
📊 Context: The Original dataset encompasses user ratings and free-text tagging from MovieLens, a movie recommendation platform. It comprises 20,002,263 ratings and 465,564 tag applications across 27,278 movies.
😆 Shrinking Dataset Since the dataset is too large to compute resulted will be O(N^2M), we need to perform shrinking by choosing the users who like maximum number of movies.We selects the top 10,000 users and perform Matrix Factorization.
- ref code: https://www.kaggle.com/code/shiblinomani/recommender-system-using-movielens-20m-dataset
- original dataset: https://www.kaggle.com/code/shiblinomani/recommender-system-using-movielens-20m-dataset/input
- Add system variables for Java_Home, Spark, Hadoop
- Add system variables path for Spark, Hadoop
- Add user variables for Java_Home, Spark, Hadoop to use the
Apache Sparkfrom other directory.
- ref video links: https://www.youtube.com/watch?v=0F4fokX5MPQ
- ref video links: https://www.youtube.com/watch?v=QYTPpqPYaw0
😊 Java Download: https://www.java.com/en/download/manual.jsp

- install Java
- Java Environment:
Start Menu Search >> Edit The System Variables >> Environment Variables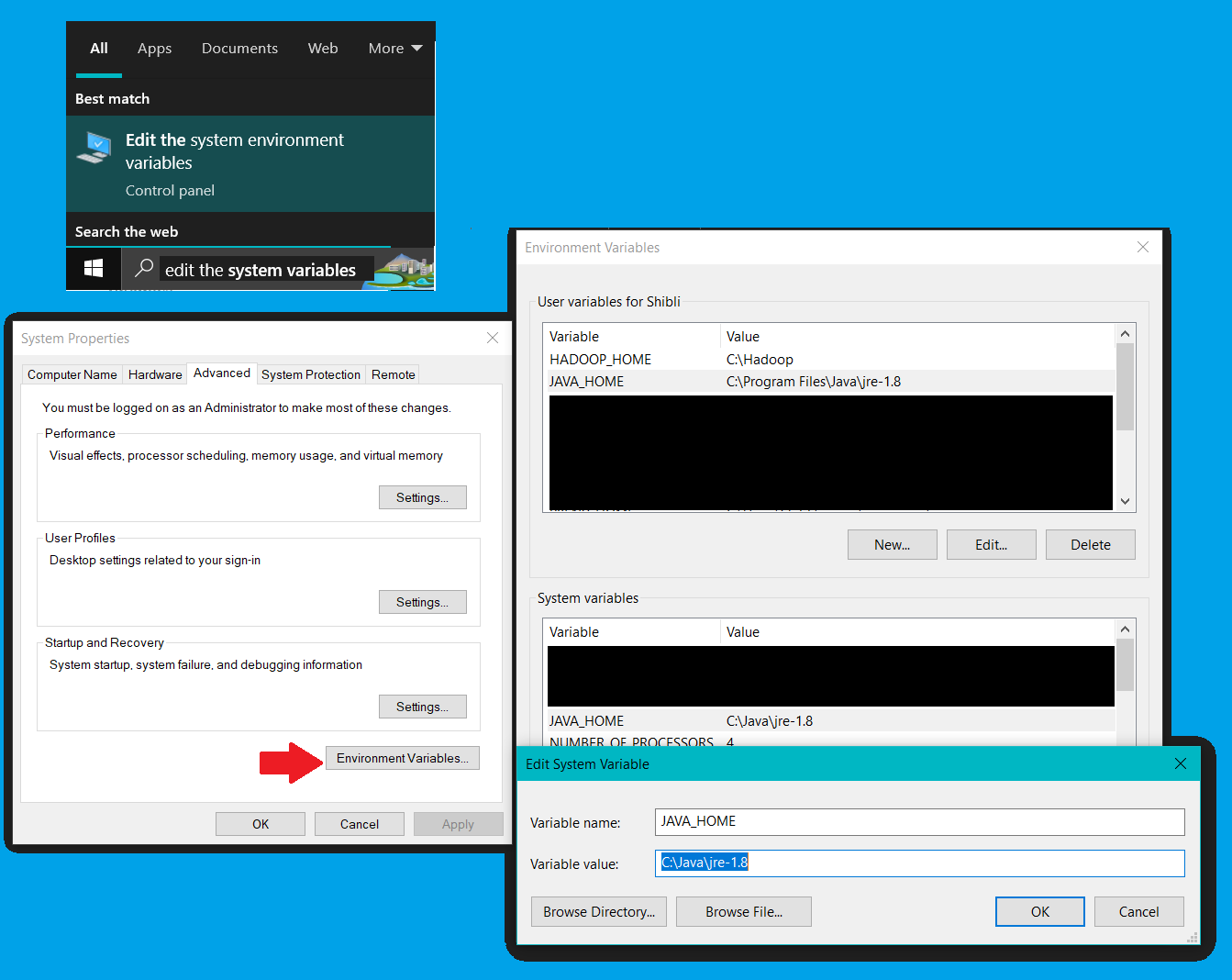

