An attempt to convert natural language to sql statement
Input text -> Text processing will entirely depends upon the targeted domain or customer
Replace key words, such as total number with count or total with sum etc.
Remove stop words
Identify the text from pre-loaded entites
Input string processing using spacy
Identify noun chunks
Identify named entities
Create lemmatized string
Match the processed sentence with the existing columns and tables as well as synonyms defined in the configuration
Split the processed string using phrase splitter configuration (this again has to be domain specific)
Create spacy nlp documents for the splitted phrases
Find entities and columns
Find if any aggregation requires to be run on the entities and columns
Use Named entities identified earlier to correct the values
Buid the dictionary and pass the dictionary to SQL Generator
SQL generator (as of now is for SQL server only) will generate the query based on the entity-column dictionary
Push the query to database and fetch the result
Important part to focus here is configuration
{
"sql": {
"connection_string":""
},
"phrase_splitter": " in |in | in| and |and | and| with |with | with",
"default_columns": {
"entities": {
"student":"name",
"subject":"name",
"student_mark":"id"
}
},
"entities_to_load": [
{
"entity": "subject",
"column": "name"
},
{
"entity": "student",
"column": "name"
}
],
"synonyms": {
"column": [
{
"original": "class",
"synonyms": [ "standard" ]
}
],
"table": [
{
"original": "student",
"synonyms": [ "children", "child" ]
}
]
}
}
connection_string: connection string for the sql server
phrase_splitter: phrase splitter for the domain. Customer should know what sort of queries user generally ask and how these can be splitted
default_columns: define default columns for the tables. this will be helpful to identify the default column to select when entity is mentioned in the question
entities_to_load: which all entities to pre-load. These entities should refer to the master data or data which needs to be looked up without any context
synonyms: synonyms for table names and column names
Only sql server is supported as of now.
Following SQL functions - min, max, avg, sum, count
Multiple values for a filter is not supported.
python -B main.py
Go to browser and launch http://127.0.0.1:5000/
Tested on test schema
The schema basically consists of three tables Student, Subject and student_mark with relationship among them.
Test data is populated using data feed
Queries which are tested on the above schema
students in class 12 and mark 30 in english subject
Show all students with marks greater than 30
students in class 12 and marks less than 50 in english subject in year greater than 2018
students in class 12 and marks less than 50 in english subject
average marks of students in english subject in class 12
average marks in english subject in class 12
student with maximum marks in english subject in class 12
minimum marks in english subject in class 12
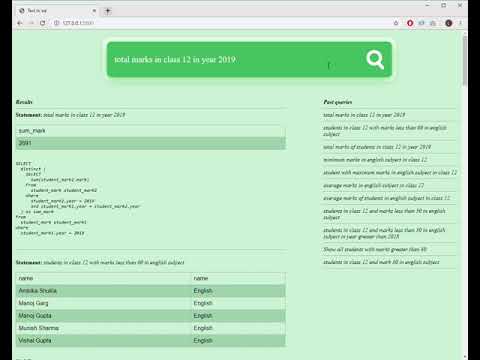
total marks of students in class 12 in year 2019
students in class 12 with marks less than 60 in english subject
total marks in class 12 in year 2019
maximum marks in class 12 in year 2019
students in class 12 and 69 marks in english subject
students in class 12 and marks less than 50 in english subject
marks of Manoj Garg student in english subject
student with biology in class 12
marks of Lokesh Lal in english in class 12
maximum marks of vishal gupta in all subject
students with less than 50 marks in class 12
Define a process to incoperate the ML based learning for various scenarios.
For example, "students with average marks less than average marks".
In the above query, we have to find all students with average marks less than the average marks of all students. This can be coded as well. However, there could be many scenarios and based on these scenarios we might not want to change the sql adaptor every time. So best is to leverage the ML model to enhance the dictionary which is being passed to the SQL adaptor and let SQL adaptor build the SQL based on the available sql functions.