LDES in Solid Semantic Observations Replay
Data streams are becoming omnipresent and are a crucial component in many use cases. Storing streams in a low-cost file-based web environment could be done using Linked Data Event Streams (LDES). However, pushing large volumes of high volatile data into a Solid-based LDES is still not possible due to the way current solution do the partitioning of the data, i.e. after all data has been retrieved, instead of in a streaming fashion. The former crashes the Solid server due to the high load on the server when repartitioning large amounts of data. Data from the DAHCC dataset will be used for purpose, which contains data streams describing the behaviour of various patients. The streams contain over 100.000 events.
As many applications are using data streams, a way to easily replay captured streams is necessary for demoing purposes, scalability testing or data recovery. Replaying allows to mimic the real-time behaviour of data streams, even though the data is historical data. A replayer is a crucial component to showcase how our solutions can process live data streams and how they can handle different data rates. The DAHCC dataset will be used as example to replay the data.
- Run an LDES-enabled CSS, capable of processing LDES metadata via
docker run --rm -p 3000:3000 -it solidproject/community-server:latest -c config/default.json
- Navigate to the folder
engineviacd engine - Edit the properties file
src/config/replay_properties.json. You find information about this file below. You find sample datasets from the DAHCC project at https://dahcc.idlab.ugent.be/dataset.html. In order to build a connected care application, we need to get a good view of the daily activities and lifestyle of the person being monitored at home. Therefore, one of the aims of this project was to collect activity/lifestyle data based on the available sensor data in an ambient house, e.g. sensors for location, movement, light, temperature, the use of certain devices, etc. together with sensors on the monitored people themselves, e.g. wearables or sensors on a smartphone. In addition, sensors are also provided to measure the participants' condition, e.g. blood pressure or weight. The data collection is performed in the IDLab Homelab. In total: 31 "day in life" participants and 12 "night" participants enrolled in this study. More information on all used equipment, mobile applications and Homelab sensors can be found at https://dahcc.idlab.ugent.be/method.html". Typically, one wants to download a Knowledge Graph from a single participant for a given pod. Place the downloaded, and unzipped, file in the folder as specified by the propertydatasetFolders(see further). - Install the required dependencies via
npm i
- Start the engine with the command in the engine root folder via
npm start
The output should look similar to the following:
> challenge-16---replay---backend---typescript@1.0.0 start
> tsc && node dist/app.js`
{port: [Getter], loglevel: [Getter], logname: [Getter], datasetFolders: [Getter], credentialsFileName: [Getter], lilURL: [Getter], treePath: [Getter], chunkSize: [Getter], bucketSize: [Getter], targetResourceSize: [Getter], default: {port: '3001', loglevel: 'info', logname: 'WEB API', datasetFolders: C:\\nextcloud\\development\\challenge16-replay\\main\\Challenge 16 - Replay - Backend - Typescript\\data', credentialsFileName: null, lilURL: 'http://localhost:3000/test/', treePath: 'https://saref.etsi.org/core/hasTimestamp', chunkSize: 10, bucketSize: 10, targetResourceSize: 1024}}
2022-12-08T14:58:54.612Z [WEB API] info: Express is listening at http://localhost:3001Below you find more information properties used in the replay_properties.json file:
- "port": "3001" ==> The port on which the engine should be running,
- "loglevel": "info" ==> Configuration of the amount of logging,
- "logname": "WEB API" ==> Name of the logger,
- "datasetFolders": "" ==> Server-side path where the data is stored that can be potentially replayed, e.g.
/home/data/, - "credentialsFileName": null ==> Authentication as per Solid CSS Specification,
- "lilURL": "http://localhost:3000/test/" ==> URI of the LDES to be created,
- "treePath": "https://saref.etsi.org/core/hasTimestamp" ==> The (ordered) property according wo which the observations are to be streamed into the LDES,
- "chunkSize": 10 ==> For visualisation purposes, defines how many of the Observations are to be displayed when requested by the webapp (support parameter),
- "bucketSize": 10 ==> How many observations should be contained in a single bucket of the LDES,
- "targetResourceSize": 1024 ==> Target size of the resources on disk, this is a rough estimate and belongs to the Solid Event Sourcing implementation (https://github.com/woutslabbinck/SolidEventSourcing).
