import torch
import torch.nn as nn
from functools import partialFrancesco Saverio Zuppichini
Today we are going to implement the famous ResNet from Kaiming He et al. (Microsoft Research). It won the 1st place on the ILSVRC 2015 classification task.
Code is here, an interactive version of this article can be downloaded here
The original paper can be read from here (it is very easy to follow) and additional material can be found in this quora answer

This is not a technical article and I am not smart enough to explain residual connection better than the original Authors. So we will limit ourself to a quick overview.
Deeper neural networks are more difficult to train. Why? One big problem of a deep network is the vanishing gradient problem. Basically, the deeper the harder to train.
To solve this problem, the authors proposed to use a reference to the previous layer to compute the output at a given layer. In ResNet, the output from the previous layer, called residual, is added to the output of the current layer. The following picture visualizes this operation
We are going to make our implementation as scalable as possible using one thing unknown to most of the data scientists: object orienting programming
Okay, the first thing is to think about what we need. Well, first of all we must have a convolution layer and since PyTorch does not have the 'auto' padding in Conv2d, we will have to code ourself!
class Conv2dAuto(nn.Conv2d):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.padding = (self.kernel_size[0] // 2, self.kernel_size[1] // 2) # dynamic add padding based on the kernel_size
conv3x3 = partial(Conv2dAuto, kernel_size=3, bias=False)
conv = conv3x3(in_channels=32, out_channels=64)
print(conv)
del convConv2dAuto(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
Next, we use ModuleDict to create a dictionary with different activation functions, this will be handy later.
def activation_func(activation):
return nn.ModuleDict([
['relu', nn.ReLU(inplace=True)],
['leaky_relu', nn.LeakyReLU(negative_slope=0.01, inplace=True)],
['selu', nn.SELU(inplace=True)],
['none', nn.Identity()]
])[activation]If you are unfamiliar with ModuleDict I suggest to read my previous article Pytorch: how and when to use Module, Sequential, ModuleList and ModuleDict
To create a clean code is mandatory to think about the main building block of each application, or of the network in our case. The residual block takes an input with in_channels, applies some blocks of convolutional layers to reduce it to out_channels and sum it up to the original input. If their sizes mismatch, then the input goes into an identity. We can abstract this process and create an interface that can be extended.
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, activation='relu'):
super().__init__()
self.in_channels, self.out_channels, self.activation = in_channels, out_channels, activation
self.blocks = nn.Identity()
self.activate = activation_func(activation)
self.shortcut = nn.Identity()
def forward(self, x):
residual = x
if self.should_apply_shortcut: residual = self.shortcut(x)
x = self.blocks(x)
x += residual
x = self.activate(x)
return x
@property
def should_apply_shortcut(self):
return self.in_channels != self.out_channelsResidualBlock(32, 64)ResidualBlock(
(blocks): Identity()
(activate): ReLU(inplace)
(shortcut): Identity()
)
Let's test it with a dummy vector with one one, we should get a vector with two
dummy = torch.ones((1, 1, 1, 1))
block = ResidualBlock(1, 64)
block(dummy)tensor([[[[2.]]]])
In ResNet, each block has an expansion parameter in order to increase the out_channels if needed. Also, the identity is defined as a Convolution followed by an BatchNorm layer, this is referred to as shortcut. Then, we can just extend ResidualBlock and defined the shortcut function.
class ResNetResidualBlock(ResidualBlock):
def __init__(self, in_channels, out_channels, expansion=1, downsampling=1, conv=conv3x3, *args, **kwargs):
super().__init__(in_channels, out_channels, *args, **kwargs)
self.expansion, self.downsampling, self.conv = expansion, downsampling, conv
self.shortcut = nn.Sequential(
nn.Conv2d(self.in_channels, self.expanded_channels, kernel_size=1,
stride=self.downsampling, bias=False),
nn.BatchNorm2d(self.expanded_channels)) if self.should_apply_shortcut else None
@property
def expanded_channels(self):
return self.out_channels * self.expansion
@property
def should_apply_shortcut(self):
return self.in_channels != self.expanded_channelsResNetResidualBlock(32, 64)ResNetResidualBlock(
(blocks): Identity()
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
A basic ResNet block is composed by two layers of 3x3 conv/batchnorm/relu. In the picture, the lines represent the residual operation. The dotted line means that the shortcut was applied to match the input and the output dimension.
