The major contributors of this repository include Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, and Yichen Wei.
Deep Feature Flow is initially described in a CVPR 2017 paper. It provides a simple, fast, accurate, and end-to-end framework for video recognition (e.g., object detection and semantic segmentation in videos). It is worth noting that:
- Deep Feature Flow significantly speeds up video recognition by applying the heavy-weight image recognition network (e.g., ResNet-101) on sparse key frames, and propagating the recognition outputs (feature maps) to the other frames by the light-weight flow network (e.g., FlowNet).
- The entire system is end-to-end trained for the task of video recognition, which is vital for improving the recognition accuracy. Directly adopting state-of-the-art flow estimation methods without end-to-end training would deliver noticable worse results.
- Deep Feature Flow can easily make use of sparsely annotated video recognition datasets, where only a small portion of the frames are annotated with ground-truth labels.
Click image to watch our demo video
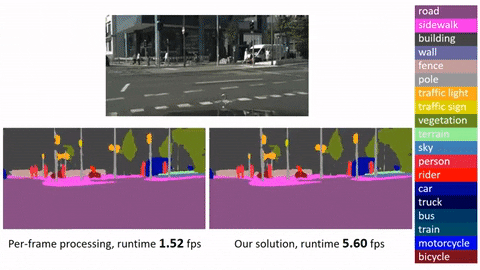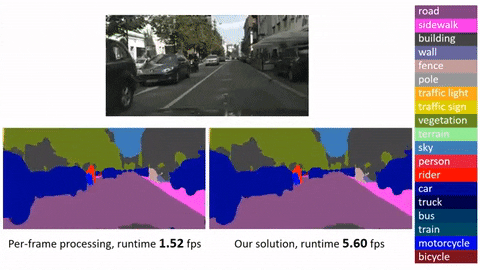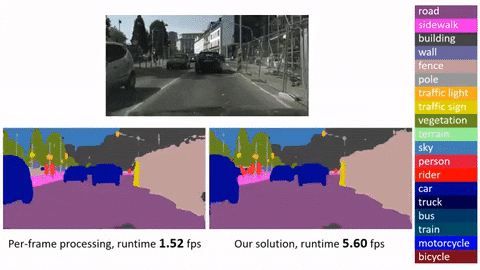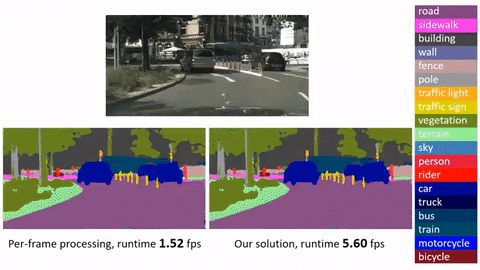

This is an official implementation for Deep Feature Flow for Video Recognition (DFF) based on MXNet. It is worth noticing that:
- The original implementation is based on our internal Caffe version on Windows. There are slight differences in the final accuracy and running time due to the plenty details in platform switch.
- The code is tested on official MXNet@(commit 62ecb60) with the extra operators for Deep Feature Flow.
- We trained our model based on the ImageNet pre-trained ResNet-v1-101 model and Flying Chairs pre-trained FlowNet model using a model converter. The converted ResNet-v1-101 model produces slightly lower accuracy (Top-1 Error on ImageNet val: 24.0% v.s. 23.6%).
- This repository used code from MXNet rcnn example and mx-rfcn.
© Microsoft, 2017. Licensed under an Apache-2.0 license.
If you find Deep Feature Flow useful in your research, please consider citing:
@inproceedings{zhu17dff,
Author = {Xizhou Zhu, Yuwen Xiong, Jifeng Dai, Lu Yuan, Yichen Wei},
Title = {Deep Feature Flow for Video Recognition},
Conference = {CVPR},
Year = {2017}
}
@inproceedings{dai16rfcn,
Author = {Jifeng Dai, Yi Li, Kaiming He, Jian Sun},
Title = {{R-FCN}: Object Detection via Region-based Fully Convolutional Networks},
Conference = {NIPS},
Year = {2016}
}
| training data | testing data | mAP@0.5 | time/image (Tesla K40) |
time/image (Maxwell Titan X) |
|
|---|---|---|---|---|---|
| Frame baseline (R-FCN, ResNet-v1-101) |
ImageNet DET train + VID train | ImageNet VID validation | 74.1 | 0.271s | 0.133s |
| Deep Feature Flow (R-FCN, ResNet-v1-101, FlowNet) |
ImageNet DET train + VID train | ImageNet VID validation | 73.0 | 0.073s | 0.034s |
Running time is counted on a single GPU (mini-batch size is 1 in inference, key-frame duration length for Deep Feature Flow is 10).
The runtime of the light-weight FlowNet seems to be a bit slower on MXNet than that on Caffe.
-
MXNet from the offical repository. We tested our code on MXNet@(commit 62ecb60). Due to the rapid development of MXNet, it is recommended to checkout this version if you encounter any issues. We may maintain this repository periodically if MXNet adds important feature in future release.
-
Python 2.7. We recommend using Anaconda2 as it already includes many common packages. We do not suppoort Python 3 yet, if you want to use Python 3 you need to modify the code to make it work.