-
Get all loadable datasets using a GET request via
curl http://localhost:3001/datasets
You get something like
["dataset_participant1_100obs","dataset_participant2_100obs"]
-
Load a particular dataset using a GET request via
curl http://localhost:3001/loadDataset?dataset=dataset_participant1_100obs ==>
You get an empty result.
-
Check the loading progress (in quad count) using a GET request via
curl http://localhost:3001/checkLoadingSize
You get something like
[500]
-
Get the actual observation count (quads / observation) using a GET request via
curl http://localhost:3001/checkObservationCount
You get something like
[100]
-
Sort the loaded observations (as according to the configured TreePath) using a GET request via
curl http://localhost:3001/sortObservations
You get something like
[["https://dahcc.idlab.ugent.be/Protego/_participant1/obs0","https://dahcc.idlab.ugent.be/Protego/_participant1/obs1","https://dahcc.idlab.ugent.be/Protego/_participant1/obs2" ... ]]
-
Get a sample (as in the configured chunk) set of observations using a GET request via
curl http://localhost:3001/getObservations
You get something like
[{"termType":"NamedNode","value":"https://dahcc.idlab.ugent.be/Protego/_participant1/obs0"},{"termType":"NamedNode","value":"https://dahcc.idlab.ugent.be/Protego/_participant1/obs1"} ...}] -
Replay one next observation using a GET request via
curl http://localhost:3001/advanceAndPushObservationPointer
You get something like
[1]
This represents the pointer to the next replayable observation. Checking the LDES in the Solid Pod (default: http://localhost:3000/test/), you should see at least two containers (the inbox and the LDES buckets), where the LDES buckets should now contain the replayed observation, e.g. http://localhost:3000/test/1641197095000/aa28a2fa-010f-4b81-8f3c-a57f45e13758.
-
Replay all remaining observations using a GET request via
curl http://localhost:3001/advanceAndPushObservationPointerToTheEnd
-
Install the required dependencies via
npm i
-
Start the Web app in Vue.js with the command in the Web app root folder via
npm run dev
The output should look similar to the following:
> challenge-16---replay@0.0.0 dev > vite VITE v3.0.9 ready in 6083 ms ➜ Local: http://127.0.0.1:5173/ ➜ Network: use --host to expose
-
The Web app can then be accessed using your browser by navigating to the aforementioned URL. This should guide you to the front-end, similar to the picture below:
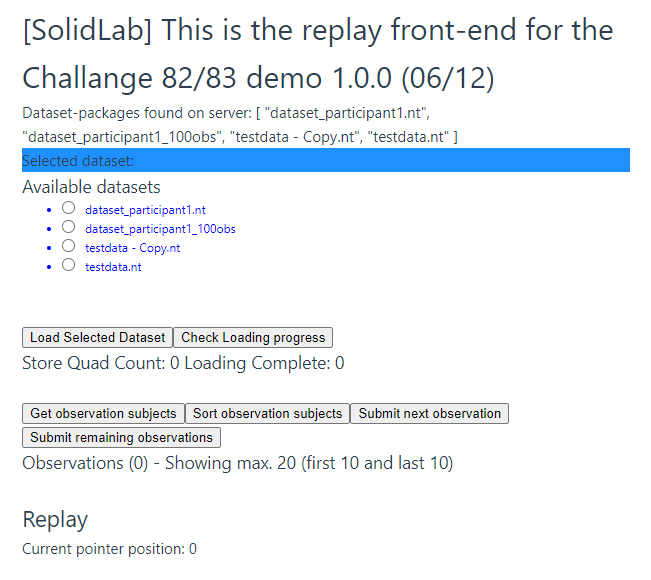
-
Select the required dataset to be replayed into an LDES in Solid pod, e.g.
