A new challenge set for machine translation covering over 500 languages and thousands of language pairs.
- Benchmark for realistic low-resource scenarios
- Training, development and test data
- Baseline models and results (training procedures)
- Ideal for multilingual models and transfer learning
- New: The status of available NMT models on a map
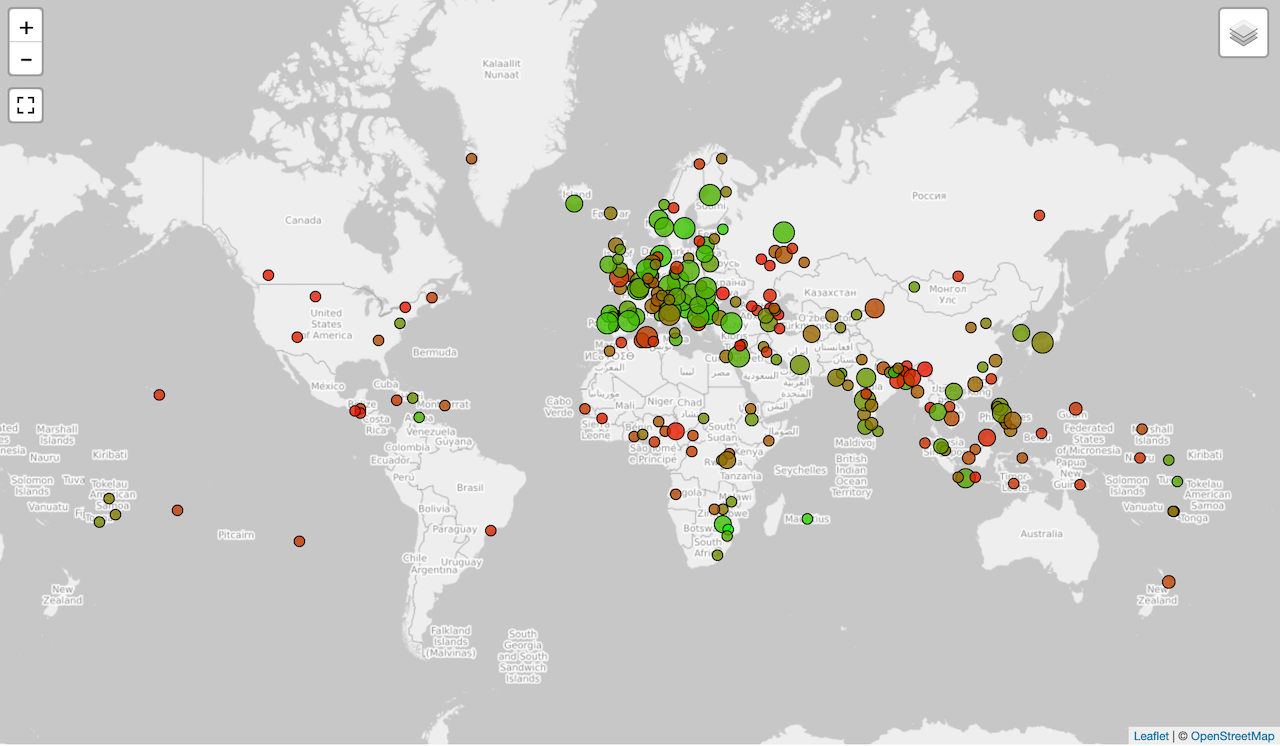
- Zero-shot machine translation (data: zero)
- Low and even lower resource MT (data: low, lower)
- Medium, higher and highest resource MT (data: medium, higher, highest)
- Contribute reference translations via Tatoeba
- Test data (v2020-07-28)
- Development data (v2020-07-28)
- Bilingual training data (language-pair specific downloads)
- Extra bilingual training data (language-pair specific downloads)
- Monolingual data sets, with document boundaries, de-duplicated and shuffled
- Incrementally updated development and test data, (here for individual language pairs)
- NEW: Automatically translated monolingual data
This package provides data sets for machine translation in many languages with test data taken from Tatoeba.
The Tatoeba translation challenge includes shuffled training data taken from OPUS and test data from Tatoeba via the aligned data set in OPUS. All data sets are normalised to ISO-639-3 language codes (so much as possible) using macro-languages in case there are various individual sub-languages available. Naturally, training data do not include Tatoeba sentences and the popular WMT testsets are not included to allow a fair comparison to other models using those data sets.
