CHIELD is a searchable database of causal hypotheses in evolutionary linguistics. You can visit the live website here: http://chield.excd.org/.
Help using CHIELD can be found here.
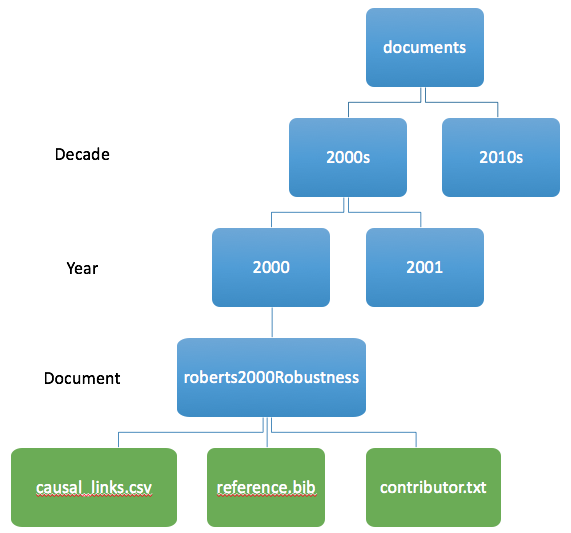
The canonical version of the data is the folder tree data/tree/documents. A script compiles this into a database file for use on the website.
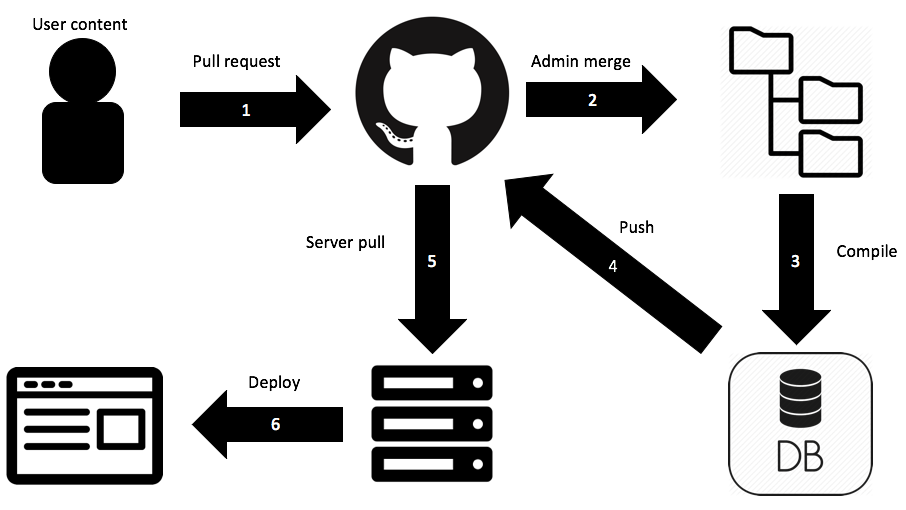
- Pull reqest
- User creates new data on the website
- User submits the data to a php script which:
- Writes the data to a file on the server side folder
newRecords- Calls the python filesendToRepo.py sendToRepo.pyreads the new files and:- Decodes the data into seperate bib, csv and contributor files
- Creates the files on a new branch in the GitHub repository
- Creates a pull request for the new branch
- The GitHub administrator reviews the pull request and merges it into the repository
- The new data now lives in
data/tree/documents
- The new data now lives in
- The GitHub administrator runs the
deploy.shscript to rebuild the database - The GitHub administrator pushes the changes back to the GitHub repository
The server administrator periodically:
- Pulls the changes to the repository to a local version
- Calls the
deploy.sh -sscript to depoly the code to the web folder (the-sswitch avoids changing the repository items, minimising git strife)
The folder app/data should be deployed to the private folder of your web server.
The folder app/Site should be deployed to the public folder of your web server.
The script deploy.sh is designed to do this automatically. It requres some shell variables to be set, which it sources from deploy_config.sh (for security and configuration reasons this file is not included in the repository):
server_public_folder="/path/to/public/CHIELD/Site/"
server_private_folder="/path/to/private/CHIELD/data/"
path_to_python="/path/to/python"
The path_to_python variable should be set to the absolute path of the python executable. This can be found by running which python. (on my mac it was /Library/Frameworks/Python.framework/Versions/3.5/bin/python3)
The python script that uploads data to github requires some parameters. These are imported from a python script in app/data/githubConfig.py. For security reasons, this is not included in the public repository, and should not be made public (include this file's path in your .gitignore file).
The file should set the following parameters:
githubUser = "CHIELDOnline"
githubAccessToken = "PasteYourGithubAccessTokenHere"
githubRepoName = "CHIELD"
repository_data_tree_folder = "/data/tree/documents/"
Github access tokens can be generated through GitHub.
The server side requires R for deployment and python for various database functions.
Required R libraries include: "digest", "stringr", "dplyr", "dbplyr", "RSQLite", "bibtex", "readr".
Python requires the package "pygithub": https://github.com/PyGithub/PyGithub