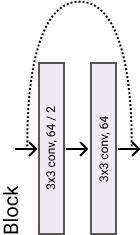
Let's first create an handy function to stack one conv and batchnorm layer
def conv_bn(in_channels, out_channels, conv, *args, **kwargs):
return nn.Sequential(conv(in_channels, out_channels, *args, **kwargs), nn.BatchNorm2d(out_channels))class ResNetBasicBlock(ResNetResidualBlock):
"""
Basic ResNet block composed by two layers of 3x3conv/batchnorm/activation
"""
expansion = 1
def __init__(self, in_channels, out_channels, *args, **kwargs):
super().__init__(in_channels, out_channels, *args, **kwargs)
self.blocks = nn.Sequential(
conv_bn(self.in_channels, self.out_channels, conv=self.conv, bias=False, stride=self.downsampling),
activation_func(self.activation),
conv_bn(self.out_channels, self.expanded_channels, conv=self.conv, bias=False),
)
dummy = torch.ones((1, 32, 224, 224))
block = ResNetBasicBlock(32, 64)
block(dummy).shape
print(block)ResNetBasicBlock(
(blocks): Sequential(
(0): Sequential(
(0): Conv2dAuto(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ReLU(inplace)
(2): Sequential(
(0): Conv2dAuto(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
To increase the network depth
while keeping the parameters size as low as possible, the authors defined a BottleNeck block that
"The three layers are 1x1, 3x3, and 1x1 convolutions, where the 1×1 layers are responsible for reducing and then increasing (restoring) dimensions, leaving the 3×3 layer a bottleneck with smaller input/output dimensions." We can extend the ResNetResidualBlock and create these blocks.
class ResNetBottleNeckBlock(ResNetResidualBlock):
expansion = 4
def __init__(self, in_channels, out_channels, *args, **kwargs):
super().__init__(in_channels, out_channels, expansion=4, *args, **kwargs)
self.blocks = nn.Sequential(
conv_bn(self.in_channels, self.out_channels, self.conv, kernel_size=1),
activation_func(self.activation),
conv_bn(self.out_channels, self.out_channels, self.conv, kernel_size=3, stride=self.downsampling),
activation_func(self.activation),
conv_bn(self.out_channels, self.expanded_channels, self.conv, kernel_size=1),
)
dummy = torch.ones((1, 32, 10, 10))
block = ResNetBottleNeckBlock(32, 64)
block(dummy).shape
print(block)ResNetBottleNeckBlock(
(blocks): Sequential(
(0): Sequential(
(0): Conv2dAuto(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): ReLU(inplace)
(2): Sequential(
(0): Conv2dAuto(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ReLU(inplace)
(4): Sequential(
(0): Conv2dAuto(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(activate): ReLU(inplace)
(shortcut): Sequential(
(0): Conv2d(32, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
A ResNet's layer is composed by same blocks stacked one after the other.
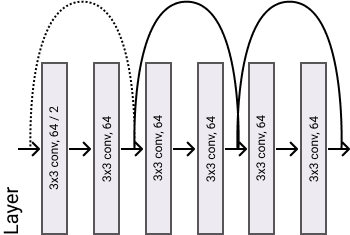
We can easily defined it by just stuck n blocks one after the other, just remember that the first convolution block has a stride of two since "We perform downsampling directly by convolutional layers that have a stride of 2".
class ResNetLayer(nn.Module):
"""
A ResNet layer composed by `n` blocks stacked one after the other
"""
def __init__(self, in_channels, out_channels, block=ResNetBasicBlock, n=1, *args, **kwargs):
super().__init__()
# 'We perform downsampling directly by convolutional layers that have a stride of 2.'
downsampling = 2 if in_channels != out_channels else 1
self.blocks = nn.Sequential(
block(in_channels , out_channels, *args, **kwargs, downsampling=downsampling),
*[block(out_channels * block.expansion,
out_channels, downsampling=1, *args, **kwargs) for _ in range(n - 1)]
)
def forward(self, x):
x = self.blocks(x)
return xdummy = torch.ones((1, 64, 48, 48))
layer = ResNetLayer(64, 128, block=ResNetBasicBlock, n=3)
layer(dummy).shapetorch.Size([1, 128, 24, 24])
Similarly, an Encoder is composed by multiple layer at increasing features size.

