A VNF provisioner for the Siren project. This is intended to be a modular component that could be used with higher level orchestration logic (such as **). At the moment, it exposes the infrastructure topology (location of available resouces and the time they are held up for) through a RESTful interface. For provisioning of resources, it accepts TOSCA YAML and Docker files through a RESTful interface, to deploy the service, it uses the docker remote API.
**Complementary component to this: https://github.com/broadbent/airship
For visualisation of the provisioner and the Fog infrastructure see: https://github.com/lyndon160/Siren-Visualiser
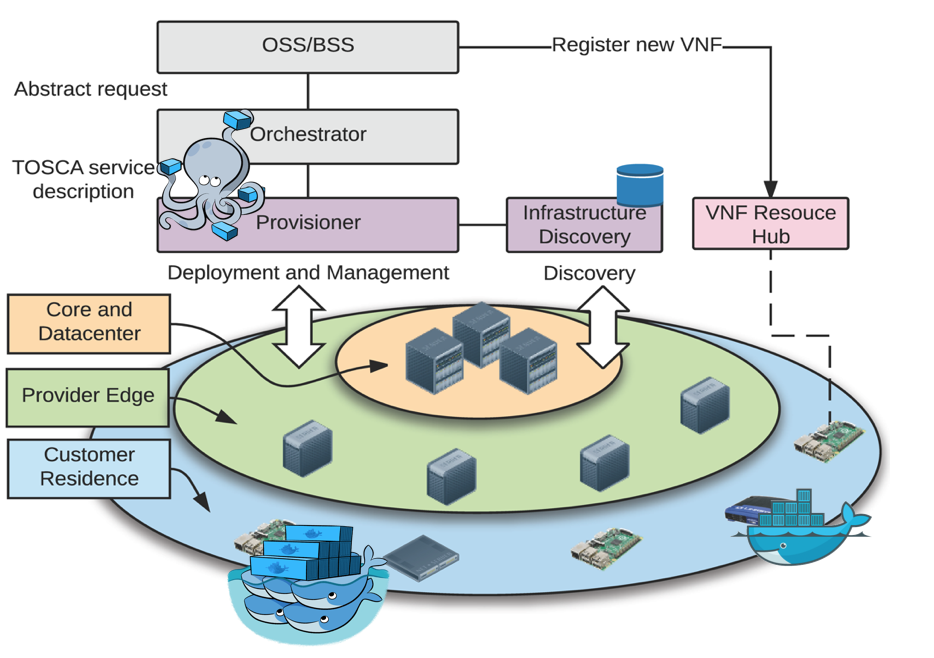
Siren's Provisioner is currently developed in python, it requires version 2.7 to be installed.
Clone this repository:
git clone https://github.com/lyndon160/Siren-Provisioner.git
Pip requirements TODO:
pip install -r requirements.txt
To run the provsioner, simply do:
python ./Provisioner.py
- Dynamic discovery; Allow new devices to join and leave the infrastructure.
- Service lifecycle with failover.
- Make threads safe.
Example usage: GET http://127.0.0.1:60000/nodes
All post requests take JSON input.
For a simple orchestration program, only /nodes and /provision_x should be required.
This returns information about all of the available nodes as list like this one: [{"reserved_memory": 200, "available_memory": 800, "total_memory": 1024, "id": "148.88.227.179", "arch": "armv7l", "location": "residence"}, {"reserved_memory": 0, "available_memory": 1024, "total_memory": 1024, "id": "148.88.227.232", "arch": "armv7l", "location": "residence"}]
/nodes
This returns information about a single node. Not sure how useful this is.
