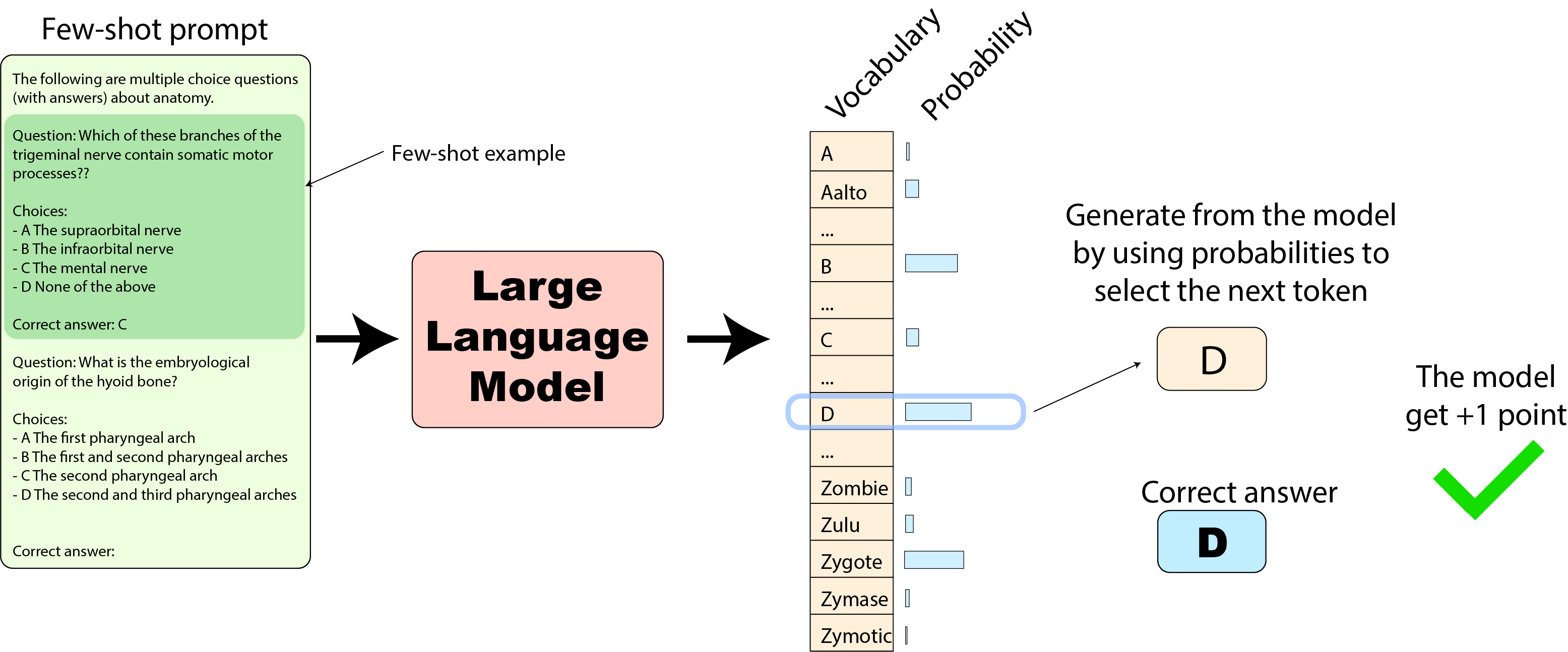
Modern transformer-based language models, particularly the GPT variants, have showcased impressive capabilities in understanding and generating human-like text. One of the promising applications of such models is in the realm of question-answering. Our goal is to explore the potential of these models in a k-shot learning setup for multiple choice questions.
In few-shot learning, "k-shot" refers to using k examples to instruct a model. For transformer-based models, this involves "priming" or "prompting" the model by presenting it with k examples of a particular task. These examples set the context and hint the model about the nature of the task it's expected to perform. The idea is that by observing k examples, the model can better understand and execute subsequent tasks.
Given the k-shot setting, your prompts to the model should be structured as follows:
The following are multiple choice questions (with answers) about [topic].
Question: [Question 1]
A. [Option 1.1]
B. [Option 1.2]
...
Answer: [Correct Answer for Question 1]
...
Question: [Question k]
A. [Option k.1]
B. [Option k.2]
...