class ResNetEncoder(nn.Module):
"""
ResNet encoder composed by layers with increasing features.
"""
def __init__(self, in_channels=3, blocks_sizes=[64, 128, 256, 512], deepths=[2,2,2,2],
activation='relu', block=ResNetBasicBlock, *args, **kwargs):
super().__init__()
self.blocks_sizes = blocks_sizes
self.gate = nn.Sequential(
nn.Conv2d(in_channels, self.blocks_sizes[0], kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(self.blocks_sizes[0]),
activation_func(activation),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.in_out_block_sizes = list(zip(blocks_sizes, blocks_sizes[1:]))
self.blocks = nn.ModuleList([
ResNetLayer(blocks_sizes[0], blocks_sizes[0], n=deepths[0], activation=activation,
block=block,*args, **kwargs),
*[ResNetLayer(in_channels * block.expansion,
out_channels, n=n, activation=activation,
block=block, *args, **kwargs)
for (in_channels, out_channels), n in zip(self.in_out_block_sizes, deepths[1:])]
])
def forward(self, x):
x = self.gate(x)
for block in self.blocks:
x = block(x)
return xThe decoder is the last piece we need to create the full network. It is a fully connected layer that maps the features learned by the network to their respective classes. Easily, we can defined it as:
class ResnetDecoder(nn.Module):
"""
This class represents the tail of ResNet. It performs a global pooling and maps the output to the
correct class by using a fully connected layer.
"""
def __init__(self, in_features, n_classes):
super().__init__()
self.avg = nn.AdaptiveAvgPool2d((1, 1))
self.decoder = nn.Linear(in_features, n_classes)
def forward(self, x):
x = self.avg(x)
x = x.view(x.size(0), -1)
x = self.decoder(x)
return xFinal, we can put all the pieces together and create the final model.
class ResNet(nn.Module):
def __init__(self, in_channels, n_classes, *args, **kwargs):
super().__init__()
self.encoder = ResNetEncoder(in_channels, *args, **kwargs)
self.decoder = ResnetDecoder(self.encoder.blocks[-1].blocks[-1].expanded_channels, n_classes)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return xWe can now defined the five models proposed by the authos, resnet18,34,50,101,152
def resnet18(in_channels, n_classes, block=ResNetBasicBlock, *args, **kwargs):
return ResNet(in_channels, n_classes, block=block, deepths=[2, 2, 2, 2], *args, **kwargs)
def resnet34(in_channels, n_classes, block=ResNetBasicBlock, *args, **kwargs):
return ResNet(in_channels, n_classes, block=block, deepths=[3, 4, 6, 3], *args, **kwargs)
def resnet50(in_channels, n_classes, block=ResNetBottleNeckBlock, *args, **kwargs):
return ResNet(in_channels, n_classes, block=block, deepths=[3, 4, 6, 3], *args, **kwargs)
def resnet101(in_channels, n_classes, block=ResNetBottleNeckBlock, *args, **kwargs):
return ResNet(in_channels, n_classes, block=block, deepths=[3, 4, 23, 3], *args, **kwargs)
def resnet152(in_channels, n_classes, block=ResNetBottleNeckBlock, *args, **kwargs):