dataset_participant1_100obswhich holds 100 observations from the DAHCC dataset generated by Patricipant1. -
Click
Load Selected Dataset. -
Wait for the dataset to be loaded into the engine. The Web page should change into something like in the picture below:
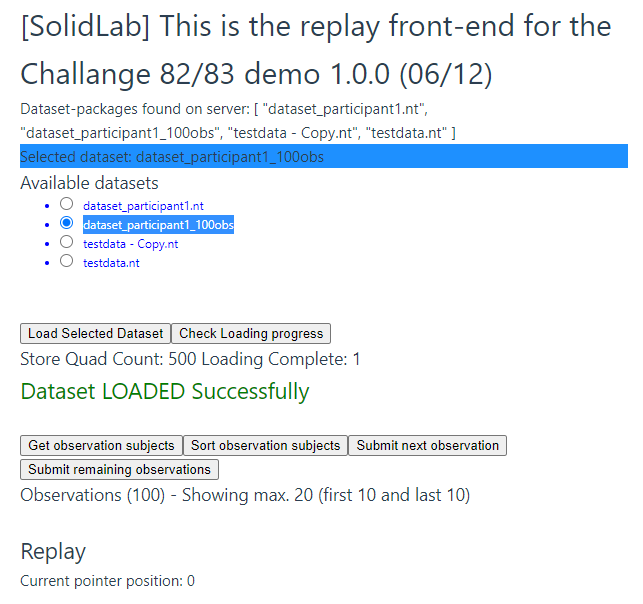
-
Sort the observation per timestamp by clicking on the
Sort observation subjectsbutton. A status indicator for the progress of the sorting is not yet provided. -
In case desired, a sample of the loaded subjects can be retrieved by clicking on the
Get observation resultsbutton. You should get something similar to:
-
Now you can submit the first observation to be replayed into the LDES in Solid pod, by clicking on the
Submit next observationbutton. You should see theCurrent pointer positionvariable at the bottom of the screen increase by one. This indicates that the observation was submitted, and that the pointer in the by timestamp sorted replay dataset is moved forward. -
This can be repeated, resulting in more observation being submitted and resulting in the pointer ever moving forward.
-
Alternatively, the remainder of the dataset can be replayed in one go from the current pointer onwards until the end of the dataset, by clicking on
Submit remaining observations. -
Mind that replay progress can always be checked directly in the CSS as well, e.g. by surfing to
http://localhost:3000/test/


A streaming Solid-based LDES connector that can partition the data in a streaming fashion, i.e. when retrieving the data instead of needing to wait till the whole dataset is received.
The replayer should be able to read a number of files, and stream out the events described in each file. To facility performance and scalability testing, the rates and number of streams should be configurable.
You find a screen below.
Video.mp4
A connector is required that investigates the LDES, computes the need for a new bucket and adds the events of the stream either to a new bucket or to an existing one based on the timestamps of these events. In more detail the following functionality is required:
- functionality to connect to and RDF stream, either pull or push based,
- investigation of the current LDES, i.e. do new buckets need to be created,
- if new buckets are required, the LDES itself needs to be updated,
- new events are added to the right bucket, and
- the bucket size should be parameterized.
The replayer should be a library that allows to:
- read multiple files or directory,
- stepwise replay,
- bulk replay until the end of the dataset,
- stream out the result, possible using multiple output streams (configurable),
- configure the replay frequency, i.e. how fast the events should be streamed out,
- configure burst in the replay frequency, i.e. a certain times the event rate rises drastically to mimic high load/usage periods,
- assign new timestamps to the replayed events(the property should be configurable),
- configure the event shape (to know which triples belong to each event), and
- optionally first map raw data, e.g. CSV, to RDF