
Welcome to an open source implementation of OpenAI's CLIP (Contrastive Language-Image Pre-training).
The goal of this repository is to enable training models with contrastive image-text supervision, and to investigate their properties such as robustness to distribution shift. Our starting point is an implementation of CLIP that matches the accuracy of the original CLIP models when trained on the same dataset. Specifically, a ResNet-50 model trained with our codebase on OpenAI's 15 million image subset of YFCC achieves 32.7% top-1 accuracy on ImageNet. OpenAI's CLIP model reaches 31.3% when trained on the same subset of YFCC. For ease of experimentation, we also provide code for training on the 3 million images in the Conceptual Captions dataset, where a ResNet-50x4 trained with our codebase reaches 22.2% top-1 ImageNet accuracy.
We further this with a replication study on a dataset of comparable size to OpenAI's, LAION-400M, and with the larger LAION-2B superset. In addition, we study scaling behavior in a paper on reproducible scaling laws for contrastive language-image learning.
We have trained:
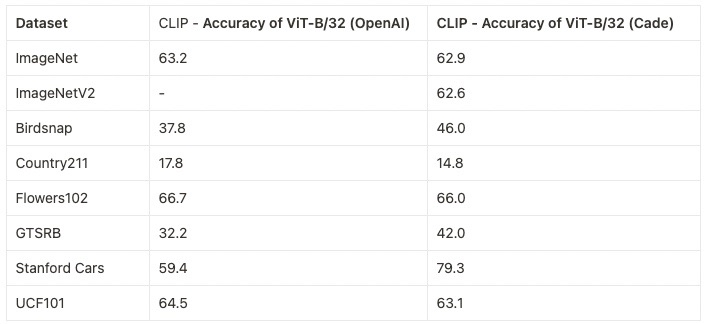
- ViT-B/32 on LAION-400M with a accuracy of 62.9%, comparable to OpenAI's 63.2%, zero-shot top-1 on ImageNet1k
- ViT-B/32 on LAION-2B with a accuracy of 66.6%.
- ViT-B/16 on LAION-400M achieving an accuracy of 67.1%, lower than OpenAI's 68.3% (as measured here, 68.6% in paper)
- ViT-B/16+ 240x240 (~50% more FLOPS than B/16 224x224) on LAION-400M achieving an accuracy of 69.2%
- ViT-L/14 on LAION-400M with an accuracy of 72.77%, vs OpenAI's 75.5% (as measured here, 75.3% in paper)
- ViT-L/14 on LAION-2B with an accuracy of 75.3%, vs OpenAI's 75.5% (as measured here, 75.3% in paper)
- ViT-H/14 on LAION-2B with an accuracy of 78.0. The best in1k zero-shot for released, open-source weights thus far.
- ViT-g/14 on LAION-2B with an accuracy of 76.6. This was trained on reduced schedule, same samples seen as 400M models.
As we describe in more detail below, CLIP models in a medium accuracy regime already allow us to draw conclusions about the robustness of larger CLIP models since the models follow reliable scaling laws.
This codebase is work in progress, and we invite all to contribute in making it more accessible and useful. In the future, we plan to add support for TPU training and release larger models. We hope this codebase facilitates and promotes further research in contrastive image-text learning. Please submit an issue or send an email if you have any other requests or suggestions.
Note that portions of src/open_clip/ modelling and tokenizer code are adaptations of OpenAI's official repository.
 |
|---|
| Image Credit: https://github.com/openai/CLIP |
pip install open_clip_torch
import torch
from PIL import Image
import open_clip
model, _, preprocess = open_clip.create_model_and_transforms('ViT-B-32-quickgelu', pretrained='laion400m_e32')
tokenizer = open_clip.get_tokenizer('ViT-B-32-quickgelu')
image = preprocess(Image.open("CLIP.png")).unsqueeze(0)
text = tokenizer(["a diagram", "a dog", "a cat"])
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs) # prints: [[1., 0., 0.]]To compute billions of embeddings efficiently, you can use clip-retrieval which has openclip support.
This repository is focused on training CLIP models. To fine-tune a trained zero-shot model on a downstream classification task such as ImageNet, please see our other repository: WiSE-FT. The WiSE-FT repository contains code for our paper on Robust Fine-tuning of Zero-shot Models, in which we introduce a technique for fine-tuning zero-shot models while preserving robustness under distribution shift.