😊 Apache Spark Download: https://spark.apache.org/downloads.html
- Create a folder named
Sparkin C-drive and `unzip' the downloaded version. - Apache Spark Environment:
Start Menu Search >> Edit The System Variables >> Environment Variables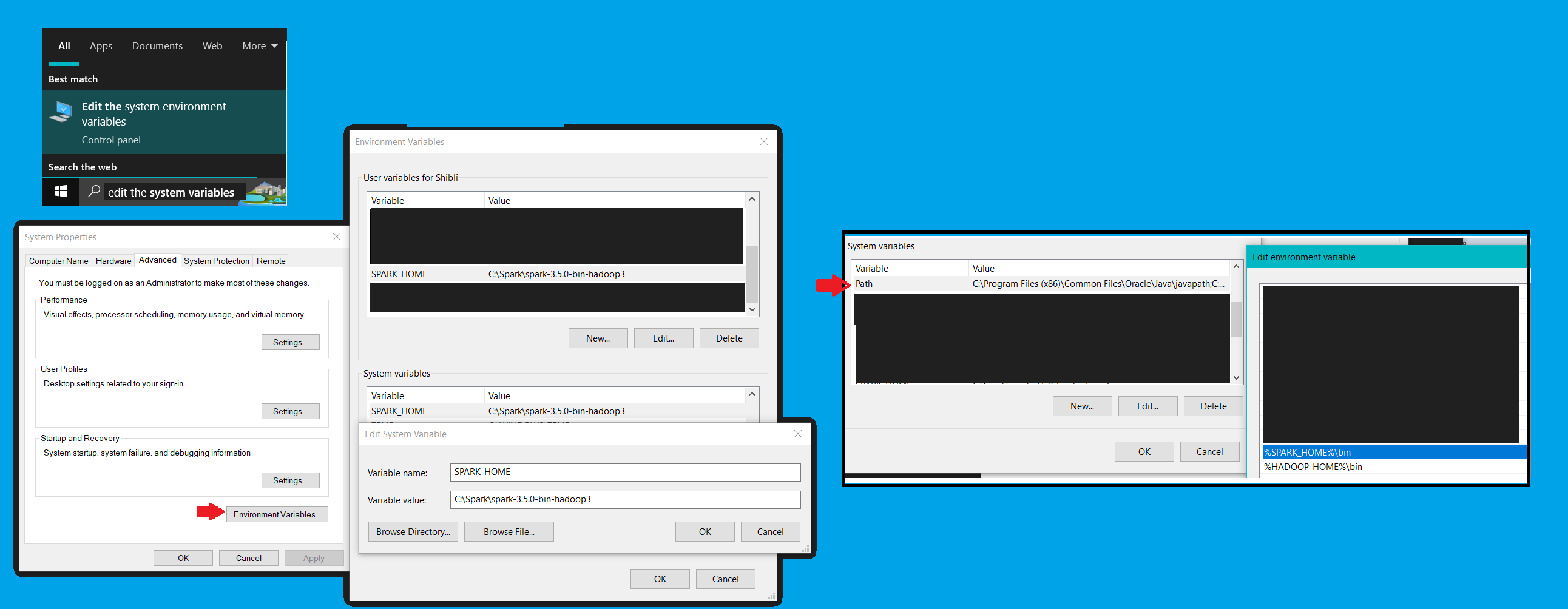