return ResNet(in_channels, n_classes, block=block, deepths=[3, 8, 36, 3], *args, **kwargs)Let's use torchsummary to test the model
from torchsummary import summary
model = resnet18(3, 1000)
summary(model.cuda(), (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2dAuto-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
ResNetBasicBlock-11 [-1, 64, 56, 56] 0
Conv2dAuto-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2dAuto-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
ResNetBasicBlock-18 [-1, 64, 56, 56] 0
ResNetLayer-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 128, 28, 28] 8,192
BatchNorm2d-21 [-1, 128, 28, 28] 256
Conv2dAuto-22 [-1, 128, 28, 28] 73,728
BatchNorm2d-23 [-1, 128, 28, 28] 256
ReLU-24 [-1, 128, 28, 28] 0
Conv2dAuto-25 [-1, 128, 28, 28] 147,456
BatchNorm2d-26 [-1, 128, 28, 28] 256
ReLU-27 [-1, 128, 28, 28] 0
ResNetBasicBlock-28 [-1, 128, 28, 28] 0
Conv2dAuto-29 [-1, 128, 28, 28] 147,456
BatchNorm2d-30 [-1, 128, 28, 28] 256
ReLU-31 [-1, 128, 28, 28] 0
Conv2dAuto-32 [-1, 128, 28, 28] 147,456
BatchNorm2d-33 [-1, 128, 28, 28] 256
ReLU-34 [-1, 128, 28, 28] 0
ResNetBasicBlock-35 [-1, 128, 28, 28] 0
ResNetLayer-36 [-1, 128, 28, 28] 0
Conv2d-37 [-1, 256, 14, 14] 32,768
BatchNorm2d-38 [-1, 256, 14, 14] 512
Conv2dAuto-39 [-1, 256, 14, 14] 294,912
BatchNorm2d-40 [-1, 256, 14, 14] 512
ReLU-41 [-1, 256, 14, 14] 0
Conv2dAuto-42 [-1, 256, 14, 14] 589,824
BatchNorm2d-43 [-1, 256, 14, 14] 512
ReLU-44 [-1, 256, 14, 14] 0
ResNetBasicBlock-45 [-1, 256, 14, 14] 0
Conv2dAuto-46 [-1, 256, 14, 14] 589,824
BatchNorm2d-47 [-1, 256, 14, 14] 512
ReLU-48 [-1, 256, 14, 14] 0
Conv2dAuto-49 [-1, 256, 14, 14] 589,824
BatchNorm2d-50 [-1, 256, 14, 14] 512
ReLU-51 [-1, 256, 14, 14] 0
ResNetBasicBlock-52 [-1, 256, 14, 14] 0
ResNetLayer-53 [-1, 256, 14, 14] 0
Conv2d-54 [-1, 512, 7, 7] 131,072
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2dAuto-56 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
Conv2dAuto-59 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-60 [-1, 512, 7, 7] 1,024
ReLU-61 [-1, 512, 7, 7] 0
ResNetBasicBlock-62 [-1, 512, 7, 7] 0
Conv2dAuto-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
Conv2dAuto-66 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-67 [-1, 512, 7, 7] 1,024
ReLU-68 [-1, 512, 7, 7] 0
ResNetBasicBlock-69 [-1, 512, 7, 7] 0
ResNetLayer-70 [-1, 512, 7, 7] 0
ResNetEncoder-71 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-72 [-1, 512, 1, 1] 0
Linear-73 [-1, 1000] 513,000
ResnetDecoder-74 [-1, 1000] 0
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 65.86
Params size (MB): 44.59
Estimated Total Size (MB): 111.03
----------------------------------------------------------------
To check the correctness let's see the number of parameters with the original implementation
import torchvision.models as models
summary(models.resnet18(False).cuda(), (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2d-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
ReLU-7 [-1, 64, 56, 56] 0
