This repository contains the implementation of a Data Mining project. The project is structured into multiple Parts across two phases, each focusing on different aspects of data preprocessing, quality assessment, analysis, and advanced data mining techniques. The main tasks performed in this project include:
- Dataset Understanding: Analyzing the features of the dataset and computing essential statistics such as mean, median, mode, min, max, and identifying outliers.
- Data Quality Assessment: Evaluating the quality of the dataset based on various dimensions such as consistency, currentness, validity, completeness, and accuracy.
- Data Preprocessing: Handling missing values, converting and normalizing data, engineering new features, removing outliers, and reducing data.
- Dataset Integration: Combining the primary dataset with an additional dataset to enhance the scope of analysis and gain deeper insights.
- Frequent Pattern Extraction: Identifying frequent itemsets and association rules within the dataset.
- Clustering and Classification: Applying clustering algorithms to group data and classification algorithms to predict outcomes.
The primary dataset (source_Playstore_final.csv - 450,794 records) contains detailed information about various apps available on the Google Play Store. This includes attributes such as app name, category, rating, installation statistics, pricing, developer information, and update history. This comprehensive dataset provides a rich source of data for performing various data mining tasks.
The additional dataset (GooglePlay.csv - 10,840 records) includes similar information about apps but in a slightly different format. It covers aspects such as app ratings, reviews, size, installation numbers, content rating, genres, and version details. This dataset complements the primary dataset and is used for integration and enhanced analysis.
The preprocessing and integration processes have been applied to the two original datasets, resulting in a new dataset (combined_df.csv).
- phase1:
- DataPreProcessing.ipynb
- phase2:
- part1:
- FrequentPatternExtraction.ipynb
- part2:
- Clustering.ipynb
- Classification.ipynb
- part1:
- Feature Analysis: For numerical data, the following statistics are computed:
- Mean
- Median
- Mode
- Min
- Max
- Outliers (using Box Plot)
- Outlier Detection: Identifying and handling outliers by plotting box plots for each feature.
- Quality Evaluation: Assessing the dataset quality based on the ISO 25012 data quality model, focusing on:
- Consistency
- Currentness
- Validity
- Completeness
- Accuracy
- Error Identification: Identifying missing values, inconsistencies, and other errors within the dataset and suggesting ways to handle them.
- Handling Missing Values: Using methods such as mean, median, mode, or regression to fill in missing values. Columns with excessive missing data may be removed.
- Data Conversion: Normalizing and converting data as needed.
- Feature Engineering: Creating new features by combining existing ones to enhance the dataset.
- Outlier Handling: Removing outliers from numerical data.
- Data Reduction: Applying techniques for data reduction if necessary.
- Categorical Data Handling: Converting numerical data to categorical data where appropriate.
- Text Data Processing: Performing operations like stemming, lemmatization, and removal of stopwords for text data.
- Combining Datasets: Integrating the current dataset with another larger dataset to enhance analysis.
- Column Matching and Merging: Ensuring compatibility of columns between the datasets and handling any discrepancies.
- Creating New Insights: Adding new columns by combining data from both datasets for deeper analysis.
-
Dataset Preparation:
- Using the cleaned dataset of previous phase, combined from Google Play and Play Store, joined on the "App Name" column.
-
Data Preprocessing:
- Applying binning techniques to convert numerical columns to categorical.
- Converting categorical data to appropriate formats for analysis.
-
Frequent Itemset Mining:
-
Utilizing the Apriori algorithm from the mlxtend library.
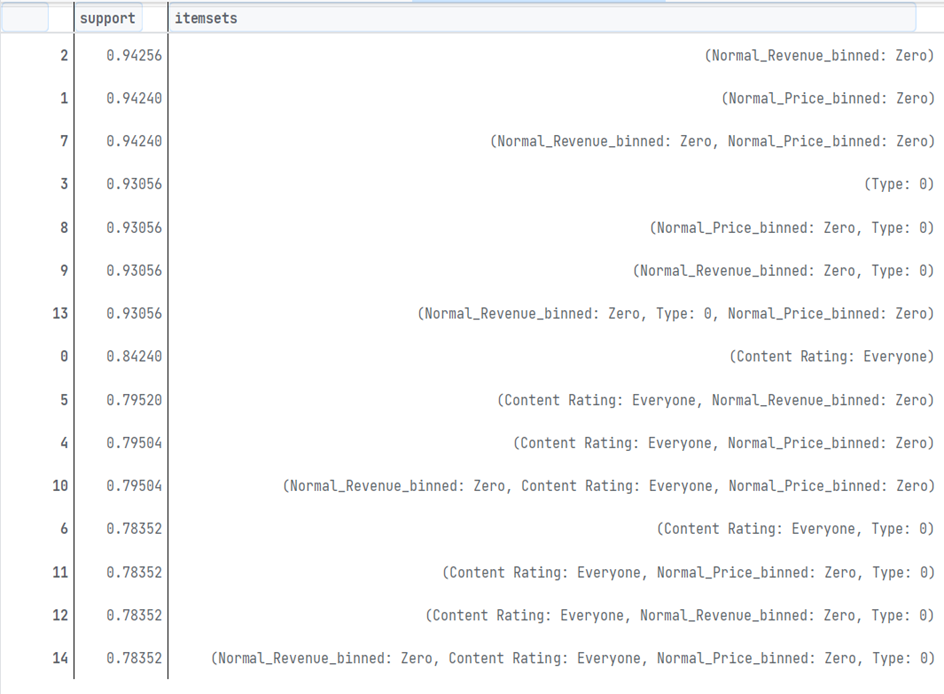
-
Identifying maximal itemsets from the frequent itemsets.

