockerhub:
docker pull lukalabs/cakechat:latest
- Run a docker container in the CPU-only environment:
docker run --name <YOUR_CONTAINER_NAME> -it lukalabs/cakechat:latest
GPU-enabled setup
-
Install nvidia-docker for the GPU support.
-
Pull GPU-enabled docker image from dockerhub:
docker pull lukalabs/cakechat-gpu:latest
- Run a docker container in the GPU-enabled environment:
nvidia-docker run --name <YOUR_CONTAINER_NAME> -it cakechat-gpu:latest
That's it! Now you can train your model and chat with it. See the corresponding section below for further instructions.
Manual setup
If you don't want to deal with docker, you can install all the requirements manually:
pip install -r requirements.txt -r requirements-local.txt
NB:
We recommend installing the requirements inside a virtualenv to prevent messing with your system packages.
Getting the pre-trained model
You can download our pre-trained model weights by running python tools/fetch.py.
The params of the pre-trained model are the following:
- context size 3 (<speaker_1_utterance>, <speaker_2_utterance>, <speaker_1_utterance>)
- each encoded utterance contains up to 30 tokens
- the decoded utterance contains up to 32 tokens
- both encoder and decoder have 2 GRU layers with 768 hidden units each
- first layer of the encoder is bidirectional
Training data
The model was trained on a preprocessed Twitter corpus with ~50 million dialogs (11Gb of text data). To clean up the corpus, we removed
- URLs, retweets and citations;
- mentions and hashtags that are not preceded by regular words or punctuation marks;
- messages that contain more than 30 tokens.
We used our emotions classifier to label each utterance with one of the following 5 emotions: "neutral", "joy", "anger", "sadness", "fear", and used these labels during training.
To mark-up your own corpus with emotions you can use, for example, DeepMoji tool.
Unfortunately, due to Twitter's privacy policy, we are not allowed to provide our dataset. You can train a dialog model on any text conversational dataset available to you, a great overview of existing conversational datasets can be found here: https://breakend.github.io/DialogDatasets/
The training data should be a txt file, where each line is a valid json object, representing a list of dialog utterances. Refer to our dummy train dataset to see the necessary file structure. Replace this dummy corpus with your data before training.
Training the model
There are two options:
- training from scratch
- fine-tuning the provided trained model
The first approach is less restrictive: you can use any training data you want and set any config params of the model. However, you should be aware that you'll need enough train data (~50Mb at least), one or more GPUs and enough patience (days) to get good model's responses.
The second approach is limited by the choice of config params of the pre-trained model – see cakechat/config.py for
the complete list. If the default params are suitable for your task, fine-tuning should be a good option.
Fine-tuning the pre-trained model on your data
-
Fetch the pre-trained model from Amazon S3 by running
python tools/fetch.py. -
Put your training text corpus to
data/corpora_processed/train_processed_dialogs.txt. Make sure that your dataset is large enough, otherwise your model risks to overfit the data and the results will be poor. -
Run
python tools/train.py.- The script will look for the pre-trained model weights in
results/nn_models, the full path is inferred from the set of config params. - If you want to initialize the model weights from a custom file, you can specify the path to the file via
-iargument, for example,python tools/train.py -i results/nn_models/my_saved_weights/model.current. - Don't forget to set
CUDA_VISIBLE_DEVICES=<GPU_ID>environment variable (with <GPU_ID> as in output of nvidia-smi command) if you want to use GPU. For example,CUDA_VISIBLE_DEVICES=0 python tools/train.pywill run the train process on the 0-th GPU. - Use parameter
-sto train the model on a subset of the first N samples of your training data to speed up preprocessing for debugging. For example, runpython tools/train.py -s 1000to train on the first 1000 samples.
- The script will look for the pre-trained model weights in
Weights of the trained model are saved to results/nn_models/.
