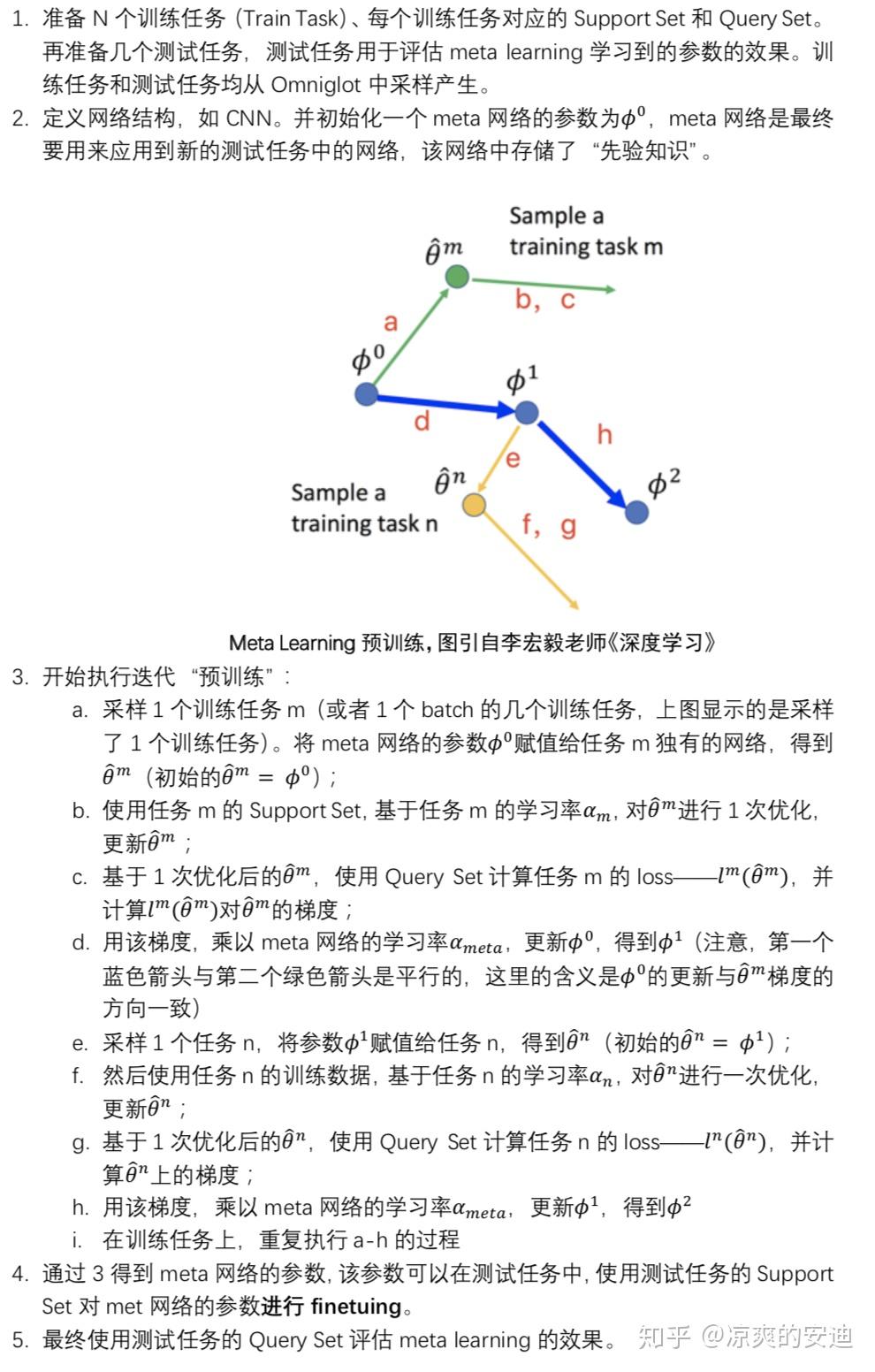
MAML的执行过程与model pretraining & transfer learning的区别是什么?
注意这两个loss函数的区别:
- meta learning的L来源于训练任务上网络的参数更新过一次后(该网络更新过一次以后,网络的参数与meta网络的参数已经有一些区别),然后使用Query Set计算的loss;
- model pretraining的L来源于同一个model的参数(只有一个),使用训练数据计算的loss和梯度对model进行更新;如果有多个训练任务,我们可以将这个参数在很多任务上进行预训练,训练的所有梯度都会直接更新到model的参数上。
从sense上直观理解:
- model pretraining最小化当前的model(只有一个)在所有任务上的loss,所以model pretraining希望找到一个在所有任务(实际情况往往是大多数任务)上都表现较好的一个初始化参数,这个参数要在多数任务上当前表现较好。
- meta learning最小化每一个子任务训练一步之后,第二次计算出的loss,用第二步的gradient更新meta网络,这代表了什么呢?子任务从【状态0】,到【状态1】,我们希望状态1的loss小,说明meta learning更care的是初始化参数未来的潜力。
一个关注当下,一个关注潜力。
- model pretraining找到的参数
$\theta$ ,在两个任务上当前的表现比较好(当下好,但训练之后不保证好); - 而MAML的参数
$\theta$ 在两个子任务当前的表现可能都不是很好,但是如果在两个子任务上继续训练下去,可能会达到各自任务的局部最优(潜力好)。