-
-
Association Rule Mining:
-
Extracting association rules from maximal itemsets with a confidence threshold of 0.7.
-
Analyzing the rules to uncover hidden patterns and relationships within the data.
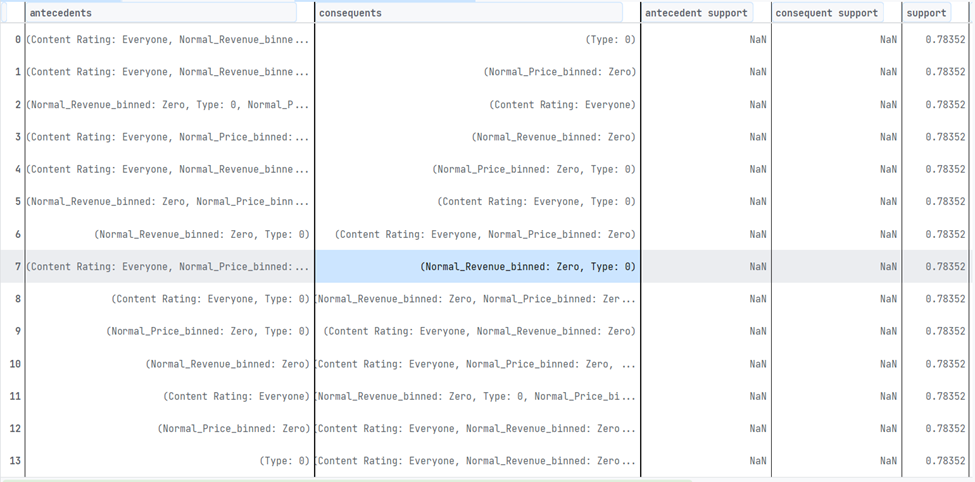
-



-
Clustering:
-
Implementing two unsupervised learning algorithms: K-means and DBSCAN.
-
Data Preparation:
- Selecting relevant numerical columns (Rating, Rating Count, Reviews, Size, Installs, Price, Revenue, popularity).
- Applying dynamic binning using the Freedman-Diaconis rule and static binning for comparison.
-
K-means Implementation:
-
Determining optimal K using the elbow method (testing K from 1 to 12).
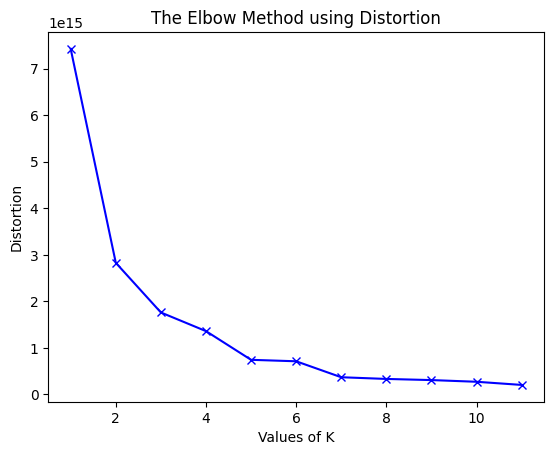
-
Visualizing clusters in 2D and 3D plots.