This is an open challenge and the idea s to encourage people to develop machine translation in real-world cases for many languages. The most important point is to get away from artificial settings that simulate low-resource scenarios or zero-shot translations. Here, we extracted data sets with all the data we have in a large collection of parallel corpora instead and do not reduce high-resource scenarios in an unnatural way. Tatoeba is, admittedly, a rather easy test set in general but it includes a wide varity of languages and makes it easy to get started with rather encouraging results even for lesser resourced languages. The release also includes medium and high resource settings and allows a wide range of experiments with all supported language pairs including studies of transfer learning and pivot-based methods.
Please, cite the following paper if you use data and models from this distribution:
@inproceedings{tiedemann-2020-ttc,
title = "The {T}atoeba {T}ranslation {C}hallenge -- {R}ealistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation (Volume 1: Research Papers)",
year = "2020",
publisher = "Association for Computational Linguistics",
url = {https://arxiv.org/abs/2010.06354}
}
The current release includes data for 2,963 language pairs covering 555 languages. The data sets are released per language pair with the following structure (using deu-eng as an example):
data/deu-eng/
data/deu-eng/train.src.gz
data/deu-eng/train.trg.gz
data/deu-eng/train.id.gz
data/deu-eng/dev.id
data/deu-eng/dev.src
data/deu-eng/dev.trg
data/deu-eng/test.src
data/deu-eng/test.trg
data/deu-eng/test.id
Files with the extension .src refer to sentences in the source language (deu in this case) and files with extension .trg contain sentences in the target laguage (eng here). File with extension .id include the ISO-639-3 language labels with possibly extensions about the orthographic script and information about regional variants. In the .id file for the training data there are also labels for the OPUS corpus the sentences come from.
Other notes about the compilation of the data sets can be found in Development.md and the complete lists of language pairs is in Data.md.
New releases are planned in the future and will be announced here. Development and test data will be updated regularly but the original test sets will stay in the release. Updates of the test data will be available through this devtest release and will not include any examples available in development data. Those data sets are also available from this git repository in the sub directory data/devtest/.
The main challenge is to develop translation models and to test them with the given test data from Tatoeba. The focus is on low-resource languages and to push their coverage and translation quality. Resources for high-resource are also provided and can be used as well for translation modelling of those languages and for knowledge transfer to less resourced languages. Note that not all language pairs have sufficient data sets for test, development (dev) and training (train) data. Hence, we divided the Tatoeba challenge data into various subsets:
- high-resource settings (higher and highest)
- medium-sized resource settings (medium)
- low-resource settings (lower and lowest)
- zero-shot translation (zero)
For all those selected language pairs, the data set provides at least 200 sentences per test set. Note, that everything below 1,000 sentences is probably not very reliable as a proper test set but, here we go, what can we do for real-world cases of low-resource languages?
The most important ingredient for improved translation quality is data. It is not only about training data but very much also about appropriate test data that can help to push the development of transfer models and other ideas of handling low-resource settings. Therefore, another challenge we want to open here is to increase the coverage of test sets for low-resource languages. This challenge is really important and contributions are necessary. The approach here would be to directly contribute translations for your favorite language directly to the Tatoeba data collection. The new translations will make their way into the data set here through OPUS! Make an effort and provide new data already today!
- A list of language pairs with a test set below 1,000 examples
- A list of language pairs with a test set below 200 examples
- A list of language pairs with training data but no test data from Tatoeba (paired with English only)
We also encourage to incorporate other test sets besides of the Tatoeba data. Raise an issue in the issue tracker if you want to propose / provide additional test data. This is especially interesting for less-common language combinations. Please, contribute!
There are some initial baseline results for parts of the data set using the setup of OPUS-MT but running on Tatoeba MT challenge data (see also OPUS-MT-TatoebaChallenge).
- available translation models
- results for the zero-shot language pairs
- results for the lowest resource language pairs
- results for the lower resource language pairs
- results for the medium resource language pairs
- results for the higher resource language pairs
- results for the highest resource language pairs
- results for multilingual models of various ISO639-5 language groups
- all results sorted by chrF2 scores
- all results sorted by language pair
We will also publish (reasonable) models to be re-used and deployed through OPUS-MT and linked from the model subdir in this github. This includes multilingual models that cover several languages in source and target to enable transfer learning across languages. For example, there are multilingual models for
- all the zero resource language pairs
- all the lowest resource language pairs
- all the lower resource language pairs
- multilingual models of various ISO639-5 language groups
- bel+rus+ukr-bel+rus+ukr
Everyone interested is free to use the data for their own development. Naturally, we encourage contributions by the community and will develop a leader board for individual language pairs. The idea is also to make pre-trained models available in order to support re-use and replciability. This will be organised in connection with OPUS-MT and translation models integrated in huggingface.
