
KNN,Decision Tree ve Ensemble Algoritmalarını kullanarak kategorik değişken sınıflandırılması yaptım.Modellerin önemli parametrelerini optimize ederek model için en iyi optimum değerler ile yeni modeler oluşturup bu modellerin başarılarını karşılaştırdık

-
İlk sınıflandırma yaptığımız algoritma, KNN algoritmasıdır.
-
Tahminler gözlem benerliğine göre yapılır.KNN algoritması sınıflandırma yaparken, sınıflandırma yapacağımız yeni verimizin çevresindeki en yakın , bizim belirlediğimiz k sınıf sayısının sıklığına göre sınıflandırma yapar.
-
Çevresindeki en yakın verileri bulabilmek için uzaklık hesabı yapar.Uzaklık hesabı yapmak için 3 tip uzaklık fonksiyonu kullanılır.Bunlar ;
- "Euclidean" Uzaklık
- "Manhattan" Uzaklık
- "Minkowski" Uzaklık
-
İlk olarak komşu sayısı(k değeri) belirlenir.KNN Algoritmamızda bu değerin belirlendiği parametre n_neighbors parametresidir.
-
Bilinmeyen nookta ile diğer tüm noktalar arasındak- ki uzaklık hesaplanır.(Yukarıdaki uzaklık hesabı ile). Algoritmamızda uzaklık hesabının belirtildiği parametre metric parametresidir.
-
Hesaplanan Uzaklıklar sıralanır ve belirlenen k sayısına göre en yakın(uzaklık hesabına göre) olan k gözlemi seçer
- Sınıflandırma yaparken ; En sık sınıf tahmin değeri olarak verilir
- Regresyon'da ; En yakında bulunan k kadar gözlemin ortalama Değeri tahmin değeri olarak verilir
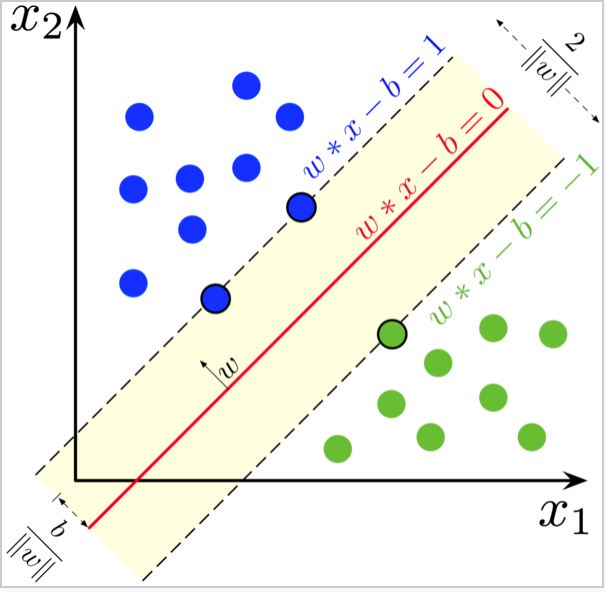
- Amacımız iki sınıf arasındaki marjinin maximum olmasını sağlayacak doğruyu ortaya çıkarmaya çalışmaktır
- SVM bizim için max marjin bulur
- Marjini max marjin yapacak iki point bizim support vektörümüzdür
- Support Vector Machine , Logistic Regression ile benzer bir sınıflandırma algoritmasıdır
- SVM , aynı zamanda "doğrusal" ve "doğrusal olmayan" verileride sınıflandırabilir ancak genellikle verileri doğrusal olarak sınıflandırmaya çalışır
- SVM , verileri doğrusal olarak sınıflandıramadiği zaman Kernel Trick(Çekirdek Hilesi) yöntemine ile bu durumu çözer.En çok kullanılan Kernel Trick;
- Polynomial Kernel: Problemi çözmek için 2 Boyuttan 3 Boyut ve daha fazla boyutta işlem yapıyormuş gibi çözüyoruz.Sınıflarımızı SVM ile doğrusal bir çizgi oluşturarak ayırabiliriz.
- Gaussian RBF Kernel: Her bir noktanın belirli bir noktaya benzerliğini Normal Dağılım ile hesaplar ve sınıflandırır.
-
Decision Tree algoritmasının amacı , veri seti içerisinde ki karmaşık yapıları basit karar yapılarına dönüştürmektir.
