Skin Deep: Investigating Subjectivity in Skin Tone Annotations for Computer Vision Benchmark Datasets
Supplemental repository of code and data related to our paper Skin Deep: Investigating Subjectivity in Skin Tone Annotations for Computer Vision Benchmark Datasets from FAccT '23.
Authors: Teanna Barrett, Quan Ze Chen, Amy X. Zhang
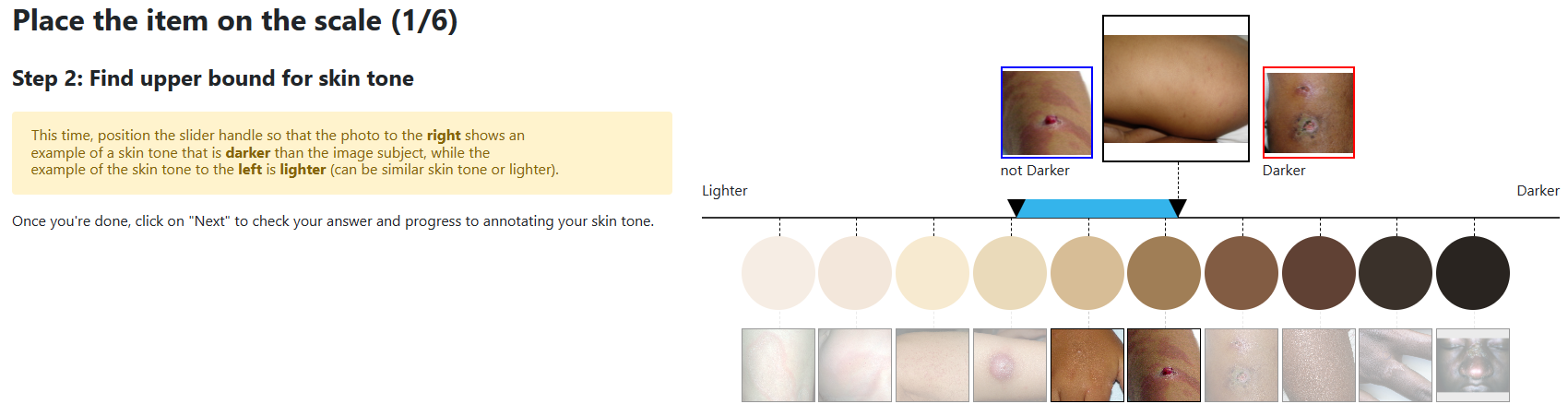
Our work is the first to investigate the skin tone annotation process as a sociotechnical project. We surveyed recent skin tone annotation procedures and conducted annotation experiments to examine how subjective understandings of skin tone are embedded in skin tone annotation procedures.
- Our systematic literature review revealed the uninterrogated association between skin tone and race and the limited effort to analyze annotator uncertainty in current procedures for skin tone annotation in computer vision evaluation.
- Our experiments demonstrated that design decisions in the annotation procedure such as the order in which the skin tone scale is presented or additional context in the image (i.e., presence of a face) significantly affected the resulting inter-annotator agreement and individual uncertainty of skin tone annotations.
This repostory contains the results of our literature review, the data used as input in our annotation experiments, our code for conducting the annotations, and the data produced by the crowd and non-crowd recruitments (anonymized)
To cite our work, please refer to CITATION.cff or use the following:
@inproceedings{10.1145/3593013.3594114,
author = {Barrett, Teanna and Chen, Quan Ze and Zhang, Amy X.},
title = {Skin Deep: Investigating Subjectivity in Skin Tone Annotations for Computer Vision Benchmark Datasets},
year = {2023},
isbn = {979-8-4007-0192-4/23/06},
publisher = {Association for Computing Machinery},
address = {Chicago, IL, USA},
doi = {10.1145/3593013.3594114},
booktitle = {2023 ACM Conference on Fairness, Accountability, and Transparency},
pages = {},
numpages = {15},
keywords = {skin tone annotation, model evaluation, fairness benchmark datasets, facial recognition, computer vision},
location = {Chicago, IL, USA},
series = {FAccT '23}
}There are 3 main components:
./study_data: (Anonymized) Output data of the annotation study./study_images: Input (images and configuration) of the annotation study./code: Code used for study (both MTurk and non-crowd recruitment)./Literature Review.csv: Results from literature review
Please read this file inside the code directory.