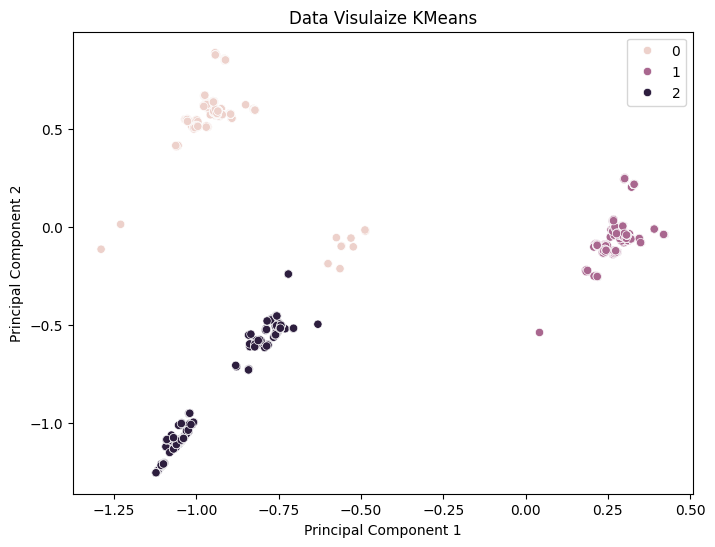
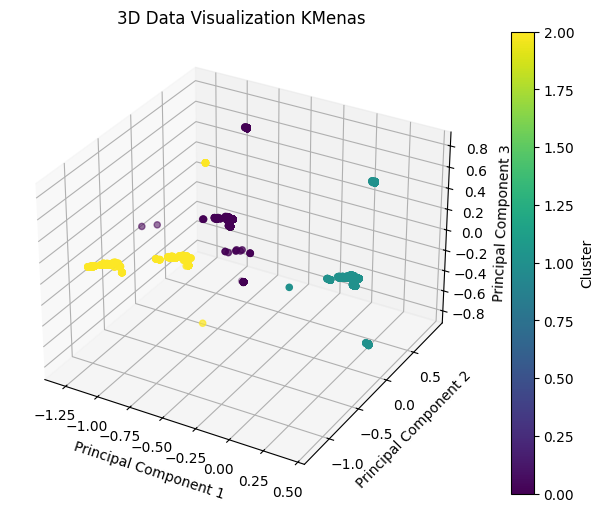
-
-
DBSCAN Implementation:
-
Applying DBSCAN algorithm to the preprocessed data.
-
Visualizing DBSCAN clusters in 2D and 3D plots.
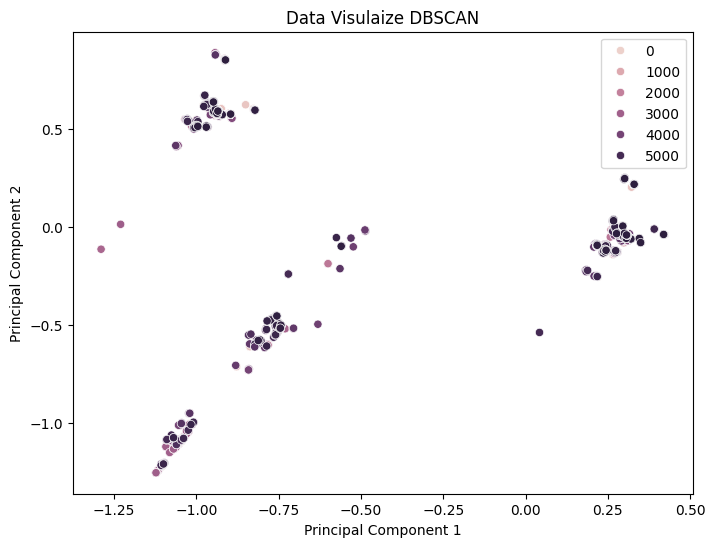
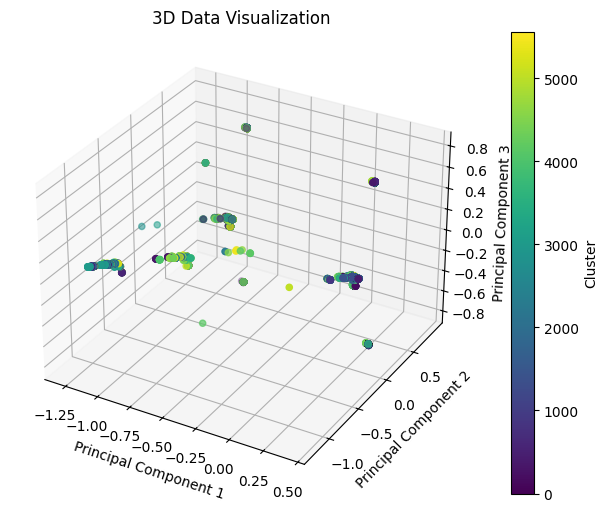
-
-
Pattern Analysis:
- Extracting frequent itemsets and association rules for each cluster to identify cluster-specific patterns.
-
-
Classification:
-
Objective: Predicting app ratings based on other features.
-
Feature Selection:
-
Using correlation matrix to identify relevant features for rating prediction.
