Chih-Yao Ma, Min-Hung Chen
(equal contribution)
Codes for the paper:
TS-LSTM and Temporal-Inception: Exploiting Spatiotemporal Dynamics for Activity Recognition
Project:
Activity Recognition with RNN and Temporal-ConvNet
In this work, we demonstrate a strong baseline two-stream ConvNet using ResNet-101. We use this baseline to thoroughly examine the use of both RNNs and Temporal-ConvNets for extracting spatiotemporal information. Building upon our experimental results, we then propose and investigate two different networks to further integrate spatiotemporal information: 1) temporal segment RNN and 2) Inception-style Temporal-ConvNet.
Our analysis identifies specific limitations for each method that could form the basis of future work. Our experimental results on UCF101 and HMDB51 datasets achieve state-of-the-art performances, 94.1% and 69.0%, respectively, without requiring extensive temporal augmentation.

The GIFs demonstrate the top-3 predictions results of our TS-LSTM and Temporal-Inception methods. The text on the top is the ground truth, three texts are the predictions for each of the method, and the bar right next to the predictions are how confident the model makes predictions.


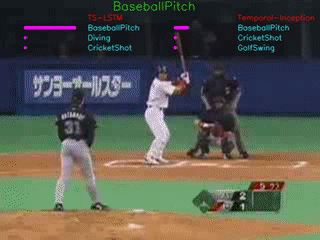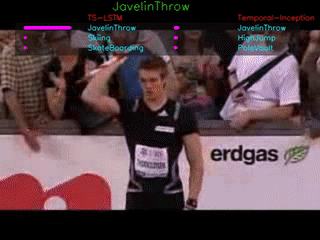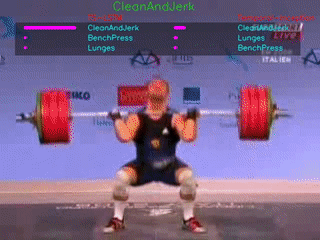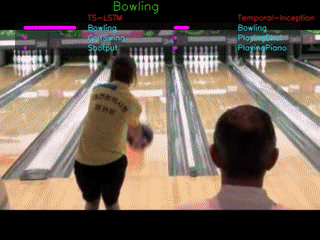



We are currently using UCF101 and HMDB51 dataset for our project.
- Linux (tested on Ubuntu 14.04)
- Torch
- CUDA and cuDNN
- NVIDIA GPU is strongly recommended
- torch-pastalog to visualize training status
We proposed two different methods to train the models for activity recognition: TS-LSTM and Temporal-Inception.
Our models takes the feature vectors generated by the first stage two-stream ConvNet as input for training. You can generate the features using our codes under "/CNN-Pred-Feat/". You can also download the feature vectors generated by us. (please refer to the Dropbox link below.) We followed the training/testing splits from UCF101 and HMDB51. If you would like to compare with our results, please use the same training and testing list, as it will affect your overall performance a lot.
- Features for training:
| UCF101 | HMDB51 | |
|---|---|---|
| RGB | sp1 sp2 sp3 | sp1 sp2 sp3 |
| TV-L1 | sp1 sp2 sp3 | sp1 sp2 sp3 |
- Features for testing:
| UCF101 | HMDB51 | |
|---|---|---|
| RGB | sp1 sp2 sp3 | sp1 sp2 sp3 |
| TV-L1 | sp1 sp2 sp3 | sp1 sp2 sp3 |
We use the RNN library provided by Element-Research. Simply install it by:
$ luarocks install rnnAfter you downloaded the feature vectors, please modify the code in ./RNN/data-ucf101.lua to the director where you put your feature vector files.
To start the training process, go to ./RNN and simply execute:
$ th main.lua -pastalogName 'model_RNN' -nGPU 1 -dataset 'ucf101' -split '1' -fcSize '{0}' -hiddenSize '{512}' -lstm -spatFeatDir '<path/to/feature/>' -tempFeatDir '<path/to/feature/>'The training and testing loss will be reported, and the results will be saved into log files. The learning rate and best testing accuracy will be reported each epoch if there is any update.
To start the training process, go to ./Temporal-ConvNet and simply execute:
$ th run.lua -o <output_folder_name> --dataset <dataset-name>For more details and hyper-parameter tuning, please refer to the readme file in the folder ./Temporal-ConvNet/.
You also need to modify the code in ./Temporal-ConvNet/data-2Stream.lua to the director where you put your feature vector files.
The training and testing performance will be plotted, and the results will be saved into log files. The best testing accuracy will be reported each epoch if there is any update.
To standardize the comparison, the above features are equally sampled across each video. If you would like to train with frame-level features extracted at 25fps for all videos in UCF101. Please refer to Temporal Augmentation using frame-level features with RNN.
@article{ma2017tslstm,
title={TS-LSTM and Temporal-Inception: Exploiting Spatiotemporal Dynamics for Activity Recognition},
author={Ma, Chih-Yao and Chen, Min-Hung and Kira, Zsolt and AlRegib, Ghassan},
journal={arXiv preprint arXiv:1703.10667},
year={2017}
}
This work was initialized as a class project for deep learning class in Georgia Tech 2016 Spring. We were teamed up with Hao Yan and Casey Battaglino to work on this class project, who have been a great help and provide valuable discussions as we go long this class project.
Chih-Yao Ma at cyma@gatech.edu or [LinkedIn]
Min-Hung Chen at cmhungsteve@gatech.edu