/nodes/{id}
This returns information similar to nodes but includes running containers
/nodes/containers
This provisions a docker image to multiple devices for a set amount of time with a reservation on RAM
This requires: [List nodes] [String image_name] [Int ram] [Int hours]
/nodes/provision_dockers
TODO
/provision_toscas
/remove_service_by_id
/remove_service
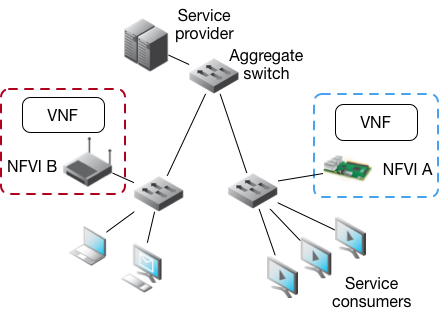
The evaluation so far compares the cost to the network in three scenarios: 1) a vCache VNF being deployed using a first fit clustering policy 2) a vCache VNF being deployed using an context-optimised policy and 3) using no CDN and requesting video directly from content provider source. The vCache is deployed to the NFVI (Raspberry Pi) as a Docker container. The video in use for the case study is a 1080p version of the Big Buck Bunny standard testing video and is 276.1MB in size. During each experiment iteration, three clients are watching the video and traffic is being monitored and recorded on the aggregate switch to evaluate the difference between deployment techniques. In the in second test, where optimised placement is used, the content provider requests information about latency between the service customers and the available NFVIs to determine the closest one to deploy to.
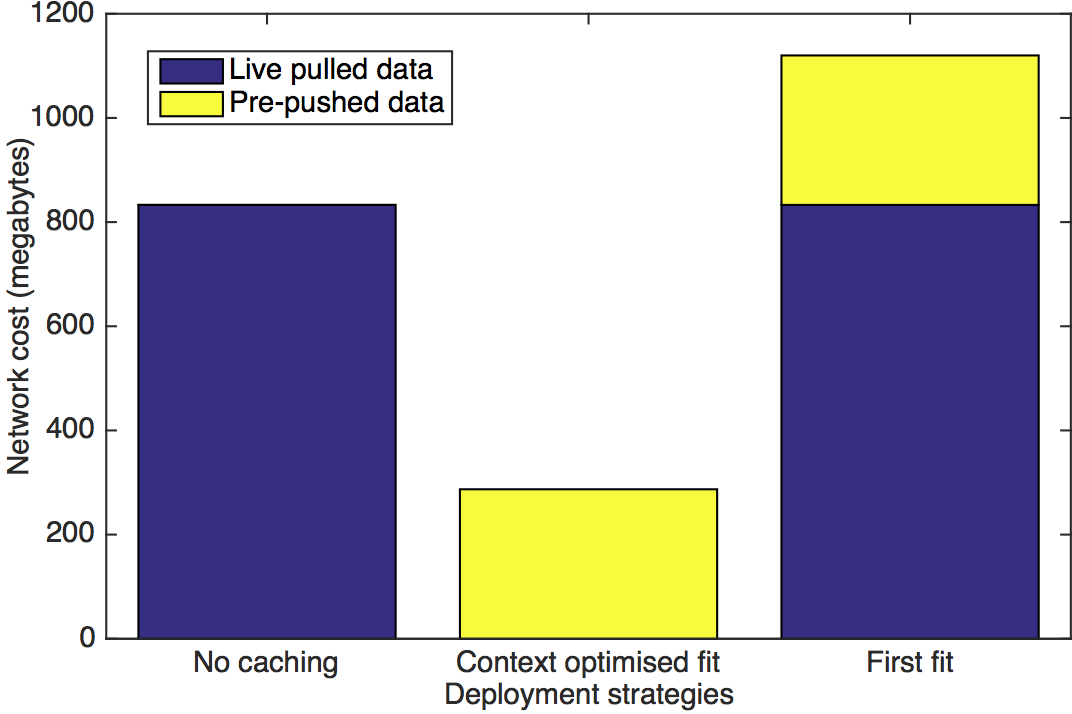
The diagram above shows the results of three VNF placement techniques. The stacked bar chart shows live data which is data that was pulled over the aggregate switch whilst clients were watching the video, and pre-pushed data which is the cost of pushing the vCache VNF.
In this instance we can see that the contextual information provided by siren allowed for the VNF to be placed much closer to the client on NFVI B, thus reducing observed traffic on the aggregate switch by two thirds when compared to no caching. More importantly, a suboptimal placement policy such as first fit which in this instance places the VNF on NFVI A can cost more to the network when compared with no caching, this is due to the VNF being pushed but and the content to being requested over the aggregate switch.