Answer: [Correct Answer for Question k]
Question: [Your target question here]
A. [Option 1]
B. [Option 2]
C. [Option 3]
D. [Option 4]
Answer:
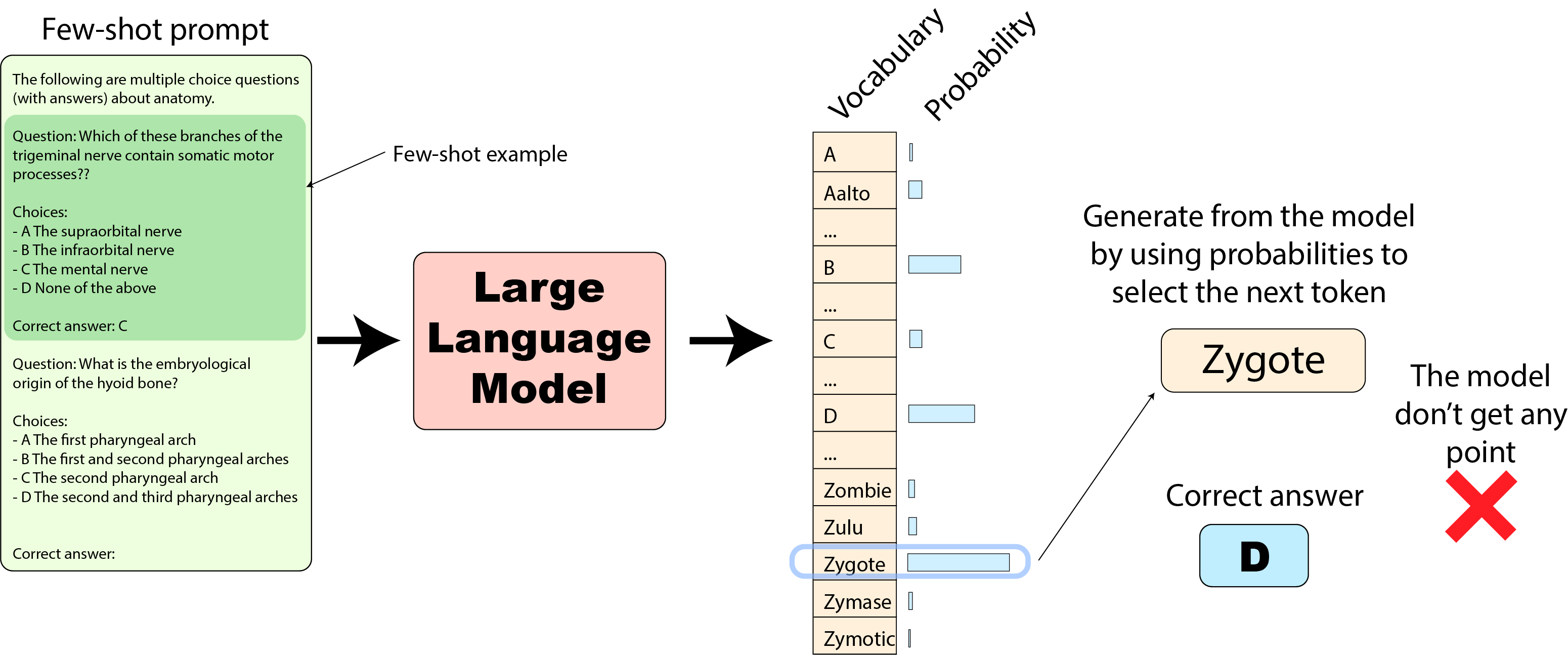
In this approach, if the "Zygote" token was instead the highest probability one (as we’ve seen above), the model answer ("Zygote") would be wrong and the model would not score any points for this question.
Your dataset (under data/) consists of several CSV files, each pertaining to a different topic. Each CSV file contains multiple choice questions, their options, and the correct answer.
For this task, we will use two GPT-2 versions from the Hugging Face library: "gpt-small" and "gpt-medium".
The following is a sample code of how to load the models and their tokenizers.
# Necessary imports
from transformers import GPT2Tokenizer, GPT2LMHeadModel
# Load GPT-2 variants
MODEL_NAME_SMALL = "gpt2" # For the smaller GPT-2 model
MODEL_NAME_LARGE = "gpt2-medium" # For the medium-sized GPT-2 model
tokenizer_small = GPT2Tokenizer.from_pretrained(MODEL_NAME_SMALL)
model_small = GPT2LMHeadModel.from_pretrained(MODEL_NAME_SMALL)
tokenizer_large = GPT2Tokenizer.from_pretrained(MODEL_NAME_LARGE)
model_large = GPT2LMHeadModel.from_pretrained(MODEL_NAME_LARGE)Extract questions, options, and answers from the dataset and structure them according to the k-shot setting.
For each CSV in data/:
- The first K rows + filename (as topic) should be used to build the prompt
- The next N* rows should be used to evaluate the model's performance.
* N will be chosen based on your compute resources.
Prime the model with the first k questions and their answers, then ask the subsequent target question.
Below is a sample function for getting the model's output logits (given a prompt)
from transformers import GPT2Tokenizer, GPT2LMHeadModel
def compute_logits(prompt, model, tokenizer):
"""
Given a prompt, model, and tokenizer, this function computes the logits for the next token(s).
Parameters:
- prompt (str): The input prompt for the model.
- model (GPT2LMHeadModel): An instance of GPT-2 model.
- tokenizer (GPT2Tokenizer): The tokenizer corresponding to the model.
Returns:
- torch.Tensor: The logits predicted by the model for the next token(s).
"""
# Tokenize the input prompt
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# Get model's prediction
with torch.no_grad():
outputs = model(input_ids)
logits = outputs.logits[:, -1, :] # We take the logits corresponding to the last token in the prompt
return logits
# Example usage:
# MODEL_NAME = "gpt2-medium" # Can be "gpt2" for the smaller version
# tokenizer = GPT2Tokenizer.from_pretrained(MODEL_NAME)
# model = GPT2LMHeadModel.from_pretrained(MODEL_NAME)
# prompt = "Your prompt goes here."
# logits = compute_logits(prompt, model, tokenizer)As part of the task, you will have to ensure to manage the token limits of the model, especially when constructing long prompts with larger k values.
If the k-shot prompt is too long token-wise (let's say it's 1024 from now on), then you should construct a k'-shot prompt with k' < k (the largest possible k' that is less than 1024).
Evaluate the two GPT-2 variants' performance across different topics using the described k-shot setting. Dive into:
- Performance variablity across topics.
- Performance variablity across models.
- Impact of varying k on performance. Use k=[1, 3, 5].
- Performance comparison between the two evaluation methods described in 1.3.
By this point, you've probably noticed there's a bunch of experiments to run through. Keeping your code organized will make your life a whole lot easier. 😉
Good luck!