Training the model from scratch
-
Put your training text corpus to
data/corpora_processed/train_processed_dialogs.txt. -
Set up training parameters in
cakechat/config.py. See configuration settings description for more details. -
Consider running
PYTHONHASHSEED=42 python tools/prepare_index_files.pyto build the index files with tokens and conditions from the training corpus. Make sure to setPYTHONHASHSEEDenvironment variable, otherwise you may get different index files for different launches of the script. Warning: this script overwrites the original tokens index filesdata/tokens_index/t_idx_processed_dialogs.jsonanddata/conditions_index/c_idx_processed_dialogs.json. You should only run this script in case your corpus is large enough to contain all the words that you want your model to understand. Otherwise, consider fine-tuning the pre-trained model as described above. If you messed up with index files and want to get the default versions, delete your copies and runpython tools/fetch.pyanew. -
Consider running
python tools/train_w2v.pyto build w2v embedding from the training corpus. Warning: this script overwrites the original w2v weights that are stored indata/w2v_models. You should only run this script in case your corpus is large enough to contain all the words that you want your model to understand. Otherwise, consider fine-tuning the pre-trained model as described above. If you messed up with w2v files and want to get the default version, delete your file copy and runpython tools/fetch.pyanew. -
Run
python tools/train.py.- Don't forget to set
CUDA_VISIBLE_DEVICES=<GPU_ID>environment variable (with <GPU_ID> as in output of nvidia-smi command) if you want to use GPU. For exampleCUDA_VISIBLE_DEVICES=0 python tools/train.pywill run the train process on the 0-th GPU. - Use parameter
-sto train the model on a subset of the first N samples of your training data to speed up preprocessing for debugging. For example, runpython tools/train.py -s 1000to train on the first 1000 samples.
- Don't forget to set
-
You can also set
IS_DEV=1to enable the "development mode". It uses a reduced number of model parameters (decreased hidden layer dimensions, input and output sizes of token sequences, etc.) and performs verbose logging. Refer to the bottom lines ofcakechat/config.pyfor the complete list of dev params.
Weights of the trained model are saved to results/nn_models/.
Distributed train
GPU-enabled docker container supports distributed train on multiple GPUs using horovod.
For example, run python tools/distributed_train.py -g 0 1 to start training on 0 and 1 GPUs.
Validation metrics calculation
During training the following datasets are used for validations metrics calculation:
data/corpora_processed/val_processed_dialogs.txt(dummy example, replace with your data) – for the context-sensitive datasetdata/quality/context_free_validation_set.txt– for the context-free validation datasetdata/quality/context_free_questions.txt– is used for generating responses for logging and computing distinct-metricsdata/quality/context_free_test_set.txt– is used for computing metrics of the trained model, e.g. ranking metrics
The metrics are stored to cakechat/results/tensorboard and can be visualized using
Tensorboard.
If you run a docker container from the provided CPU or GPU-enabled docker image, tensorboard server should start
automatically and serve on http://localhost:6006. Open this link in your browser to see the training graphs.
If you installed the requirements manually, start tensorboard server first by running the following command from your cakechat root directory:
mkdir -p results/tensorboard && tensorboard --logdir=results/tensorboard 2>results/tensorboard/err.log &
After that proceed to http://localhost:6006.
Testing the trained model
You can run the following tools to evaluate your trained model on test data(dummy example, replace with your data):
tools/quality/ranking_quality.py– computes ranking metrics of a dialog modeltools/quality/prediction_distinctness.py– computes distinct-metrics of a dialog modeltools/quality/condition_quality.py– computes metrics on different subsets of data according to the condition valuetools/generate_predictions.py– evaluates the model. Generates predictions of a dialog model on the set of given dialog contexts and then computes metrics. Note that you should have a reverse-model in thedata/nn_modelsdirectory if you want to use "*-reranking" prediction modestools/generate_predictions_for_condition.py– generates predictions for a given condition value
Running CakeChat server
Local HTTP-server
Run a server that processes HTTP-requests with given input messages and returns response messages from the model:
python bin/cakechat_server.py
Specify CUDA_VISIBLE_DEVICES=<GPU_ID> environment variable to run the server on a certain GPU.
Don't forget to run python tools/fetch.py prior to starting the server if you want to use our pre-trained model.
