在这里强调下主要要是采用 Tensorflow2.0的api进行建立model
TensorFlow2.0,Keras, Python3.6, NumPy, sk-learn, Pandas
This dataset Contains about 45 million records. There are 13 features taking integer values (mostly count features) and 26 categorical features. The dataset is available at http://labs.criteo.com/2014/02/download-kaggle-display-advertising-challenge-dataset/
在这里我截取一部分数据进行模型训练 data =../data/Criteo/train.txt
In the train and test data, features that belong to similar groupings are tagged as such in the feature names (e.g., ind, reg, car, calc). In addition, feature names include the postfix bin to indicate binary features and cat to indicate categorical features. Features without these designations are either continuous or ordinal. Values of -1 indicate that the feature was missing from the observation. The target columns signifies whether or not a claim was filed for that policy holder.
The dataset is available at https://www.kaggle.com/c/porto-seguro-safe-driver-prediction
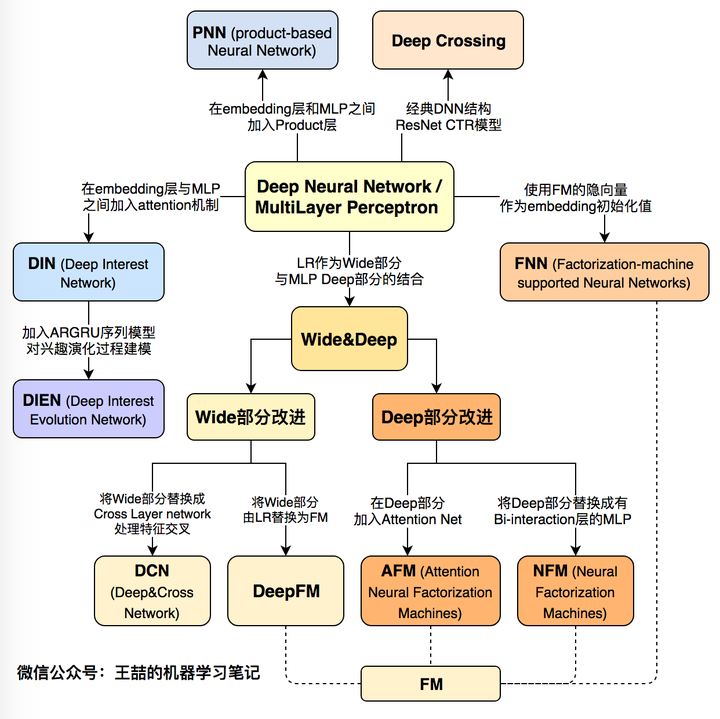
本质上GBDT+LR是一种具有stacking**的二分类,所以用来解决二分类问题,这个方法出自于Facebook 2014年的论文 Practical Lessons from Predicting Clicks on Ads at Facebook 。 https://zhuanlan.zhihu.com/p/29053940
算法简单实现 我们这里只是简单实现一个tensorflow版本的MLR模型 https://www.jianshu.com/p/627fc0d755b2
Deep Cross Network模型
https://www.jianshu.com/p/77719fc252fa
https://github.com/Nirvanada/Deep-and-Cross-Keras
https://blog.csdn.net/roguesir/article/details/797632
https://arxiv.org/abs/1708.05123
https://github.com/JianzhouZhan/Awesome-RecSystem-Models
https://github.com/Snail110/tensorflow_practice/blob/master/recommendation/Basic-PNN-Demo/PNN.py
https://www.jianshu.com/p/be784ab4abc2
https://zhuanlan.zhihu.com/p/92279796
https://github.com/busesese/Wide_Deep_Model
https://zhuanlan.zhihu.com/p/37522285 Neural Factorization Machines for Sparse Predictive Analytics