😊 For Hadoop(winutils.exe and hadoop.dll):
- winutils.exe download(as per version of Hadoop while downloading Apache Spark, here Hadoop 3.3): https://github.com/steveloughran/winutils/blob/master/hadoop-3.0.0/bin/winutils.exe
- hadoop.dll(as per version of Hadoop while downloading Apache Spark, here Hadoop 3.3):https://github.com/kontext-tech/winutils/blob/master/hadoop-3.3.0/bin/hadoop.dll
- Create a folder named
Hadoopin C-drive, then subfolderbinand `store' the downloaded file winutils.exe and hadoop.dll under bin folder. - Hadoop Environment:
Start Menu Search >> Edit The System Variables >> Environment Variables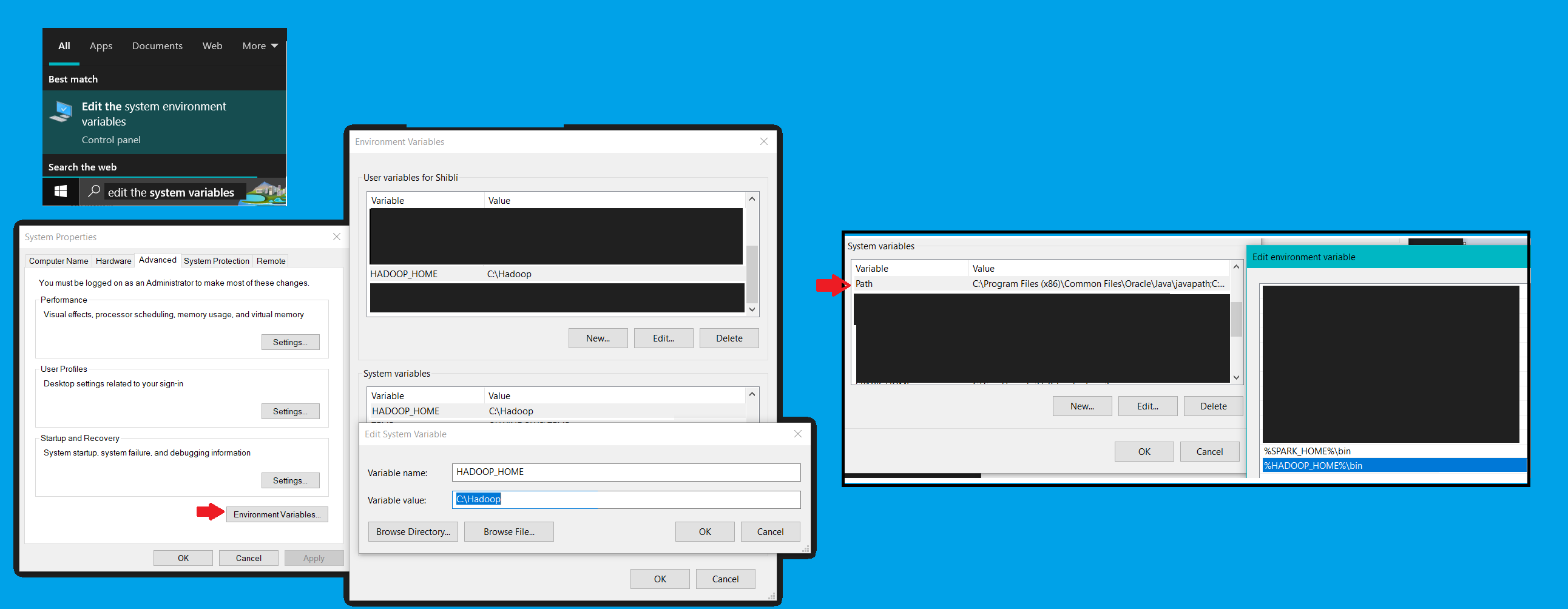