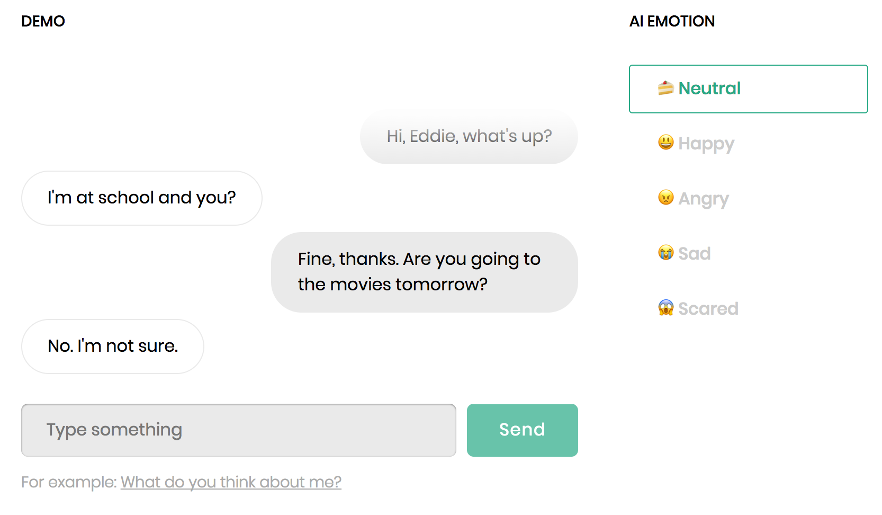
To make sure everything works fine, test the model on the following conversation
– Hi, Eddie, what's up?
– Not much, what about you?
– Fine, thanks. Are you going to the movies tomorrow?
by running the command:
python tools/test_api.py -f 127.0.0.1 -p 8080 \
-c "Hi, Eddie, what's up?" \
-c "Not much, what about you?" \
-c "Fine, thanks. Are you going to the movies tomorrow?"
You should get a meaningful answer, for example:
{'response': "Of course!"}
HTTP-server API description
/cakechat_api/v1/actions/get_response
JSON parameters are:
| Parameter | Type | Description |
|---|---|---|
| context | list of strings | List of previous messages from the dialogue history (max. 3 is used) |
| emotion | string, one of enum | One of {'neutral', 'anger', 'joy', 'fear', 'sadness'}. An emotion to condition the response on. Optional param, if not specified, 'neutral' is used |
Request
POST /cakechat_api/v1/actions/get_response
data: {
'context': ['Hello', 'Hi!', 'How are you?'],
'emotion': 'joy'
}
Response OK
200 OK
{
'response': 'I\'m fine!'
}
Gunicorn HTTP-server
We recommend using Gunicorn for serving the API of your model at production scale.
-
Install gunicorn:
pip install gunicorn -
Run a server that processes HTTP-queries with input messages and returns response messages of the model:
cd bin && gunicorn cakechat_server:app -w 1 -b 127.0.0.1:8080 --timeout 2000
Telegram bot
You can run your CakeChat model as a Telegram bot:
- Create a telegram bot to get bot's token.
- Run
python tools/telegram_bot.py --token <YOUR_BOT_TOKEN>and chat with it on Telegram.
Repository overview
cakechat/dialog_model/– contains computational graph, training procedure and other model utilitiescakechat/dialog_model/inference/– algorithms for response generationcakechat/dialog_model/quality/– code for metrics calculation and loggingcakechat/utils/– utilities for text processing, w2v training, etc.cakechat/api/– functions to run http server: API configuration, error handlingtools/– scripts for training, testing and evaluating your model
Important tools
bin/cakechat_server.py– Runs an HTTP-server that returns response messages of the model given dialog contexts and an emotion. See run section for details.tools/train.py– Trains the model on your data. You can use the--reverseoption to train a reverse-model used in "*-reranking" response generation algorithms for more accurate predictions.tools/prepare_index_files.py– Prepares index for the most commonly used tokens and conditions. Use this script before training the model from scratch on your own data.tools/quality/ranking_quality.py– Computes ranking metrics of a dialog model.tools/quality/prediction_distinctness.py– Computes distinct-metrics of a dialog model.tools/quality/condition_quality.py– Computes metrics on different subsets of data according to the condition value.tools/generate_predictions.py– Evaluates the model. Generates predictions of a dialog model on the set of given dialog contexts and then computes metrics. Note that you should have a reverse-model in theresults/nn_modelsdirectory if you want to use "*-reranking" prediction modes.tools/generate_predictions_for_condition.py– Generates predictions for a given condition value.tools/test_api.py– Example code to send requests to a running HTTP-server.tools/fetch.py– Downloads the pre-trained model and index files associated with it.tools/telegram_bot.py– Runs Telegram bot on top of trained model.