Conv2d-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
ReLU-10 [-1, 64, 56, 56] 0
BasicBlock-11 [-1, 64, 56, 56] 0
Conv2d-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
ReLU-14 [-1, 64, 56, 56] 0
Conv2d-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
ReLU-17 [-1, 64, 56, 56] 0
BasicBlock-18 [-1, 64, 56, 56] 0
Conv2d-19 [-1, 128, 28, 28] 73,728
BatchNorm2d-20 [-1, 128, 28, 28] 256
ReLU-21 [-1, 128, 28, 28] 0
Conv2d-22 [-1, 128, 28, 28] 147,456
BatchNorm2d-23 [-1, 128, 28, 28] 256
Conv2d-24 [-1, 128, 28, 28] 8,192
BatchNorm2d-25 [-1, 128, 28, 28] 256
ReLU-26 [-1, 128, 28, 28] 0
BasicBlock-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 128, 28, 28] 147,456
BatchNorm2d-29 [-1, 128, 28, 28] 256
ReLU-30 [-1, 128, 28, 28] 0
Conv2d-31 [-1, 128, 28, 28] 147,456
BatchNorm2d-32 [-1, 128, 28, 28] 256
ReLU-33 [-1, 128, 28, 28] 0
BasicBlock-34 [-1, 128, 28, 28] 0
Conv2d-35 [-1, 256, 14, 14] 294,912
BatchNorm2d-36 [-1, 256, 14, 14] 512
ReLU-37 [-1, 256, 14, 14] 0
Conv2d-38 [-1, 256, 14, 14] 589,824
BatchNorm2d-39 [-1, 256, 14, 14] 512
Conv2d-40 [-1, 256, 14, 14] 32,768
BatchNorm2d-41 [-1, 256, 14, 14] 512
ReLU-42 [-1, 256, 14, 14] 0
BasicBlock-43 [-1, 256, 14, 14] 0
Conv2d-44 [-1, 256, 14, 14] 589,824
BatchNorm2d-45 [-1, 256, 14, 14] 512
ReLU-46 [-1, 256, 14, 14] 0
Conv2d-47 [-1, 256, 14, 14] 589,824
BatchNorm2d-48 [-1, 256, 14, 14] 512
ReLU-49 [-1, 256, 14, 14] 0
BasicBlock-50 [-1, 256, 14, 14] 0
Conv2d-51 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-52 [-1, 512, 7, 7] 1,024
ReLU-53 [-1, 512, 7, 7] 0
Conv2d-54 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2d-56 [-1, 512, 7, 7] 131,072
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
ReLU-58 [-1, 512, 7, 7] 0
BasicBlock-59 [-1, 512, 7, 7] 0
Conv2d-60 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-61 [-1, 512, 7, 7] 1,024
ReLU-62 [-1, 512, 7, 7] 0
Conv2d-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
ReLU-65 [-1, 512, 7, 7] 0
BasicBlock-66 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-67 [-1, 512, 1, 1] 0
Linear-68 [-1, 1000] 513,000
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 62.79
Params size (MB): 44.59
Estimated Total Size (MB): 107.96
----------------------------------------------------------------
It's the same!
One advantage of Object Orienting Programming is that we can easily customize our network.
What if we want to use a different basic block? Maybe we want only one 3x3 conv and maybe with Dropout?. In this case, we can just subclass ResNetResidualBlock and change the .blocks field!
class AnOtherResNetBlock(ResNetResidualBlock):
expansion=1
def __init__(self, in_channels, out_channels, *args, **kwargs):
super().__init__(in_channels, out_channels, *args, **kwargs)
self.blocks = nn.Sequential(
conv3x3(in_channels, out_channels, bias=False, stride=self.downsampling),
nn.Dropout2d(0.2),
activation_func(self.activation),
)Let's pass this new block to resnet18 and create a new architecture!