To download datasets as webdataset, we recommend img2dataset
In addition to specifying the training data via CSV files as mentioned above, our codebase also supports webdataset, which is recommended for larger scale datasets. The expected format is a series of .tar files. Each of these .tar files should contain two files for each training example, one for the image and one for the corresponding text. Both files should have the same name but different extensions. For instance, shard_001.tar could contain files such as abc.jpg and abc.txt. You can learn more about webdataset at https://github.com/webdataset/webdataset. We use .tar files with 1,000 data points each, which we create using tarp.
You can download the YFCC dataset from Multimedia Commons. Similar to OpenAI, we used a subset of YFCC to reach the aforementioned accuracy numbers. The indices of images in this subset are in OpenAI's CLIP repository.
We advise you first create a virtual environment with:
python3 -m venv .env
source .env/bin/activate
pip install -U pip
You can then install openclip for training with pip install 'open_clip_torch[training]'.
If you want to make changes to contribute code, you can close openclip then run make install in openclip folder (after creating a virtualenv)
Install pip PyTorch as per https://pytorch.org/get-started/locally/
You may run make install-training to install training deps
Test can be run with make install-test then make test
python -m pytest -x -s -v tests -k "training" to run a specific test
Running regression tests against a specific git revision or tag:
-
Generate testing data
python tests/util_test.py --model RN50 RN101 --save_model_list models.txt --git_revision 9d31b2ec4df6d8228f370ff20c8267ec6ba39383
WARNING: This will invoke git and modify your working tree, but will reset it to the current state after data has been generated!
Don't modify your working tree while test data is being generated this way. -
Run regression tests
OPEN_CLIP_TEST_REG_MODELS=models.txt python -m pytest -x -s -v -m regression_test
python -m training.main \
--save-frequency 1 \
--zeroshot-frequency 1 \
--report-to tensorboard \
--train-data="/path/to/train_data.csv" \
--val-data="/path/to/validation_data.csv" \
--csv-img-key filepath \
--csv-caption-key title \
--imagenet-val=/path/to/imagenet/root/val/ \
--warmup 10000 \
--batch-size=128 \
--lr=1e-3 \
--wd=0.1 \
--epochs=30 \
--workers=8 \
--model RN50Note: imagenet-val is the path to the validation set of ImageNet for zero-shot evaluation, not the training set!
You can remove this argument if you do not want to perform zero-shot evaluation on ImageNet throughout training. Note that the val folder should contain subfolders. If it doest not, please use this script.
This code has been battle tested up to 1024 A100s and offers a variety of solutions for distributed training. We include native support for SLURM clusters.
As the number of devices used to train increases, so does the space complexity of
the the logit matrix. Using a naïve all-gather scheme, space complexity will be
O(n^2). Instead, complexity may become effectively linear if the flags
--gather-with-grad and --local-loss are used. This alteration results in one-to-one
numerical results as the naïve method.
For larger datasets (eg Laion2B), we recommend setting --train-num-samples to a lower value than the full epoch, for example --train-num-samples 135646078 to 1/16 of an epoch in conjunction with --dataset-resampled to do sampling with replacement. This allows having frequent checkpoints to evaluate more often.
Recent research has shown that one can dropout half to three-quarters of the visual tokens, leading to up to 2-3x training speeds without loss of accuracy.
You can set this on your visual transformer config with the key patch_dropout.
In the paper, they also finetuned without the patch dropout at the end. You can do this with the command-line argument --force-patch-dropout 0.
We make use of torchrun to launch distributed jobs. The following launches a
a job on a node of 4 GPUs:
cd open_clip/src
torchrun --nproc_per_node 4 -m training.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/The same script above works, so long as users include information about the number of nodes and host node.
