在线demo ↑↑↑ bilibili demo
数据集无需任何情感标注,通过情感提取模型 提取语句情感embedding输入网络,实现情感可控的VITS合成。
如下所述,因本模型内所含speaker过多,故尚未实现对每个人物的精细情感聚类。
目前仅将各speaker的TTS Generate情感映射到了训练(验证)集,使之初步符合该speaker说话风格。
API正在开发。
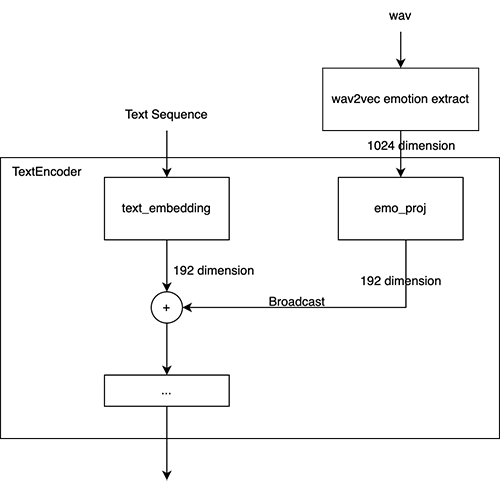
- 相对于原版VITS仅修改了TextEncoder部分

该模型缺点:
- 推理时需要指定一个音频作为情感的参考音频才能够合成音频,而模型本身并不知道“激动”、“平静”这类表示情绪的词语对应的情感特征是什么。
- 对于有多个角色的模型,预筛选的方式有局限性,因为例如同样对于“平静”这一个情感而言,不同角色对应的情感embedding可能会不同,导致建立情感文本->情感embedding的映射关系很繁琐,很难通过一套统一的标准去描述不同角色之间的相似情感。
- 如果仅对情感映射到训练(验证)集,可能最终效果并不比普通的VITS TTS效果好,因其抽取情感随机性过大使之难以随机到适合的情感语音。
- 一次性合成过长的语音音调会跑的很离谱。
- 部分角色数据集内语音情感分布过于均一,导致除陈述句外的效果均不好 (如:神里绫人)
该模型的优点:
- 任何普通的TTS数据集均可以完成情感控制。无需手动打情感标签。
- 对于只有一个角色的模型,可以通过预先筛选的方式,即手动挑选几条“激动”、“平静”、“小声”之类的音频,手动实现情感文本->情感embedding的对应关系 (这个过程可以用聚类算法简化筛选)
- 由于在训练时候并没有指定情感的文本与embedding的对应关系,所有的情感特征embedding均在一个连续的空间内
- 因此理论上对于任意角色数据集中出现的情感,推理时均可以通过该模型实现合成,只需要输入目标情感音频对应的embedding即可,而不会受到情感分类数量限制
可以使用 聚类算法 自动对音频的情感embedding进行分类,大致上可以区分出情感差异较大的各个类别,具体使用请参考 emotion_clustering.ipynb
- Python >= 3.6
- Clone this repository
- Install python requirements. Please refer requirements.txt
- prepare datasets
- Build Monotonic Alignment Search and run preprocessing if you use your own datasets.
# Cython-version Monotonoic Alignment Search
cd monotonic_align
python setup.py build_ext --inplace
# Preprocessing (g2p) for your own datasets. Preprocessed phonemes for nene have been already provided.
python preprocess.py --text_index 2 --filelists filelists/train.txt filelists/val.txt --text_cleaners japanese_cleaners
- extract emotional embeddings, this will generate *.emo.npy for each wav file.
python emotion_extract.py --filelists filelists/train.txt filelists/val.txt# nene
python train_ms.py -c configs/nene.json -m nene
# if you are fine tuning pretrained original VITS checkpoint ,
python train_ms.py -c configs/nene.json -m nene --ckptD /path/to/D_xxxx.pth --ckptG /path/to/G_xxxx.pth
See inference.ipynb or use MoeGoe