spark-shellsc details: Spark context available as 'sc' (master = local[*], app id = local-1708364284935).
note: bydefault, it starts with scala
spark-submit --versionvideo link: https://www.youtube.com/watch?v=e17s4ul4uTo https://www.youtube.com/watch?v=Irn7a8U-QxA
start >> cmd >> Run as Administrator

😟note: Forget Password Problem:
 Solution Video Link: https://www.youtube.com/watch?v=RCW9PTNS440
Solution Video Link: https://www.youtube.com/watch?v=RCW9PTNS440
-
Go to command prompt as follows:
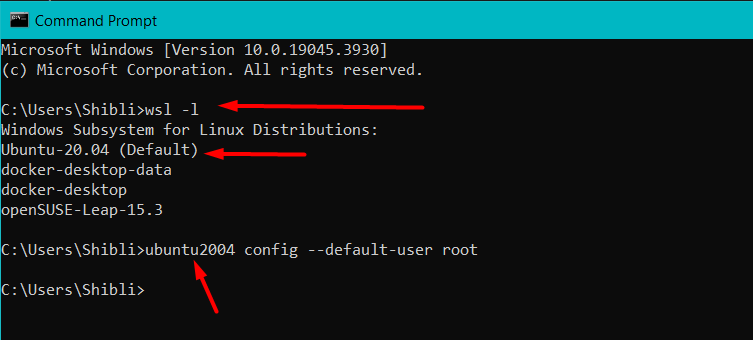
wsl -l
ubuntu2004 config --default-user root
-
Go to Ubuntu Terminal
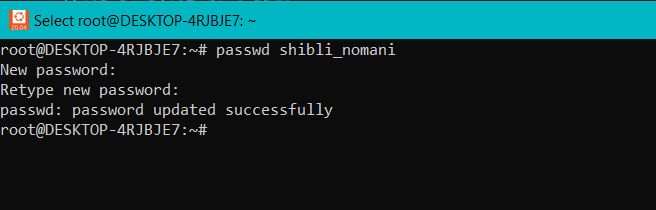
passwd shibli_nomani -
go back to the command prompt and change the default setting (root to shibli_nomani)
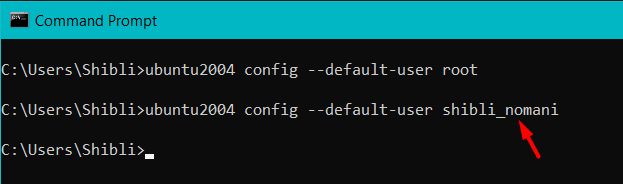
ubuntu2004 config --default-user shibli_nomani



java -version sudo apt update sudo apt install default-jdkscala version
scala -versionsudo apt install scalapip install pyspark