-
Datayı Split etmek (Ayırmak) çok önemlidir.Information Entropy'e göre datayı split ederiz.
- Entropi ; Belirli bir veri kümesinde ki düzensizliği ve dayanıklığı ölçen bir istatiksel metriktir.
- Veri Kümesinde ki düzensizliğin artması ile doğru orantılı olarak entropi değeri de artmaktadır.
-
Bir ağaç algoritmasıdır.
-
Karar Ağaçları ;
- Kök(Root)
- Düğümler(Nodes)
- Yapraklar(Leaf) ile oluşur.
-
İlk hücrelerine kök adı verilir.Her gözlem kökteki koşuala göre Evet veya Hayır olarak sınıflandırılır.
-
Kök hücrelerden sonra yani kök hücrelerin altında Düğümler gelir.Her bir gözlem düğümler yardımıyla sınıflandırılır.
- Düğüm Sayısı arttıkça Modelin Karmaşıklığı da artar.
-
Karar Ağaçlarının son hücresinde ise Yapraklar bulunur.Yapraklar bizim çıktılarımız, yani sonuçlarımızı verir.
-
Ağacın çok fazla dallanması örnek veri setinin çok iyi temsil edilmesini ifade eder.Fakat bu durum Overfitting'e yol açar.
-
Overfitting'i engellemek amacıyla ağacı budama işlemi ile tabir edilen karmaşıklık parametresi işlemi ile engelliyoruz.Belirli noktadan sonra bu dallanma işlemini durduruluyor.
-
Karmaşıklık Parametresi, Ceza parametresi(penalty) olarakta adlandırılır.
-
Her özellik için ayrı ayrı bilgi kazancı(Information Gain) hesaplanır.Daha sonra bilgi kazancı en yüksek olan kök olarak alınır.
-
Bu işlemler her düğüm için aşağıdaki durumlardan biri oluşuncaya kadar devam eder.
- Örneklerin hepsi aynı sınıfa ait
- Örnekleri bölecek özellik kalmaması
- Kalan özelliklerin değerlerini taşıyan örneğin olmaması
-
Ve bu adımlar tamamlanarak Karar Ağacı oluşturulmuş olur.
- Ensemble üyesidir.
- Çok güçlü bir algoritmalardır.Çünkü birçok farklı algoritmayı birleştiriyor.Random Forest'ta birden çok Decision Tree oluşturuyoruz.
- Random Forest'ta gözlemlerdeki rassallığı , gözlemlere de değişkenlere de uygulanarak hem gözlem seçiminde hem de değişken seçiminde rassallığı sağlayarak başarılı bir algoritma olmuştur
- Decision Tree en büyük problemlerinden biri "Aşırı öğrenme(Overfitting)" idi.
- Random Forest , bu problemi çözmek için veri setinden ve öznitelik setinde rassal olarak 100'lerce subdata'lar seçiyor ve bunları eğitiyor.Bu şekilde 100'lerce Karar Ağacı oluşturulmuş oluyor ve her bir Karar Ağacı Bireysel olarak tahminde bulunuyor.
- Regresyon'da ; Ağaçların tahminlerinin "Ortalamasını" verir
- Sınıflandırma'da ; Ağaçların tahminlerinin arasından En çok oy alanı bize verir.
- Makine Öğrenimindeki Topluluk Öğrenme(Ensemble Learning) modelleri , Genel performansı iyileştirmek için birden çok modelden oluşur ve her modelden alınan kararları birleştirir.
- Tekli modellere göre farklı modellerde daha iyi ve sağlıklı sonuçlar elde ederiz.
- Orjinal Veri Setinden subset(alt küme) oluştururuz.
- Bu alt kümelerin her birinden Model , Ağaçlar oluştururuz.
- Bu Modellerden Tahmin değerleri oluştururuz.
- Burada Ağaçlar birbirinden bağımsızdır.
- Varyansı düşüren , Overfitting'e karı dayanıklıb bir yöntemdir.
- Zayıf öğrenicileri bi araya getirip güçlü bi öğrenici ortaya çıkarır.
- Artıklar üzerine tek bir tahminsel model formunda olan Modeller, Ağaçlar oluştururuz.Seri içerisinde ki bir model seride ki bir önceki Ağacın(Modelin) tahmin Artıklarının(Residuals) üzerine kurularak oluşturulur.
- Burada Ağaçlar birbirine bağımlıdır.