本文会通过 Keras 搭建一个深度卷积神经网络来识别眼部疾病图像的病变程度,在验证集上的准确率可以达到100%,建议使用显卡来运行该项目。本项目使用的 Keras 版本是1.2.2。如果你使用的是更高级的版本,可能会稍有函数的变化。
数据集是我导师给的私人数据,若有需要,请私下联系我,目录结构如下:
➜ ls data/1 | head
1 (1).jpg
1 (2).jpg
1 (3).jpg
1 (4).jpg
➜ ls data/2 | head
2 (1).jpg
2 (2).jpg
2 (3).jpg
2 (4).jpg
2 (5).jpg
2 (6).jpg
……
可以看到,我们的数据集很小,只有80张图片,而且数据不均匀,所以我们需要对数据进行一个扩展,我们将通过一系列随机变换堆数据进行提升,这样我们的模型将看不到任何两张完全相同的图片,这有利于我们抑制过拟合,使得模型的泛化能力更好。
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
for i in range(7):
pic_name = '6 (' + str(i+1) + ')'
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
img = load_img('data/6/' + pic_name + '.jpg') # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1,) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
# the .flow() command below generates batches of randomly transformed images
# and saves the results to the `preview/` directory
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='data/6', save_prefix='gen_eye'+pic_name, save_format='jpeg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefinitely效果如下图(眼球图片实在有些高能,所以我用了猫的图片来示意。)

对于这个问题来说,使用预训练的网络是最好不过的了,一种有效的方法是综合各个不同的模型,从而得到不错的效果,兼听则明。如果是直接在一个巨大的网络后面加我们的全连接,那么训练10代就需要跑十次巨大的网络,而且我们的卷积层都是不可训练的,那么这个计算就是浪费的。所以我们可以将多个不同的网络输出的特征向量先保存下来,以便后续的训练,这样做的好处是我们一旦保存了特征向量,即使是在普通笔记本上也能轻松训练。
from keras.models import *
from keras.layers import *
from keras.applications import *
from keras.preprocessing.image import *
import h5py
def write_gap(function_name, MODEL, image_size, lambda_func=None):
width = image_size[0]
height = image_size[1]
input_tensor = Input((height, width, 3))
x = input_tensor
if lambda_func:
x = Lambda(lambda_func)(x)
base_model = MODEL(input_tensor=x, weights='imagenet', include_top=False)
model = Model(base_model.input, GlobalAveragePooling2D()(base_model.output))
gen = ImageDataGenerator()
train_generator = gen.flow_from_directory("data", image_size, shuffle=False,
