
This is a repository where I attempt to reproduce the results of Asynchronous Methods for Deep Reinforcement Learning. Currently I have only replicated A3C FF/LSTM for Atari.
Any feedback is welcome :)
- A3C FF/LSTM (only for discrete action space)
- Atari environment
- ViZDoom environment (experimental)
I trained A3C FF for ALE's Breakout with 36 processes (AWS EC2 c4.8xlarge) for 80 million training steps, which took about 17 hours. The mean and median of scores of test runs along training are plotted below. Ten test runs for every 1 million training steps (counted by the global shared counter). The results seems slightly worse than theirs.
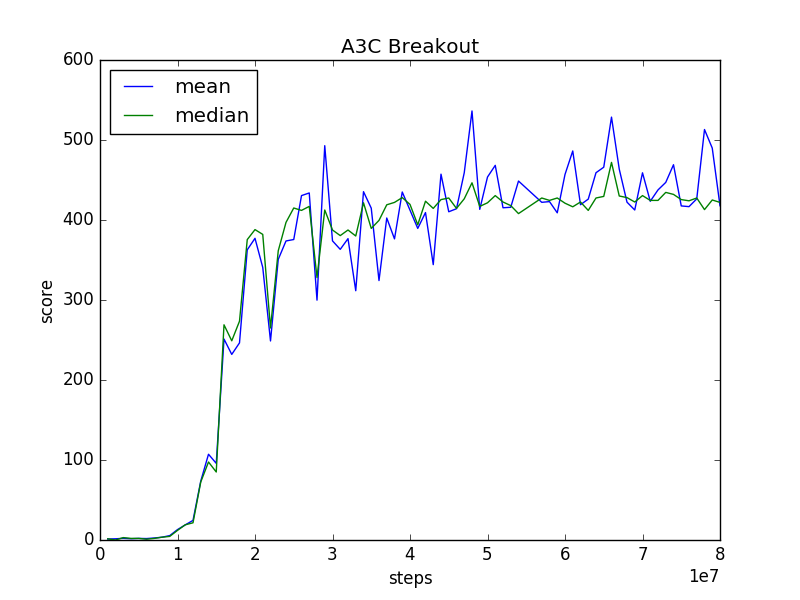
The trained model is uploaded at trained_model/breakout_ff/80000000_finish.h5, so you can make it to play Breakout by the following command:
python demo_a3c_ale.py <path-to-rom> trained_model/breakout_ff/80000000_finish.h5
The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
I also trained A3C LSTM for ALE's Space Invaders in the same manner with A3C FF. Training A3C LSTM took about 24 hours for 80 million training steps.
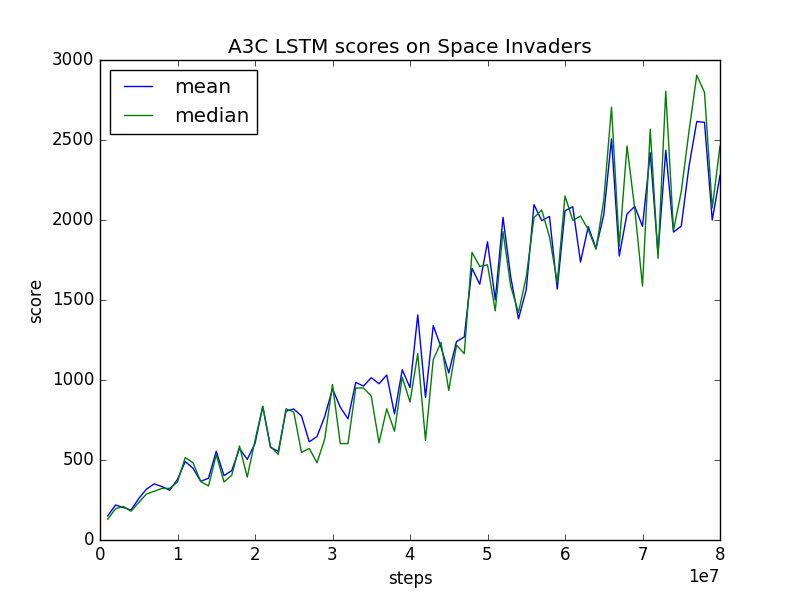
The trained model is uploaded at trained_model/space_invaders_lstm/80000000_finish.h5, so you can make it to play Space Invaders by the following command:
python demo_a3c_ale.py <path-to-rom> trained_model/space_invaders_lstm/80000000_finish.h5 --use-lstm
The animation gif above is the episode I cherry-picked from 10 demo runs using that model.
I received a confirmation about their implementation details and some hyperparameters by e-mail from Dr. Mnih. I summarized them in the wiki: https://github.com/muupan/async-rl/wiki
- Python 3.5.1
- chainer 1.8.1
- cached-property 1.3.0
- h5py 2.5.0
- Arcade-Learning-Environment
python a3c_ale.py <number-of-processes> <path-to-atari-rom> [--use-lstm]
a3c_ale.py will save best-so-far models and test scores into the output directory.
Unfortunately it seems this script has some bug now. Please see the issues #5 and #6. I'm trying to fix it.
python demo_a3c_ale.py <path-to-atari-rom> <trained-model> [--use-lstm]