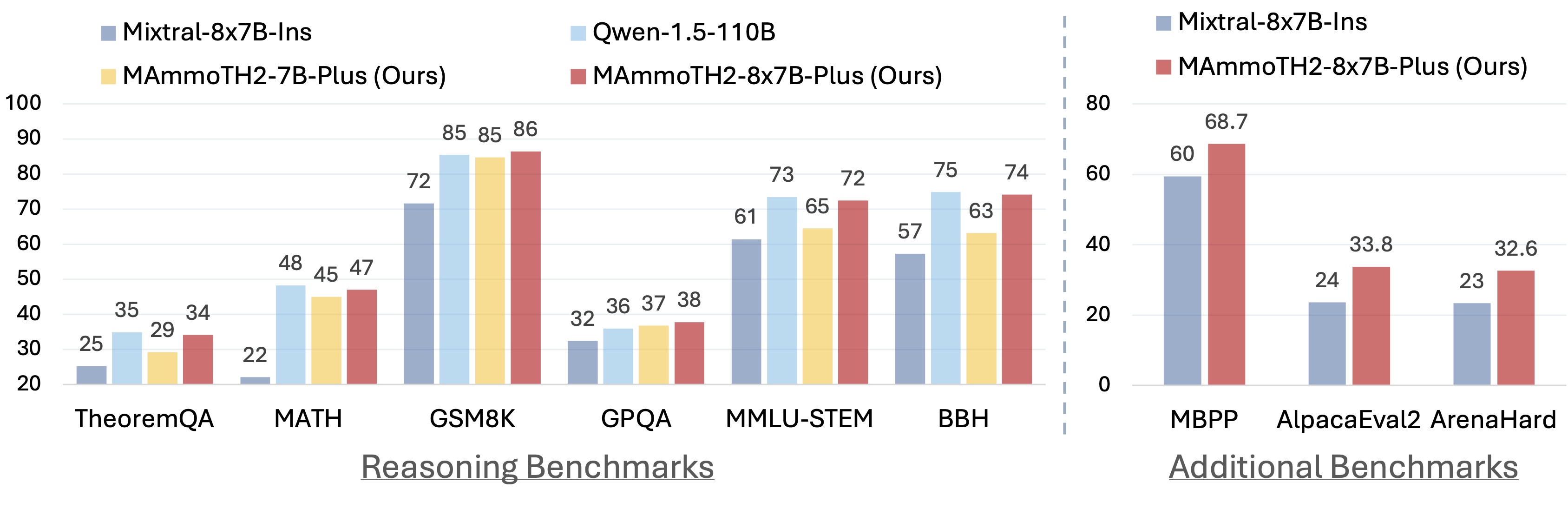
This repo contains the code, data, and models for NeurIPS-24 paper "MAmmoTH2: Scaling Instructions from the Web". Our paper proposes a new paradigm to scale up high-quality instruction data from the web.
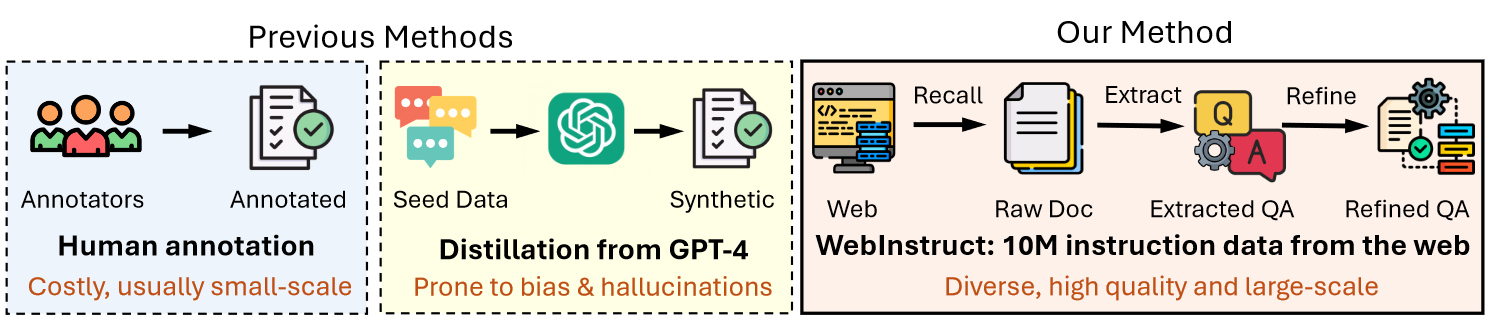
We propose discovering instruction data from the web. We argue that vast amounts of high-quality instruction data exist in the web corpus, spanning various domains like math and science. Our three-step pipeline involves recalling documents from Common Crawl, extracting Q-A pairs, and refining them for quality. This approach yields 10 million instruction-response pairs, offering a scalable alternative to existing datasets. We name our curated dataset as WebInstruct.
Part of our WebInstruct dataset has been released at 🤗 TIGER-Lab/WebInstructSub and 🤗 TIGER-Lab/WebInstructFull.
| Model | Dataset | Init Model | Download |
|---|---|---|---|
| MAmmoTH2-8x7B | WebInstruct | Mixtral-8x7B | 🤗 HuggingFace |
| MAmmoTH2-7B | WebInstruct | Mistral-7B-v0.2 | 🤗 HuggingFace |
| MAmmoTH2-8B | WebInstruct | Llama-3-base | 🤗 HuggingFace |
| MAmmoTH2-8x7B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-8x7B | 🤗 HuggingFace |
| MAmmoTH2-7B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-7B | 🤗 HuggingFace |
| MAmmoTH2-8B-Plus | WebInstruct + OpenHermes2.5 + CodeFeedback + Math-Plus | MAmmoTH2-8B | 🤗 HuggingFace |
Please refer to https://tiger-ai-lab.github.io/MAmmoTH2/ for more details.
Please refer to https://github.com/TIGER-AI-Lab/MAmmoTH2/tree/main/math_eval.
Please cite our paper if you use our data, model or code. Please also kindly cite the original dataset papers.
@article{yue2024mammoth2,
title={MAmmoTH2: Scaling Instructions from the Web},
author={Yue, Xiang and Zheng, Tuney and Zhang, Ge and Chen, Wenhu},
journal={arXiv preprint arXiv:2405.03548},
year={2024}
}