Important configuration settings
All the configuration parameters for the network architecture, training, predicting and logging steps are defined in
cakechat/config.py. Some inference parameters used in an HTTP-server are defined in
cakechat/api/config.py.
-
Network architecture and size
HIDDEN_LAYER_DIMENSIONis the main parameter that defines the number of hidden units in recurrent layers.WORD_EMBEDDING_DIMENSIONandCONDITION_EMBEDDING_DIMENSIONdefine the number of hidden units that each token/condition are mapped into.- Number of units of the output layer of the decoder is defined by the number of tokens in the dictionary in the
tokens_indexdirectory.
-
Decoding algorithm:
PREDICTION_MODE_FOR_TESTSdefines how the responses of the model are generated. The options are the following:- sampling – response is sampled from output distribution token-by-token.
For every token the temperature transform is performed prior to sampling.
You can control the temperature value by tuning
DEFAULT_TEMPERATUREparameter. - sampling-reranking – multiple candidate-responses are generated using sampling procedure described above.
After that the candidates are ranked according to their MMI-score[4]
You can tune this mode by picking
SAMPLES_NUM_FOR_RERANKINGandMMI_REVERSE_MODEL_SCORE_WEIGHTparameters. - beamsearch – candidates are sampled using beam search algorithm. The candidates are ordered according to their log-likelihood score computed by the beam search procedure.
- beamsearch-reranking – same as above, but the candidates are re-ordered after the generation in the same way as in sampling-reranking mode.
- sampling – response is sampled from output distribution token-by-token.
For every token the temperature transform is performed prior to sampling.
You can control the temperature value by tuning
Note that there are other parameters that affect the response generation process. See
REPETITION_PENALIZE_COEFFICIENT,NON_PENALIZABLE_TOKENS,MAX_PREDICTIONS_LENGTH.
Example use cases
By providing additional condition labels within dataset entries, you can build the following models:
- A Persona-Based Neural Conversation Model — a model that allows to condition responses on a persona ID to make them lexically similar to the given persona's linguistic style.
- Emotional Chatting Machine-like model — a model that allows conditioning responses on different emotions to provide emotional styles (anger, sadness, joy, etc).
- Topic Aware Neural Response Generation-like model — a model that allows to condition responses on a certain topic to keep the topic-aware conversation.
To make use of these extra conditions, please refer to the section Training the model. Just set the "condition" field in the training set to one of the following: persona ID, emotion or topic label, update the index files and start the training.
References
- [1] A Persona-Based Neural Conversation Model
- [2] Emotional Chatting Machine: Emotional Conversation Generation with Internal and External Memory
- [3] A Hierarchical Recurrent Encoder-Decoder For Generative Context-Aware Query Suggestion
- [4] A Diversity-Promoting Objective Function for Neural Conversation Models
- [5] Quantitative Evaluation of User Simulation Techniques for Spoken Dialogue Systems
- [6] Topic Aware Neural Response Generation
Credits & Support
CakeChat is developed and maintained by the Replika team:
Nicolas Ivanov, Michael Khalman, Nikita Smetanin, Artem Rodichev and Denis Fedorenko.
Demo by Oleg Akbarov, Alexander Kuznetsov and Vladimir Chernosvitov.
All issues and feature requests can be tracked here – GitHub Issues.
License
© 2019 Luka, Inc. Licensed under the Apache License, Version 2.0. See LICENSE file for more details.