Author: ShaofengZou
Kaggle ID: 1969608
Contact: zousf19@mails.tsinghua.edu.cn

Keras Inplement Using CNN
Architecture:
Input -> [ Conv2D -> BN -> Relu -> Conv2D -> BN -> Relu -> Maxpooling2D -> Dropout ] * 2 -> Flatten -> Dense -> Dropout -> Output
Accuracy on validation set: 99.43%
Accuracy on test set: 99.614%
最佳准确率(Kaggle平台给出): 99.614%
提交总次数: 1
Quick Start:
if you work with windows or ubuntu:
python main.py
if you work on ubuntu with 8 GPUS, you can do multiply experiments one time:
sh do_exp.sh
you select the specific gpu with gpu_id
If you like this project, welcome to fork and star ^_^
- 读取数据
- 数据归一化
- CNN对0-1的收敛更快
- 数据reshape
- 对标签进行one-hot编码
- 拆分训练集和测试集
-
设计CNN模型

-
选择优化器和设计回调函数
- 使用RMSprop作为优化器
- 设计回调函数
- ReduceLROnPlateau
- ModelCheckpoint
- EarlyStopping
-
数据集增强
- 旋转
- 缩放
- 横向、纵向平移

-
训练时损失和准确率变化曲线
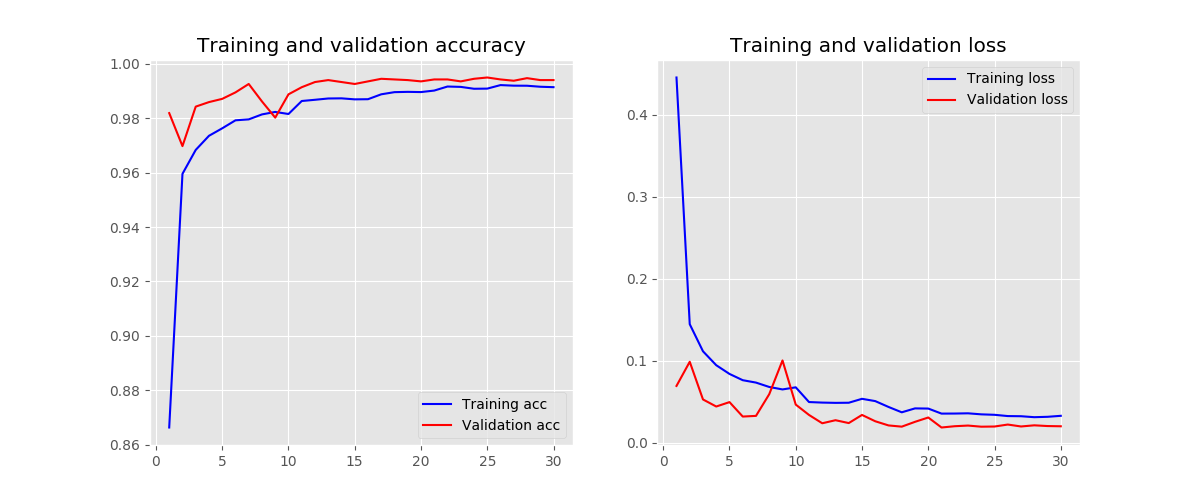
-
在验证集上的准确率:0.9943
在验证集上的混淆矩阵:
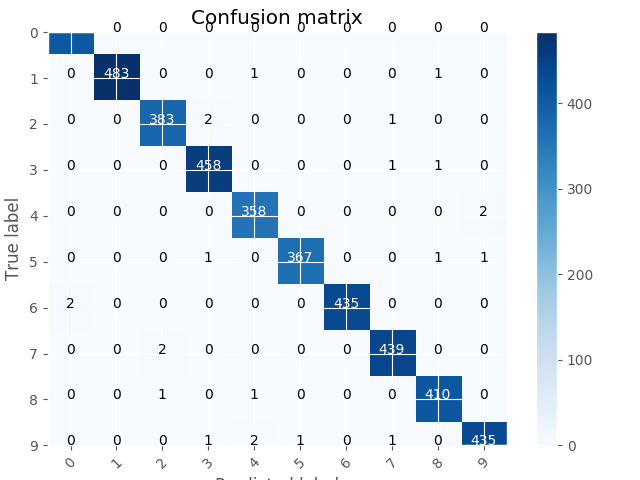


- 在Kaggle上的提交结果:

- 在Kaggle上的排名:

设计对比实验,观察对比卷积核大小、数量、卷积层数、参数初始化、是否归一化等参数对模型在验证集上的准确率进行验证。
对比实验中的baseline的基本结构为:
Input -> [ Conv2D -> Relu -> Conv2D -> Relu -> Maxpooling2D -> Dropout ] * 2 -> Flatten -> Dense -> Dropout -> Output
这里:
- 记block number为[Conv2D -> Relu -> Conv2D -> Relu -> Maxpooling2D -> Dropout]结构的数量