Certain rules apply:
- Don't use any dev or test data for training (dev can be used for validation during training as an early stopping criterion).
- Only use the provided training data for training models with comparable results in constrained settings. Any combination of language pairs is fine or backtranslation of sentences included in training data for any language pair is allowed, too. That means that additional data sets, parallel or monolingual, are not allowed for official models to be compared with others. Unconstrained models may also be trained and can be reported as a separate category.
- Using pre-trained language or translation models fall into the unconstrained category. Make sure that the pre-trained model does not include Tatoeba data that we reserve for testing! Note that current OPUS-MT models can not be used as they contain Tatoeba data that may overlap with the test data in this release!
- We encourage to make the models available through OPUS-MT or other public means. This ensures replicability and re-use of pre-trained models! If you want to enter the official leader board you must have to make your model available including instructions on how to use them!
Don't hesitate to contact us in case of questions and suggestions. Thanks for your contributions and enjoy!
The labels are converted from the original OPUS language IDs (which are mostly ISO-639-1) and information about the script is automatically assigned using Unicode regular expressions and counting letters from specific script character properties. Only the most frequently present script is shown. Be aware of mixed content and possible mistakes in the assignment. Note that the code Zyyy refers to common characters that cannot be used to distinguish scripts. The script code is not added if there is only one script in that language and no other scripts are detected in the string. If there is a default script among several alternatives then this script is not shown either. Note that the assignment is done fully automatically and no corrections have been made. This may go wrong for several reasons. For illustration, here is an example for Serbo-Croatian languages and Chinese from the Tatoeba test data:
bos_Latn cmn_Hani Želim da mi ti kažeš istinu. 我想你把真相告诉我。
hrv cmn_Hani Molim Vas odgovorite na moje pitanje. 请回答我的问题。
hrv cmn_Hani Hvala ti, ne bih to mogao bez tebe. 没有你我无法做到,谢谢。
hrv cmn_Hani Ti si moja majka. 你是我妈妈。
srp_Cyrl cmn_Kana То је моја мачка. 那是我的猫。
hrv cmn_Yiii Bok. 你好。
Test and development data are taken from a shuffled version of Tatoeba. All translation alternatives are included in the data set to obtain the best coverage of languages in the collection. Development and test sets are disjoint in the sense that they do not include identical source-target language sentence pairs. However, there can be identical source sentences or identical target sentences in both sets, which are not linked to the same translations. Similarily, there can be identical source or target sentences in one of the sets, for example the test set, with different translations. Below, you can see examples from the Esperanto-Ladino test set:
epo lad Kio estas vorto? קי איס און ביירבﬞו?
epo lad Kio estas vorto? קי איס אונה פאלאבﬞרה?
epo lad_Latn Ĉu vi estas en Berlino? Estash en Berlin?
epo lad_Latn Ĉu vi estas en Berlino? Vos estash en Berlin?
epo lad_Latn Ĉu vi estas en Berlino? Vozotras estash en Berlin?
epo lad_Latn La hundo estas nigra. El perro es preto.
epo lad_Latn La hundo nigras. El perro es preto.
The test data could have been organized as multi-reference data sets but this would require to provide different sets in both translation directions. Removing alternative translations is also not a good option as this would take away a lot of relevant data. Hence, we decided to provide the data sets as they are, which implicitly creates multi-reference test sets but with the wrong normalization.
These data are released under this licensing scheme:

Notice: Should you consider that our data contains material that is owned by you and should therefore not be reproduced here, please:
- Clearly identify yourself, with detailed contact data such as an address, telephone number or email address at which you can be contacted.
- Clearly identify the copyrighted work claimed to be infringed.
- Clearly identify the material that is claimed to be infringing and information reasonably sufficient to allow us to locate the material.
- And contact Jörg Tiedemann at the following email address: jorg DOT tiedemann AT helsinki.fi.
Take down: We will comply to legitimate requests by removing the affected sources from the next release of the data set.