model = resnet18(3, 1000, block=AnOtherResNetBlock)
summary(model.cuda(), (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
Dropout2d-6 [-1, 64, 56, 56] 0
ReLU-7 [-1, 64, 56, 56] 0
ReLU-8 [-1, 64, 56, 56] 0
AnOtherResNetBlock-9 [-1, 64, 56, 56] 0
Conv2dAuto-10 [-1, 64, 56, 56] 36,864
Dropout2d-11 [-1, 64, 56, 56] 0
ReLU-12 [-1, 64, 56, 56] 0
ReLU-13 [-1, 64, 56, 56] 0
AnOtherResNetBlock-14 [-1, 64, 56, 56] 0
ResNetLayer-15 [-1, 64, 56, 56] 0
Conv2d-16 [-1, 128, 28, 28] 8,192
BatchNorm2d-17 [-1, 128, 28, 28] 256
Conv2dAuto-18 [-1, 128, 28, 28] 73,728
Dropout2d-19 [-1, 128, 28, 28] 0
ReLU-20 [-1, 128, 28, 28] 0
ReLU-21 [-1, 128, 28, 28] 0
AnOtherResNetBlock-22 [-1, 128, 28, 28] 0
Conv2dAuto-23 [-1, 128, 28, 28] 147,456
Dropout2d-24 [-1, 128, 28, 28] 0
ReLU-25 [-1, 128, 28, 28] 0
ReLU-26 [-1, 128, 28, 28] 0
AnOtherResNetBlock-27 [-1, 128, 28, 28] 0
ResNetLayer-28 [-1, 128, 28, 28] 0
Conv2d-29 [-1, 256, 14, 14] 32,768
BatchNorm2d-30 [-1, 256, 14, 14] 512
Conv2dAuto-31 [-1, 256, 14, 14] 294,912
Dropout2d-32 [-1, 256, 14, 14] 0
ReLU-33 [-1, 256, 14, 14] 0
ReLU-34 [-1, 256, 14, 14] 0
AnOtherResNetBlock-35 [-1, 256, 14, 14] 0
Conv2dAuto-36 [-1, 256, 14, 14] 589,824
Dropout2d-37 [-1, 256, 14, 14] 0
ReLU-38 [-1, 256, 14, 14] 0
ReLU-39 [-1, 256, 14, 14] 0
AnOtherResNetBlock-40 [-1, 256, 14, 14] 0
ResNetLayer-41 [-1, 256, 14, 14] 0
Conv2d-42 [-1, 512, 7, 7] 131,072
BatchNorm2d-43 [-1, 512, 7, 7] 1,024
Conv2dAuto-44 [-1, 512, 7, 7] 1,179,648
Dropout2d-45 [-1, 512, 7, 7] 0
ReLU-46 [-1, 512, 7, 7] 0
ReLU-47 [-1, 512, 7, 7] 0
AnOtherResNetBlock-48 [-1, 512, 7, 7] 0
Conv2dAuto-49 [-1, 512, 7, 7] 2,359,296
Dropout2d-50 [-1, 512, 7, 7] 0
ReLU-51 [-1, 512, 7, 7] 0
ReLU-52 [-1, 512, 7, 7] 0
AnOtherResNetBlock-53 [-1, 512, 7, 7] 0
ResNetLayer-54 [-1, 512, 7, 7] 0
ResNetEncoder-55 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-56 [-1, 512, 1, 1] 0
Linear-57 [-1, 1000] 513,000
ResnetDecoder-58 [-1, 1000] 0
================================================================
Total params: 5,414,952
Trainable params: 5,414,952
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 54.38
Params size (MB): 20.66
Estimated Total Size (MB): 75.61
----------------------------------------------------------------
Easy peasy
model = resnet18(3, 1000, activation='leaky_relu')
summary(model.cuda(), (3, 224, 224))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
LeakyReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
Conv2dAuto-5 [-1, 64, 56, 56] 36,864
BatchNorm2d-6 [-1, 64, 56, 56] 128
LeakyReLU-7 [-1, 64, 56, 56] 0
Conv2dAuto-8 [-1, 64, 56, 56] 36,864
BatchNorm2d-9 [-1, 64, 56, 56] 128
LeakyReLU-10 [-1, 64, 56, 56] 0
ResNetBasicBlock-11 [-1, 64, 56, 56] 0
Conv2dAuto-12 [-1, 64, 56, 56] 36,864
BatchNorm2d-13 [-1, 64, 56, 56] 128
LeakyReLU-14 [-1, 64, 56, 56] 0
Conv2dAuto-15 [-1, 64, 56, 56] 36,864
BatchNorm2d-16 [-1, 64, 56, 56] 128
