We transform spectro-spatial features from multichannel audio into three token embeddings:
- Source token → captures event content
- DOA token → encodes directional cues
- Distance token → represents source range
These embeddings are inserted into randomly sampled natural language templates and passed through frozen text encoders (CLIP or BERT). The resulting embeddings are then used by a SELD prediction head to jointly estimate event activity, DOA, and distance.
Pre-trained language and multimodal models have emerged as powerful universal encoders, offering transferable embeddings that generalize effectively across diverse tasks. Although prior work has explored these models for spatial sound analysis, particularly in audio-visual contexts, their adaptation to sound event localization and detection (SELD) remains limited. In this paper, we leverage the representational power of large-scale pre-trained text encoders for SELD tasks. First, we transform spectro-spatial audio features from multichannel input into language-compatible token sequences. These comprise an audio token that captures event content, a direction-of-arrival (DOA) token representing directional cues, and a distance token capturing the source range. Subsequently, these tokens are processed by the text encoder to produce compact audio-driven embeddings that jointly capture event identity and spatial attributes. We evaluated our framework on the DCASE stereo SELD dataset, demonstrating consistent improvements over SELD baselines. In addition to improving SELD performance, the proposed framework produces embeddings that serve as structured representations for future multimodal extensions.
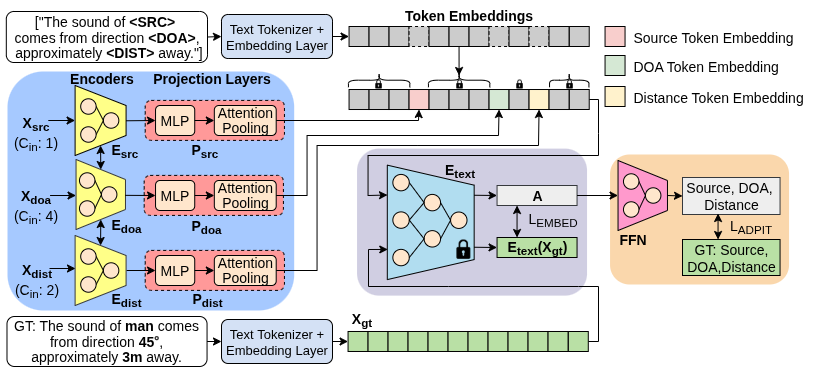
Proposed audio-only SELD framework. Stereo audio features are mapped to three language compatible tokens (audio, DOA and distance) - which are processed by the frozen text encoder to generate an audio-driven embedding (\textbf{A}) which serves as a compact representation of both the event identity and its spatial attributes.
- Three main components are involved in the proposed SELD framework:
- A tokenizer (shaded blue) that transforms spectro-spatial features into language compatible tokens
- A pretrained text encoder (shaded purple) that produces audio-driven embeddings
- A SELD prediction head (shaded peach) that takes the audio-driven embedding as input and predicts the source event and its spatial attributes.
Components Description:
- Tokenizer:
- This module consists: a source tokenzier for capturing the source event name, a DOA tokenzier for capturing the direction of arrival, and a distance tokenzier for capturing the source range.
- Each tokenizer has a feature encoder layer followed by a projection layer.
- To encode event-identity features (
$X_{\text{src}}$ ), we explore two alternatives for the source encoder ($E_{\text{src}}$ ):
(i) BEATs: a transformer-based network BEATs pre-trained in self-supervised manner and
(ii) RCC: a Residual-based CNN-Conformer network.- Directional (
$E_\text{doa}$ ) and distance ($E_\text{dist}$ ) encoders are based on the RCC network.- BEATs: CNN kernel size and stride is modified to
$(5, 16)$ ; we train the weights of CNN and projection head, while keeping the transfomer block frozen.- RCC: Comprises of
$4$ CNN blocks with residual connections, followed by$2$ conformer blocks; Each CNN blocks comprises of main branch with two CNN-BN-ReLU layer (kernel size: $(3, 3)$) and a single CNN-BN layer (kernel size: $(1, 1)$) in a residual branch; their outputs are summed and followed by average pooling.- Additionally, a shared component comprising two conformer blocks is employed as a multi-feature attention layer. This layer jointly process the intermediate source, DOA, and distance features when
$E_\text{src}$ is RCC; otherwise, it operates only on the DOA and distance features.- Segment embeddings are added to each features prior to the multi-feature attention block.