-
Python packages might missing: cython, opencv-python >= 3.2.0, easydict. If
pipis set up on your system, those packages should be able to be fetched and installed by runningpip install Cython pip install opencv-python==3.2.0.6 pip install easydict==1.6 -
For Windows users, Visual Studio 2015 is needed to compile cython module.
Any NVIDIA GPUs with at least 6GB memory should be OK
- Clone the Deep Feature Flow repository, and we'll call the directory that you cloned Deep-Feature-Flow as ${DFF_ROOT}.
git clone https://github.com/msracver/Deep-Feature-Flow.git
-
For Windows users, run
cmd .\init.bat. For Linux user, runsh ./init.sh. The scripts will build cython module automatically and create some folders. -
Install MXNet:
3.1 Clone MXNet and checkout to MXNet@(commit 62ecb60) by
git clone --recursive https://github.com/dmlc/mxnet.git git checkout 62ecb60 git submodule update3.2 Copy operators in
$(DFF_ROOT)/dff_rfcn/operator_cxxor$(DFF_ROOT)/rfcn/operator_cxxto$(YOUR_MXNET_FOLDER)/src/operator/contribbycp -r $(DFF_ROOT)/dff_rfcn/operator_cxx/* $(MXNET_ROOT)/src/operator/contrib/3.3 Compile MXNet
cd ${MXNET_ROOT} make -j43.4 Install the MXNet Python binding by
Note: If you will actively switch between different versions of MXNet, please follow 3.5 instead of 3.4
cd python sudo python setup.py install3.5 For advanced users, you may put your Python packge into
./external/mxnet/$(YOUR_MXNET_PACKAGE), and modifyMXNET_VERSIONin./experiments/dff_rfcn/cfgs/*.yamlto$(YOUR_MXNET_PACKAGE). Thus you can switch among different versions of MXNet quickly.
-
To run the demo with our trained model (on ImageNet DET + VID train), please download the model manually from OneDrive, and put it under folder
model/.Make sure it looks like this:
./model/rfcn_vid-0000.params ./model/rfcn_dff_flownet_vid-0000.params -
Run (inference batch size = 1)
python ./rfcn/demo.py python ./dff_rfcn/demo.pyor run (inference batch size = 10)
python ./rfcn/demo_batch.py python ./dff_rfcn/demo_batch.py
-
Please download ILSVRC2015 DET and ILSVRC2015 VID dataset, and make sure it looks like this:
./data/ILSVRC2015/ ./data/ILSVRC2015/Annotations/DET ./data/ILSVRC2015/Annotations/VID ./data/ILSVRC2015/Data/DET ./data/ILSVRC2015/Data/VID ./data/ILSVRC2015/ImageSets -
Please download ImageNet pre-trained ResNet-v1-101 model and Flying-Chairs pre-trained FlowNet model manually from OneDrive, and put it under folder
./model. Make sure it looks like this:./model/pretrained_model/resnet_v1_101-0000.params ./model/pretrained_model/flownet-0000.params
-
All of our experiment settings (GPU #, dataset, etc.) are kept in yaml config files at folder
./experiments/{rfcn/dff_rfcn}/cfgs. -
Two config files have been provided so far, namely, Frame baseline with R-FCN and Deep Feature Flow with R-FCN for ImageNet VID. We use 4 GPUs to train models on ImageNet VID.
-
To perform experiments, run the python script with the corresponding config file as input. For example, to train and test Deep Feature Flow with R-FCN, use the following command
python experiments/dff_rfcn/dff_rfcn_end2end_train_test.py --cfg experiments/dff_rfcn/cfgs/resnet_v1_101_flownet_imagenet_vid_rfcn_end2end_ohem.yamlA cache folder would be created automatically to save the model and the log under
output/dff_rfcn/imagenet_vid/. -
Please find more details in config files and in our code.
Code has been tested under:
- Ubuntu 14.04 with a Maxwell Titan X GPU and Intel Xeon CPU E5-2620 v2 @ 2.10GHz
- Windows Server 2012 R2 with 8 K40 GPUs and Intel Xeon CPU E5-2650 v2 @ 2.60GHz
- Windows Server 2012 R2 with 4 Pascal Titan X GPUs and Intel Xeon CPU E5-2650 v4 @ 2.30GHz
Q: It says AttributeError: 'module' object has no attribute 'MultiProposal'.
A: This is because either
-
you forget to copy the operators to your MXNet folder
-
or you copy to the wrong path
-
or you forget to re-compile and install
-
or you install the wrong MXNet
Please print
mxnet.__path__to make sure you use correct MXNet
Q: I encounter segment fault at the beginning.
A: A compatibility issue has been identified between MXNet and opencv-python 3.0+. We suggest that you always import cv2 first before import mxnet in the entry script.
Q: I find the training speed becomes slower when training for a long time.
A: It has been identified that MXNet on Windows has this problem. So we recommend to run this program on Linux. You could also stop it and resume the training process to regain the training speed if you encounter this problem.
Q: Can you share your caffe implementation?
A: Due to several reasons (code is based on a old, internal Caffe, port to public Caffe needs extra work, time limit, etc.). We do not plan to release our Caffe code. Since a warping layer is easy to implement, anyone who wish to do it is welcome to make a pull request.