- 记filter number为Conv2D中的卷积核数量,即输出feature map的数量
- 记kernel size为Conv2D中卷积核的大小
- 记initializers为Conv2D中权重初始化的方法
- random_normal为正态分布初始化方法,均值为0,方差为0.05
- random_uniform为均匀分布初始化方法,均匀分布下边界和均匀分布上边界分别为-0.05和0.05
- orthogonal为随机正交矩阵初始化方法,正交矩阵的乘性系数为1
| Experiment id | block number | filter number | kernel size | initializers | batch normalization | accuracy of validation dataset |
|---|---|---|---|---|---|---|
| baseline | 2 | 32 | 5 | random_normal | no | 99.38% |
| block number - 1 | 1 | 32 | 5 | random_normal | no | 98.93% |
| block number - 3 | 3 | 32 | 5 | random_normal | no | 99.45% |
| filter number - 16 | 2 | 16 | 5 | random_normal | no | 99.40% |
| filter number - 64 | 2 | 64 | 5 | random_normal | no | 98.36% |
| kernel size - 3 | 2 | 32 | 3 | random_normal | no | 99.36% |
| kernel size - 7 | 2 | 32 | 7 | random_normal | no | 99.36% |
| initializers - random uniform | 2 | 32 | 5 | random_uniform | no | 99.24% |
| initializers - orthogonal | 2 | 32 | 5 | orthogonal | no | 99.31% |
| batch normalization - yes | 2 | 32 | 5 | random_normal | yes | 99.45% |
-
baseline
-
block number - 1

-
block number - 3
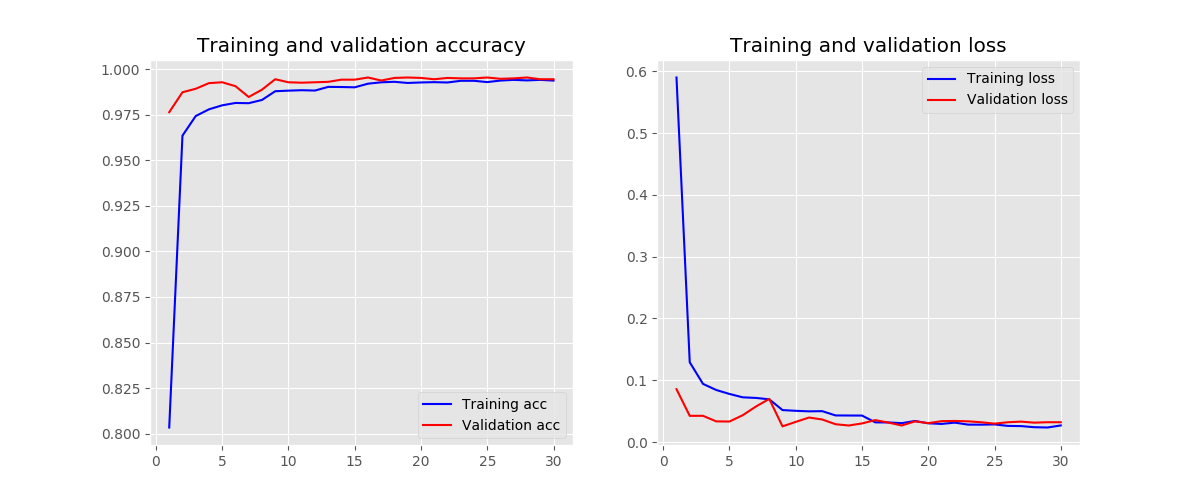
-
filter number - 16
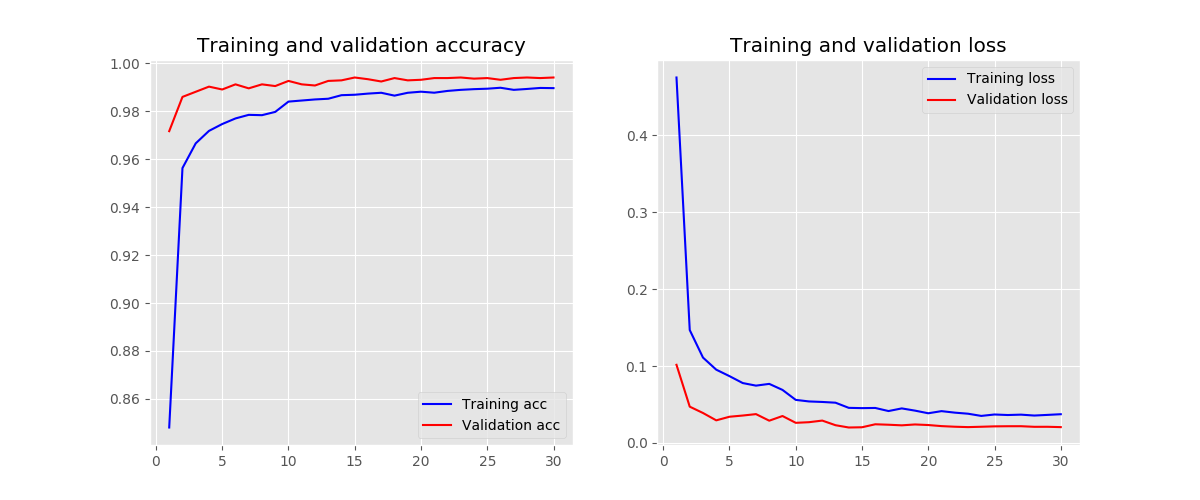
-
filter number - 64