- The resulting outputs are then passed through respective projection layers,
$P_\text{audio}$ ,$P_\text{doa}$ and$P_\text{dist}$ . Each projection layer consists of MLP followed by an attentive pooling layer. The dimension of the output of each projection layer is$\text{embed-dim} = 512$ .- Text encoder:
- We explore two distinct frozen pre-trained text encoders: CLIP and BERT (
$\text{embed-dim} = 512$ ).- Processes structured text templates containing token embeddings.
- SELD prediction head:
- 2 variants:
- GREP (Global Representation Prediction) – Uses [EOT]/[CLS] token embedding (called as audio-driven embedding (
$\mathbf{A}$ )).- TREP (Token Representation Prediction) – Concatenates the source, DOA, and distance token embeddings of contextualized last hidden state of the text encoder.
Overall Configurations: A total of
$8$ model configurations are evaluated, formed by the combinations of:
Source encoder: BEATs or RCC
Text encoder: CLIP or BERT
Prediction head: GREP or TREP
Source Encoder Text Encoder Prediction Head Model Name BEATs CLIP GREP BEATs-CLIP-GREP BEATs BERT GREP BEATs-BERT-GREP RCC CLIP GREP RCC-CLIP-GREP RCC BERT GREP RCC-BERT-GREP BEATs CLIP TREP BEATs-CLIP-TREP BEATs BERT TREP BEATs-BERT-TREP RCC CLIP TREP RCC-CLIP-TREP RCC BERT TREP RCC-BERT-TREP

The model is trained in a supervised manner with two objectives:
(i) aligning the audio-driven embeddings ($\mathbf{A}$ ) with the ground-truth text embeddings ($E_\text{text}(X_\text{gt})$), and
(ii) predicting active source, DOA and distance in the multi-ACCDOA format.
The mean absolute error (MAE) is used to align the audio-driven embeddings with ground-truth text embedding, and the Auxiliary Duplicating Permutation Invariant Training (ADPIT) loss ($L_\text{ADPIT}$ ) for multi-track activity/DOA/distance prediction. In our implementation, the per output regression term inside ADPIT is the mean squared error (MSE) over DOA and distance predictions.
We compute,
(a) Spectrograms of both channels (stereo-format audio data) -- information about the source event
(b) Inter-channel level difference (ILD) -- information about the DOA
(c) Intensity vectors along the y-axis ($\text{IV}_\text{y}$ ) -- information about the DOA
(d) Spectrograms of direct and reverberant components -- information about the distance.
Audio spectrograms were computed using STFT with a
$1024$ -point Hann window and hop size of$480$ samples. At a sampling rate of$24$ kHz, this setup yields$250$ temporal frames for each$5$ -second input clip. From these spectrograms, ILD is computed, while IVy is obtained from the FOA components ($W$ and$Y$ ). Direct and reverberant spectrograms are computed after separating the direct and reverberant components and applying STFT to both components. Finally, all features are projected onto$64$ mel-frequency bins.
To extract these features, follow the below steps:
$ cd features
$ vi config.yml # to change the path in DATASET.
$ python feature_extraction.py # run it for extracting required features
$ python helper.py # run it for putting the multiple features into a single file to avoid multiple input output operations while training the model
The dataset annotations are converted into structured natural language descriptions. Each sound event at a given temporal frame is represented by its event class, azimuth angle and source distance. These values are inserted into the placeholder positions of predefined templates (e.g. 'The sound of
<SRC>comes from direction<DOA>, approximately<DIST>away'). The placeholder template are randomly sampled from predefined set to introduce variations in the textual representations.