LeakyReLU-17 [-1, 64, 56, 56] 0
ResNetBasicBlock-18 [-1, 64, 56, 56] 0
ResNetLayer-19 [-1, 64, 56, 56] 0
Conv2d-20 [-1, 128, 28, 28] 8,192
BatchNorm2d-21 [-1, 128, 28, 28] 256
Conv2dAuto-22 [-1, 128, 28, 28] 73,728
BatchNorm2d-23 [-1, 128, 28, 28] 256
LeakyReLU-24 [-1, 128, 28, 28] 0
Conv2dAuto-25 [-1, 128, 28, 28] 147,456
BatchNorm2d-26 [-1, 128, 28, 28] 256
LeakyReLU-27 [-1, 128, 28, 28] 0
ResNetBasicBlock-28 [-1, 128, 28, 28] 0
Conv2dAuto-29 [-1, 128, 28, 28] 147,456
BatchNorm2d-30 [-1, 128, 28, 28] 256
LeakyReLU-31 [-1, 128, 28, 28] 0
Conv2dAuto-32 [-1, 128, 28, 28] 147,456
BatchNorm2d-33 [-1, 128, 28, 28] 256
LeakyReLU-34 [-1, 128, 28, 28] 0
ResNetBasicBlock-35 [-1, 128, 28, 28] 0
ResNetLayer-36 [-1, 128, 28, 28] 0
Conv2d-37 [-1, 256, 14, 14] 32,768
BatchNorm2d-38 [-1, 256, 14, 14] 512
Conv2dAuto-39 [-1, 256, 14, 14] 294,912
BatchNorm2d-40 [-1, 256, 14, 14] 512
LeakyReLU-41 [-1, 256, 14, 14] 0
Conv2dAuto-42 [-1, 256, 14, 14] 589,824
BatchNorm2d-43 [-1, 256, 14, 14] 512
LeakyReLU-44 [-1, 256, 14, 14] 0
ResNetBasicBlock-45 [-1, 256, 14, 14] 0
Conv2dAuto-46 [-1, 256, 14, 14] 589,824
BatchNorm2d-47 [-1, 256, 14, 14] 512
LeakyReLU-48 [-1, 256, 14, 14] 0
Conv2dAuto-49 [-1, 256, 14, 14] 589,824
BatchNorm2d-50 [-1, 256, 14, 14] 512
LeakyReLU-51 [-1, 256, 14, 14] 0
ResNetBasicBlock-52 [-1, 256, 14, 14] 0
ResNetLayer-53 [-1, 256, 14, 14] 0
Conv2d-54 [-1, 512, 7, 7] 131,072
BatchNorm2d-55 [-1, 512, 7, 7] 1,024
Conv2dAuto-56 [-1, 512, 7, 7] 1,179,648
BatchNorm2d-57 [-1, 512, 7, 7] 1,024
LeakyReLU-58 [-1, 512, 7, 7] 0
Conv2dAuto-59 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-60 [-1, 512, 7, 7] 1,024
LeakyReLU-61 [-1, 512, 7, 7] 0
ResNetBasicBlock-62 [-1, 512, 7, 7] 0
Conv2dAuto-63 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-64 [-1, 512, 7, 7] 1,024
LeakyReLU-65 [-1, 512, 7, 7] 0
Conv2dAuto-66 [-1, 512, 7, 7] 2,359,296
BatchNorm2d-67 [-1, 512, 7, 7] 1,024
LeakyReLU-68 [-1, 512, 7, 7] 0
ResNetBasicBlock-69 [-1, 512, 7, 7] 0
ResNetLayer-70 [-1, 512, 7, 7] 0
ResNetEncoder-71 [-1, 512, 7, 7] 0
AdaptiveAvgPool2d-72 [-1, 512, 1, 1] 0
Linear-73 [-1, 1000] 513,000
ResnetDecoder-74 [-1, 1000] 0
================================================================
Total params: 11,689,512
Trainable params: 11,689,512
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 65.86
Params size (MB): 44.59
Estimated Total Size (MB): 111.03
----------------------------------------------------------------
In this article we have seen how to implement ResNet in a nice, scalable and customizable way. In the next article we are going to further expand this architecture by using Preactivation and Squeeze and Excitation!
All the code is here
If you are interested in understing better neural network I suggest you to read one other article that I made
Thank you for reading
Francesco Saverio Zuppichini