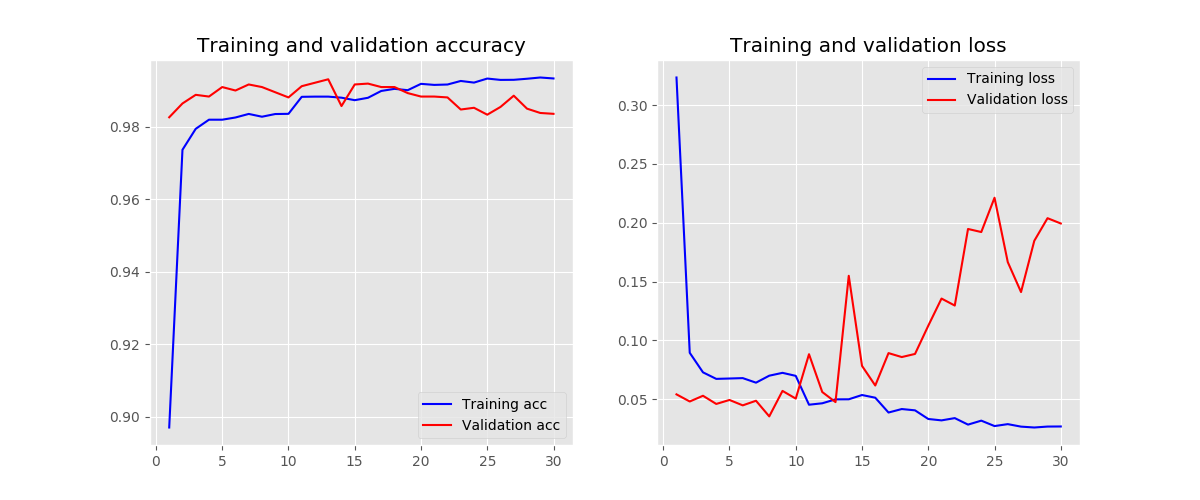
-
kernel size - 3
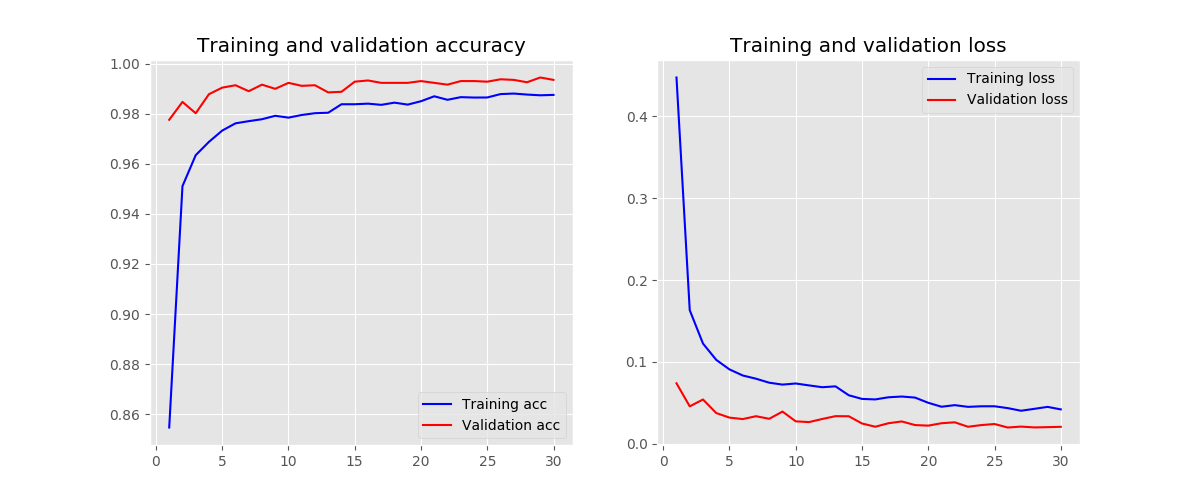
-
kernel size - 7
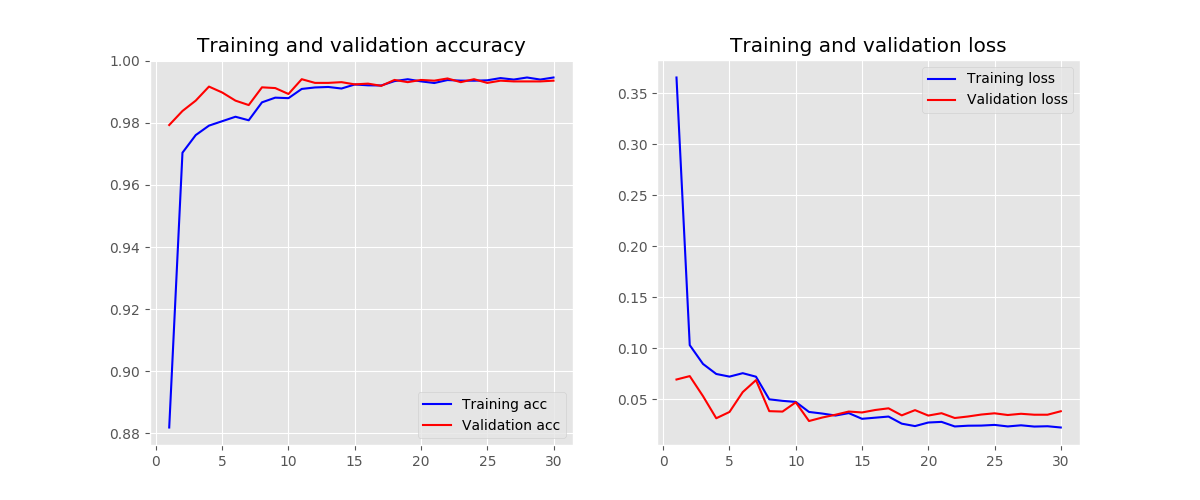
-
initializers - random uniform
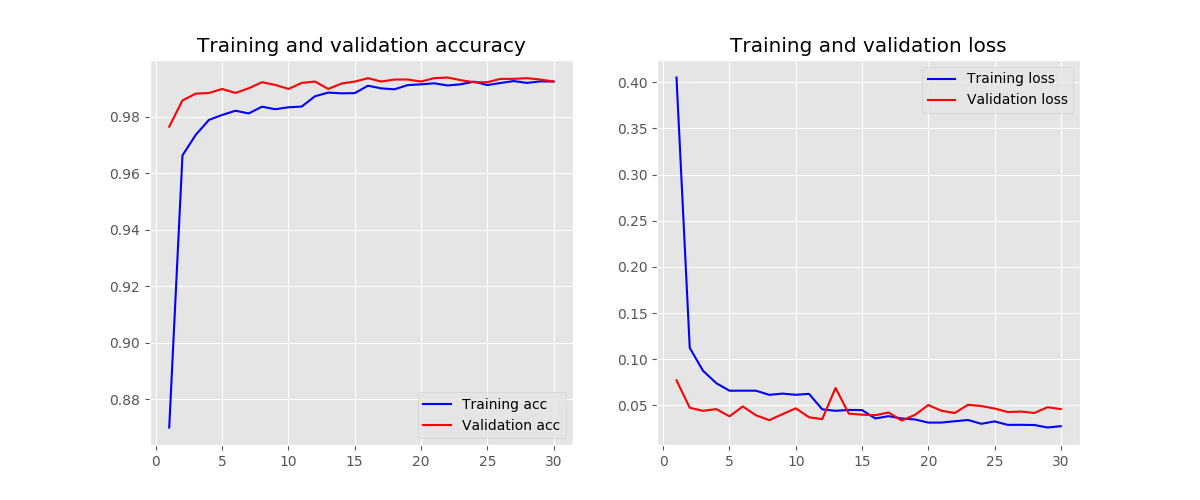
-
initializers - orthogonal
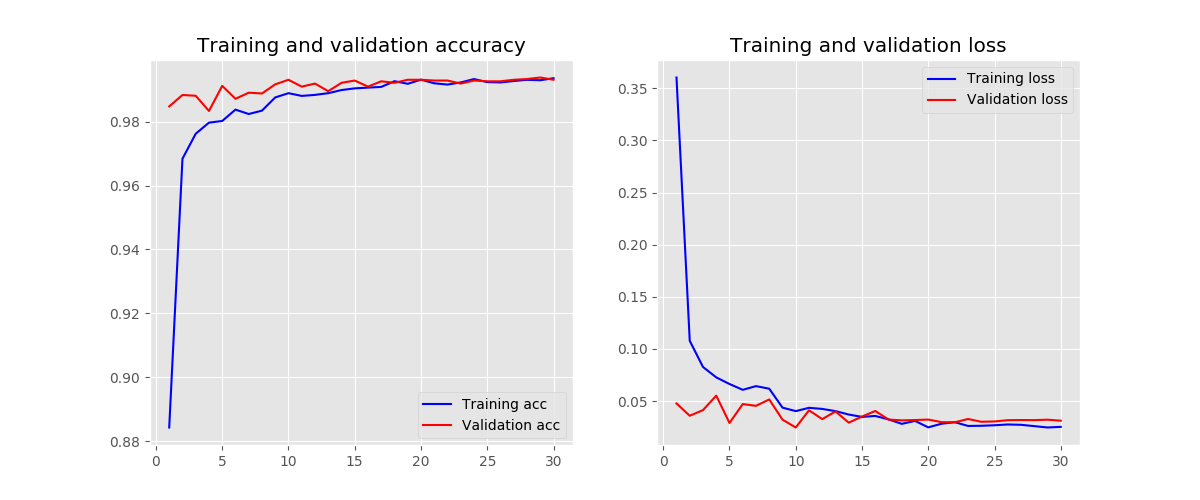
-
batch normalization - yes
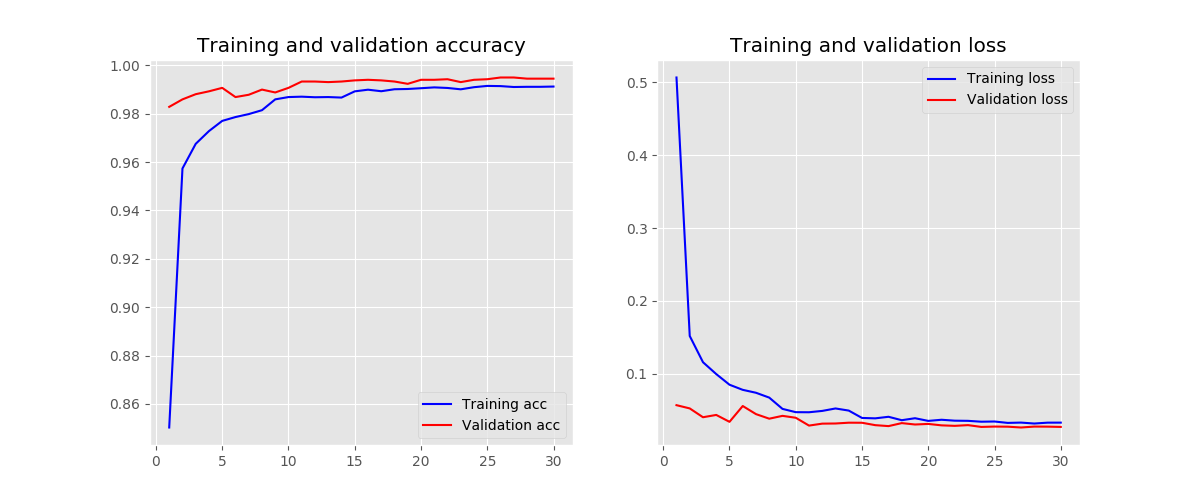








-
卷积层数太少会降低模型精度,层数太多的话模型复杂度会增加
-
卷积核数量过大会难以收敛,训练中波动会较大
-
添加批量归一化可以使模型收敛更快,因为批量归一化可以解决梯度弥散的问题
-
实验训练什么时候停止是最合适的?简要陈述你的实现方式,并试分析固定迭代次数与通过验证集调整等方法的优缺点。
Answer:
-
在验证集的损失不再上升时,可以停止训练。通过训练过程中设置EarlyStopping的回调函数,当多次训练后的验证集损失不再降低时,就停止训练。同时,设置ReduceLROnPlateau的回调函数,当多次训练后的验证集准确度不再上升时,降低学习率。