The following examples illustrate how random placeholder templates are converted into ground-truth textual descriptions used for supervision.
| # Sources | Placeholder Template | Generated Ground Truth Text |
|---|---|---|
| 0 | The sonic impression of <SRC> originates from direction <DOA>, nearly <DIST> distant. |
No audible sources are detected in the environment. |
| 1 | The sound of <SRC> comes from direction <DOA>, approximately <DIST> away. |
The sound of man comes from direction 30°, approximately 3.5 m away. |
| 2 | The captured audio of <SRC> is localized at direction <DOA>, about <DIST> away. |
The captured audio of man and woman is localized at directions −60° and 80°, about 3 m and 5 m away, respectively. |
| 3 | The acoustic presence of <SRC> is acoustically detected from direction <DOA>, approximately <DIST> distant. |
The acoustic presence of footsteps, door, and knock is acoustically detected from directions 40°, −80°, and 10°, approximately 3 m, 4 m, and 5 m distant, respectively. |
We first train two separate tokenizer modules: one with BEATs and the other with RCC as the source encoder (
$E_\text{src}$ ), while keeping the encoders ($E_\text{doa}$ ,$E_\text{dist}$ ) as RCC.
The training is performed for$100$ epochs with a batch size of 8, optimizing the ADPIT loss ($L_\text{ADPIT}$ ) using the Adam optimizer with learning rate of 0.0001.
$ cd pretraining
$ vi config.yml # to change the path in DATASET and do changes in the model configurations..
$ python models.py # to look the summary and components used in the model.
$ cd ../
$ sbatch pretrain_sbatch.sh
All eight possible model configurations—resulting from the combination of two source encoders, two frozen text encoders, and two prediction heads - are trained for
$50$ epochs with a batch size of 8, optimizing the$L_\text{TOTAL}$ . The Adam optimizer is used with separate learning rates for pretrained weights ($10^{-6}$ ) and newly initialized weights ($10^{-4}$ ). The loss weights are set as$\lambda_\text{EMBED} = 0.01$ and$\lambda_\text{ADPIT} = 1$ .
$ cd finetuning
$ vi config.yml # to change the configurations of source encoder, text encoder, and predictio head for every possible model configuration.
$ python models.py # to look the summary and components used in the model.
$ cd ../
$ sbatch finetune_sbatch.sh
We present a comparison between the the baseline and the proposed framework across eight different model configurations using offcial metrics. It includes -- the class and location-dependent F1 score (
$F_{20^\circ/1}$ ), the class-dependent DOA error ($DOAE$ ), and the class-dependent relative distance error ($RDE$ ). The detection threshold are set to$20^\circ$ for DOA and 1m for relative distance. All metrics are computed at the frame-level for each class independently and then averaged across the number of classes.
Performance comparison between the baseline and the proposed framework across 8 model configurations, defined by the choice of source encoder (E_src), text encoder (E_text), and prediction head (FFN).
| Models | F20°/1 (%) | DOAE (°) | RDE (%) |
|---|---|---|---|
| Baseline | 22.8 | 24.5 | 41.0 |
| BEATs-CLIP-GREP | 33.63 | 17.14 | 40.48 |
| BEATs-BERT-GREP | 31.80 | 17.56 | 32.42 |
| RCC-CLIP-GREP | 33.81 | 17.81 | 38.20 |
| RCC-BERT-GREP | 32.92 | 18.83 | 33.52 |
| BEATs-CLIP-TREP | 31.45 | 19.09 | 32.64 |
| BEATs-BERT-TREP | 29.92 | 19.44 | 35.50 |
| RCC-CLIP-TREP | 31.42 | 19.68 | 32.50 |
| RCC-BERT-TREP | 28.86 | 19.89 | 36.01 |