batch_size=64)
train = model.predict_generator(train_generator, train_generator.nb_sample)
with h5py.File("gap_%s.h5" % function_name) as h:
h.create_dataset("train", data=train)
h.create_dataset("label", data=train_generator.classes)
# h.create_dataset("label_map", data=train_generator.class_indices)
write_gap('ResNet50', ResNet50, (224, 224))
write_gap('InceptionV3', InceptionV3, (299, 299), inception_v3.preprocess_input)
write_gap('Xception', Xception, (299, 299), xception.preprocess_input)为了复用代码,写一个函数是非常有必要的,那么我们的函数就需要输入模型,输入图片的大小,以及预处理函数,因为 Xception 和 Inception V3 都需要将数据限定在 (-1, 1) 的范围内,然后我们利用 GlobalAveragePooling2D 将卷积层输出的每个激活图直接求平均值,不然输出的文件会非常大,且容易过拟合。然后我们定义了两个 generator,利用 model.predict_generator 函数来导出特征向量,最后我们选择了 ResNet50, Xception, Inception V3 这三个模型(如果有兴趣也可以导出 VGG 的特征向量)。每个模型导出的时间都挺长的,用 GTX 1080 Ti 上大概需要用五分钟到十分钟。 这三个模型都是在 ImageNet 上面预训练过的,所以每一个模型都可以说是身经百战,通过这三个老司机导出的特征向量,可以高度概括一张图片有哪些内容,最后导出的 h5 文件包括三个 numpy 数组:
经过上面的代码以后,我们获得了三个特征向量文件,分别是:
- gap_ResNet50.h5
- gap_InceptionV3.h5
- gap_Xception.h5
我们需要载入这些特征向量,并且将它们合成一条特征向量,然后记得把 X 和 y 打乱,不然之后我们设置validation_split的时候会出问题。这里设置了 numpy 的随机数种子为2017,这样可以确保每个人跑这个代码,输出都能是一样的结果。
import h5py
from sklearn.utils import shuffle
from keras.models import *
from keras.layers import *
from keras.utils import np_utils
from keras.preprocessing.image import *
if __name__ == '__main__':
np.random.seed(2017)
X_train = []
# X_test = []
for filename in ["gap_ResNet50.h5", "gap_InceptionV3.h5", "gap_Xception.h5"]:
print('加载'+filename)
with h5py.File(filename, 'r') as h:
X_train.append(np.array(h['train']))
# X_test.append(np.array(h['test']))
y_train = np.array(h['label'])
X = np.concatenate(X_train, axis=1)
# X_test = np.concatenate(X_test, axis=1)
X_train, y_train = shuffle(X, y_train)
input_tensor = Input(X_train.shape[1:])
x = input_tensor
x = Dropout(0.5)(x)
