Huffman and LZW algorithms written in Python 3.
Usage: compress.py [options] file
Options:
-h, --help Show this help message and exit.
-v, --verbose Set verbose mode to understand what's underneath.
-a ALGO, --algo=ALGO Set the algorithm you want to use (Huffman or LZW)
default is LZW.
-o OUTPUT, --output=OUTPUT
Set the output file name, default is the same as input
+ tor extension.
-d, --decompress Decompress the file.
--benchmark Start benchmarking compession algorithms.
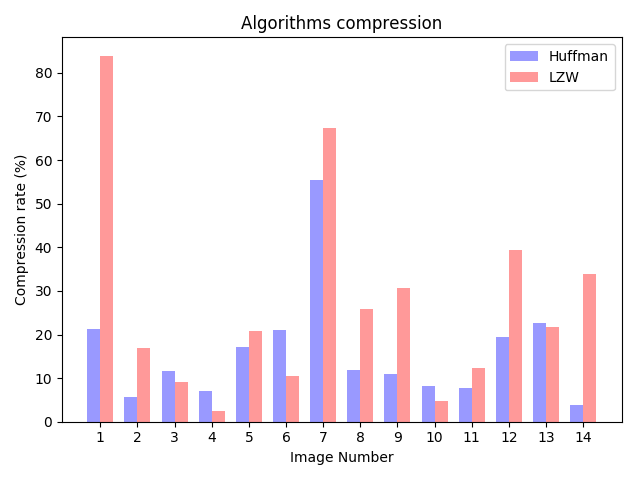
This benchmark has been performed on images only. The results might not be relevant with other kind of files.

- Compress chunks of data instead of reading the whole file. (Memory issue with big files)
- Multiple files compression and directories
- Multithreading. Though the algorithms might not be multithreadable, it should be possible to multi thread chunks compression.
- Bigger and better datasets in order to have more relevant benchmarks
- Benchmark the memory used by the algorithms