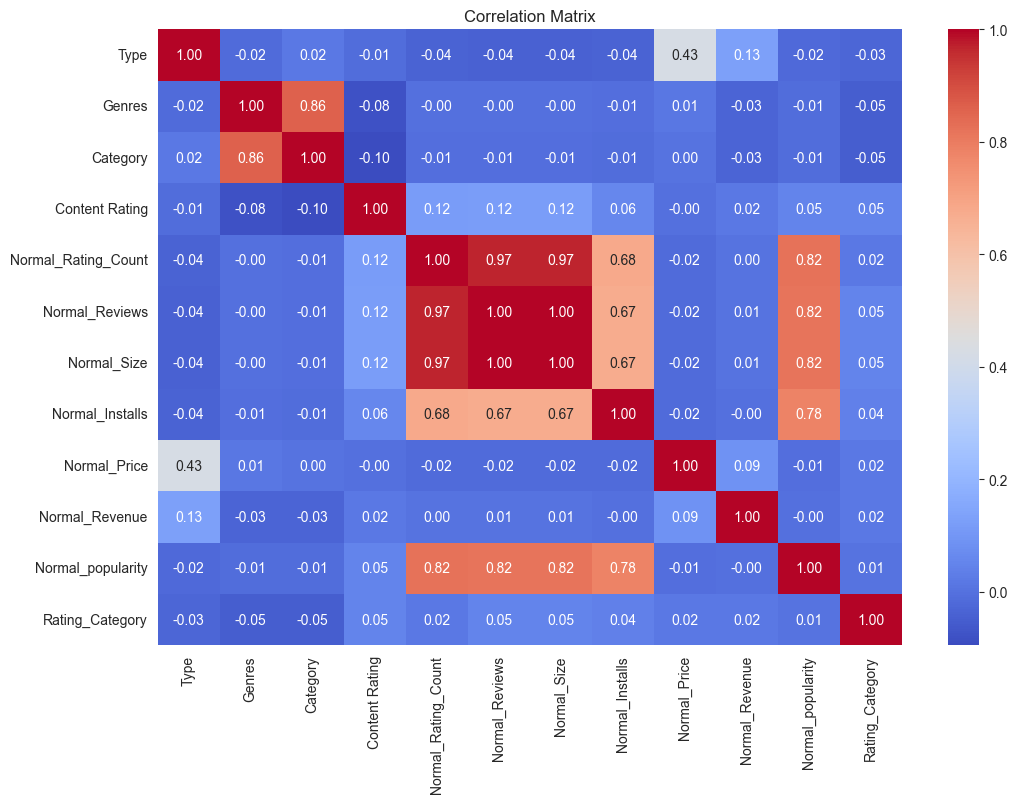
-
-
Data Preprocessing:
- Converting 'normal_rating' to ordinal categorical type.
- Splitting data into training and test sets.
- Scaling features for standardization.
-
Model Implementation:
-
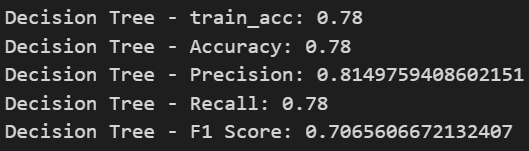
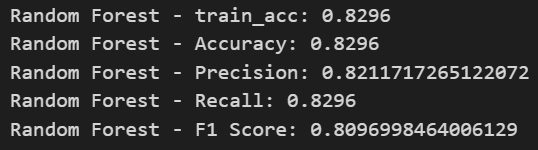
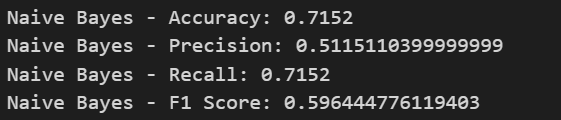
Implementing three classification models: Decision Tree, Random Forest, and Naive Bayes.
-
Performing hyperparameter tuning using Grid Search for each model.

-
-
Model Evaluation:
-
Using metrics such as Accuracy, Precision, Recall, and F1 Score.
-
Generating confusion matrices for each model.
-
-
Results:
- Random Forest performed best among the three models.
- Naive Bayes showed the lowest performance for this classification task.
-










The enhanced clustering and classification techniques provide deeper insights into app characteristics and their relationship with ratings, offering valuable information for app developers and marketers in the Google Play Store ecosystem.
- Python: Ensure you have Python installed (preferably Python 3.8 or higher).
- Jupyter Notebook: For running the
.ipynbfiles. - Libraries: Install the necessary Python libraries using the command below:
pip install -r requirements.txt
- Clone the repository:
git clone https://github.com/Soroush-Pasandideh/DataMining.git
- Navigate to the project directory:
cd DataMining - Open the Jupyter Notebook:
open the notebook related to the phase you want to execute.
jupyter notebook DataMining.ipynb
- Run the cells in the notebooks sequentially to perform the data mining tasks as outlined.
The notebooks contains detailed results of each Part, including visualizations, statistical analyses, data preprocessing and data mining steps. Ensure to go through the notebook for insights and understanding of the dataset.
The documentation of the implementation of Phase 2 is available in DataMining_Document_phase2.pdf.