x = Dense(100, activation='softmax')(x)
model = Model(input_tensor, x)
model.compile(optimizer='adadelta',
loss='categorical_crossentropy',
metrics=['accuracy'])
y_train = np_utils.to_categorical(y_train, 100)
model.fit(X_train, y_train, batch_size=64, nb_epoch=100, validation_split=0.1)
# model.save('model.h5')
y_pred = model.predict(X_train, verbose=1)
y_pred = np.argmax(y_pred, axis=1)
print(y_pred[0])网络结构如下:
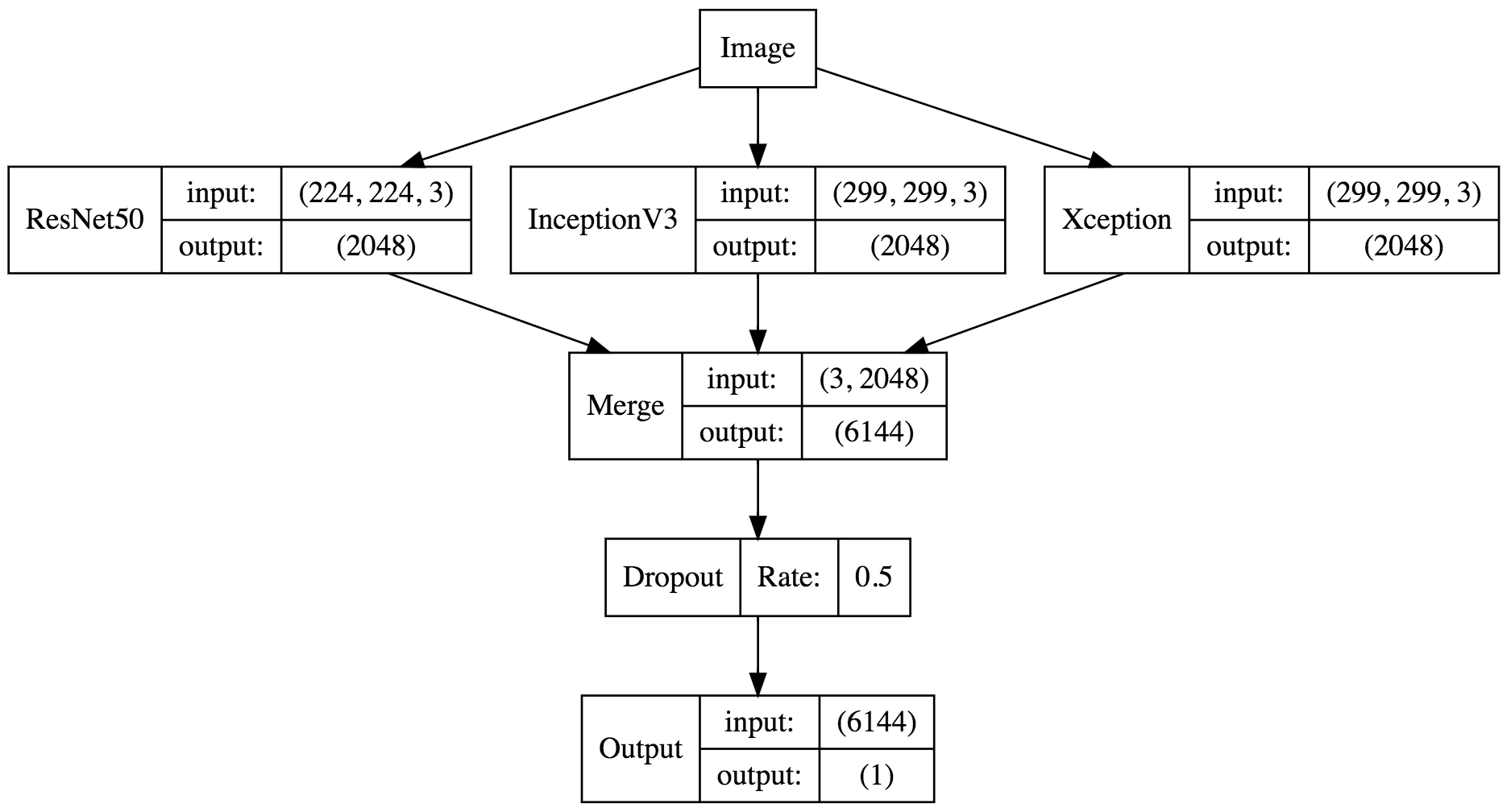
模型构件好了以后,我们就可以进行训练了,这里我们设置验证集大小为 10% ,也就是说训练集是1560张图,验证集是174张图。
Train on 1560 samples, validate on 174 samples
poch 1/100
1560/1560 [==============================] - 1s - loss: 1.8587 - acc: 0.3686 - val_loss: 1.0700 - val_acc: 0.6264
Epoch 2/100
1560/1560 [==============================] - 0s - loss: 0.9671 - acc: 0.6282 - val_loss: 0.7052 - val_acc: 0.8103
Epoch 3/100
1560/1560 [==============================] - 0s - loss: 0.7202 - acc: 0.7474 - val_loss: 0.5578 - val_acc: 0.8506
Epoch 4/100
1560/1560 [==============================] - 0s - loss: 0.5995 - acc: 0.8013 - val_loss: 0.4614 - val_acc: 0.8966
Epoch 5/100
…………
Epoch 60/100
1560/1560 [==============================] - 0s - loss: 0.0204 - acc: 0.9974 - val_loss: 0.0382 - val_acc: 0.9943
Epoch 61/100
1560/1560 [==============================] - 0s - loss: 0.0170 - acc: 0.9987 - val_loss: 0.0295 - val_acc: 0.9943
Epoch 62/100
1560/1560 [==============================] - 0s - loss: 0.0171 - acc: 0.9994 - val_loss: 0.0289 - val_acc: 0.9943
Epoch 63/100
1560/1560 [==============================] - 0s - loss: 0.0151 - acc: 1.0000 - val_loss: 0.0249 - val_acc: 1.0000
…………
我们可以看到,训练的过程很快,十秒以内就能训练完,准确率也很高,在验证集上最高达到了100%的准确率。
大体思路就是,用预训练模型进行特征提取,再自己构造一个全链接神经网络进行图像分类。也可以看作是在别人的CNN后面加了一层Dropout和全链接,然后把别人的CNN参数固定,只改变我们自己的参数。实现的功能是,给我这种病的图片,我能得出它病变的程度,并给出准确率99%以上的结果。
参考链接:
- ResNet 15.12
- Inception v3 15.12
- Xception 16.10
- 面向小数据集构建图像分类模型
- 猫狗大战