-
固定迭代次数的缺点就是无法确定一个合适的迭代次数,迭代次数设置的过大则会浪费训练时间,过小则无法获得最优模型。
-
-
实验参数的初始化是怎么做的?不同的方法适合哪些地方?
Answer:
- 使用零均值初始化,高斯分布初始化,正交初始化等方法初始化等方法。
- 不可以采用零初始化,因为这样在每次迭代过程中所有权重的变化都会是一样的。
- 不可以采用过大或过小的初值,因为卷积之后的值会过大过小,在激活函数附近的梯度就会几乎为0,产生梯度消失的问题。
-
过拟合是深度学习常见的问题,有什么方法可以方式训练过程陷入过拟合?
Answer:
可以尝试使用:
- Batch-Normalization
- Dropout
- Early-Stopping
-
试分析CNN(卷积神经网络)相对于全连接神经网络的优点
-
全连接神经网络的参数过多,所以计算速度慢,且容易引起过拟合。
-
CNN相对于全连接神经网络的特点是局部链接、权值共享、引入池化可降低特征图大小,所以具有的优点为:
- 参数少,只与卷积核的大小和数量有关
- 具有特征抽取能力
- 特征的平移不变性
-
- Batch-Normalization可以提升训练时的稳定性,解决梯度弥散问题
- 为了防止过拟合,可以进行适当的数据增强
- 防止过拟合,还可以设计回调函数,根据验证集的测试精度来降低学习率或者停止迭代,并根据验证集的准确率来保存最佳的模型