😤Error : py4exception occurs due to version mismatch of Apache Spark and Pyspark

-
option-1: 😤 note: due to old version Apache Spark, you may face unwanted py4JError solution-1: choose proper version. ref video link: https://www.youtube.com/watch?v=s2yjvQPGsyw
-
option-2: 😤 note: due to wrong env path setup in windows(startmenu >> search >> edit system evironment variable >> Environment Variable >>
user variable for user_name&system variable) solution-2: set the path in correct manner. -
option-3: 😤 note: due to version mismatch of Apache Spark & Pyspark. solution-3: https://stackoverflow.com/questions/72873963/py4jexception-constructor-org-apache-spark-sql-sparksessionclass-org-apache-s
-
check spark version in powershell
spark-submit --version
-
edit the requirements.txt file with same version of pyspark as per Spark
pyspark==3.4.2 -
run again the requirements.txt in powershell
list of libaries
- matplotlib
- matplotlib-inline
- numpy
- keras
- tensorflow
- tensorflow-intel
- scikit-learn
- seaborn
- scipy
- pyspark==3.4.2
pip install -r requirements.txtBecareful about the filepath and choose the absolute filepath to avoid Py4JJavaError raises due to filepath issue.
😤 solution:
data = sc.textFile("E:/Data Science/recommeder system/Recommender System/data/smallrating.csv")
😤😤😤😤😤solution:
Check Spark URL for Python in worker has different version 3.10 than that in driver 3.8 and install correct version for driver according to Python worker. here, 3.10 😆😆

- for python version installation:
https://github.com/Shibli-Nomani/MLOps-Project-AirTicketPricePrediction- set pyenv in powershell of vscode before create any venv
pyenv shell 3.10.8Apache Spark is an open-source distributed computing system that provides an interface for programming entire clusters with implicit data parallelism and fault tolerance. It supports a wide range of applications, including batch processing, streaming analytics, machine learning, and graph processing.
PySpark is the Python API for Apache Spark, a fast and general-purpose cluster computing system for Big Data processing. It provides a simple and consistent interface for distributed data processing using Python.
MLlib is Apache Spark's scalable machine learning library, offering a set of high-level APIs for scalable machine learning algorithms. It includes common learning algorithms and utilities, such as classification, regression, clustering, collaborative filtering, dimensionality reduction, and feature engineering, suitable for large-scale data processing tasks.
RDD is a core data structure in PySpark representing an immutable, distributed collection of objects. It enables parallel processing, fault tolerance, and high-level abstractions for distributed data processing.
- Purpose: RDDs facilitate distributed data processing across a cluster of machines, ensuring fault tolerance and providing a high-level abstraction for complex operations.
- Benefits:
- Parallel Processing: Enables parallel computation across multiple nodes, improving performance and scalability.
- Fault Tolerance: Automatic recovery from node failures ensures data integrity and reliability.
- Data Immutability: Immutable nature simplifies parallel processing and ensures data consistency.
- Lazy Evaluation: Lazy evaluation reduces unnecessary computation and optimizes performance.
- Versatility: Supports various operations like map, reduce, filter, and join for diverse data processing tasks.
PySpark, with its RDDs, empowers developers to efficiently process large-scale datasets in distributed environments. 🚀 It offers fault tolerance, scalability, and a versatile set of operations, making it a go-to choice for Big Data processing with Python. 🐍💻
A software tool or algorithm that analyzes user preferences and behavior to make personalized recommendations for items or content. Recommender systems aim to assist users in finding relevant items of interest, such as movies, products, or articles, by leveraging techniques like collaborative filtering, content-based filtering, or hybrid methods. These systems are widely used in various domains, including e-commerce, streaming services, social media, and online platforms, to enhance user experience and engagement.
Recommender system technique based on users' past interactions to predict their future preferences without requiring explicit knowledge about users or items.
Mathematical technique that decomposes a matrix into lower-dimensional matrices, often used in recommendation systems to represent users and items as latent factors.
Matrix factorization algorithm commonly used in collaborative filtering recommender systems. It iteratively updates user and item factors to minimize the squared error between observed and predicted ratings.
Collaborative filtering utilizes user-item interactions for recommendations. Matrix factorization techniques like ALS decompose interaction matrices to capture latent factors. ALS is a specific algorithm for collaborative filtering, implementing matrix factorization with alternating least squares optimization. In essence, collaborative filtering leverages user preferences, matrix factorization captures latent factors, and ALS optimizes this process for making recommendations.