cd open_clip/src
torchrun --nproc_per_node=4 \
--rdzv_endpoint=$HOSTE_NODE_ADDR \
-m training.main \
--train-data '/data/cc12m/cc12m-train-{0000..2175}.tar' \
--train-num-samples 10968539 \
--dataset-type webdataset \
--batch-size 320 \
--precision amp \
--workers 4 \
--imagenet-val /data/imagenet/validation/This is likely the easiest solution to utilize. The following script was used to train our largest models:
#!/bin/bash -x
#SBATCH --nodes=32
#SBATCH --gres=gpu:4
#SBATCH --ntasks-per-node=4
#SBATCH --cpus-per-task=6
#SBATCH --wait-all-nodes=1
#SBATCH --job-name=open_clip
#SBATCH --account=ACCOUNT_NAME
#SBATCH --partition PARTITION_NAME
eval "$(/path/to/conda/bin/conda shell.bash hook)" # init conda
conda activate open_clip
export CUDA_VISIBLE_DEVICES=0,1,2,3
export MASTER_PORT=12802
master_addr=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_ADDR=$master_addr
cd /shared/open_clip
export PYTHONPATH="$PYTHONPATH:$PWD/src"
srun --cpu_bind=v --accel-bind=gn python -u src/training/main.py \
--save-frequency 1 \
--report-to tensorboard \
--train-data="/data/LAION-400M/{00000..41455}.tar" \
--warmup 2000 \
--batch-size=256 \
--epochs=32 \
--workers=8 \
--model ViT-B-32 \
--name "ViT-B-32-Vanilla" \
--seed 0 \
--local-loss \
--gather-with-gradpython -m training.main \
--train-data="/path/to/train_data.csv" \
--val-data="/path/to/validation_data.csv" \
--resume /path/to/checkpoints/epoch_K.ptIf you wish to use different language models as the text encoder for CLIP you can do so by using one of the Hugging Face model configs in src/open_clip/model_configs and passing in it's tokenizer as the --model and --hf-tokenizer-name parameters respectively. Currently we only support RoBERTa ("test-roberta" config), however adding new models should be trivial. You can also determine how many layers, from the end, to leave unfrozen with the --lock-text-unlocked-layers parameter. Here's an example command to train CLIP with the RoBERTa LM that has it's last 10 layers unfrozen:
python -m training.main \
--train-data="pipe:aws s3 cp s3://s-mas/cc3m/{00000..00329}.tar -" \
--train-num-samples 3000000 \
--val-data="pipe:aws s3 cp s3://s-mas/cc3m/{00330..00331}.tar -" \
--val-num-samples 10000 \
--dataset-type webdataset \
--batch-size 256 \
--warmup 2000 \
--epochs 10 \
--lr 5e-4 \
--precision amp \
--workers 6 \
--model "roberta-ViT-B-32" \
--lock-text \
--lock-text-unlocked-layers 10 \
--name "10_unfrozen" \
--report-to "tensorboard" \When run on a machine with 8 GPUs the command should produce the following training curve for Conceptual Captions:
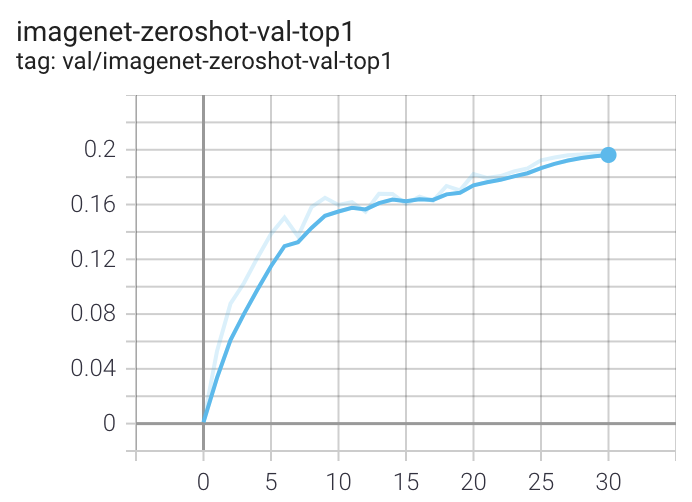
More detailed curves for Conceptual Captions are given at /docs/clip_conceptual_captions.md.
When training a RN50 on YFCC the same hyperparameters as above are used, with the exception of lr=5e-4 and epochs=32.
Note that to use another model, like ViT-B/32 or RN50x4 or RN50x16 or ViT-B/16, specify with --model RN50x4.
tensorboard --logdir=logs/tensorboard/ --port=7777python -m training.main \
--val-data="/path/to/validation_data.csv" \
--model RN101 \
--pretrained /path/to/checkpoints/epoch_K.ptpython -m training.main \
--imagenet-val /path/to/imagenet/validation \
--model ViT-B-32-quickgelu \
--pretrained laion400m_e32LAION-400M - https://laion.ai/laion-400-open-dataset
We are working on reproducing OpenAI's ViT results with the comparably sized (and open) LAION-400M dataset. Trained weights may be found in release v0.2.
The LAION400M weights have been trained on the JUWELS supercomputer (see acknowledgements section below).
We replicate OpenAI's results on ViT-B/32, reaching a top-1 ImageNet-1k zero-shot accuracy of 62.96%.
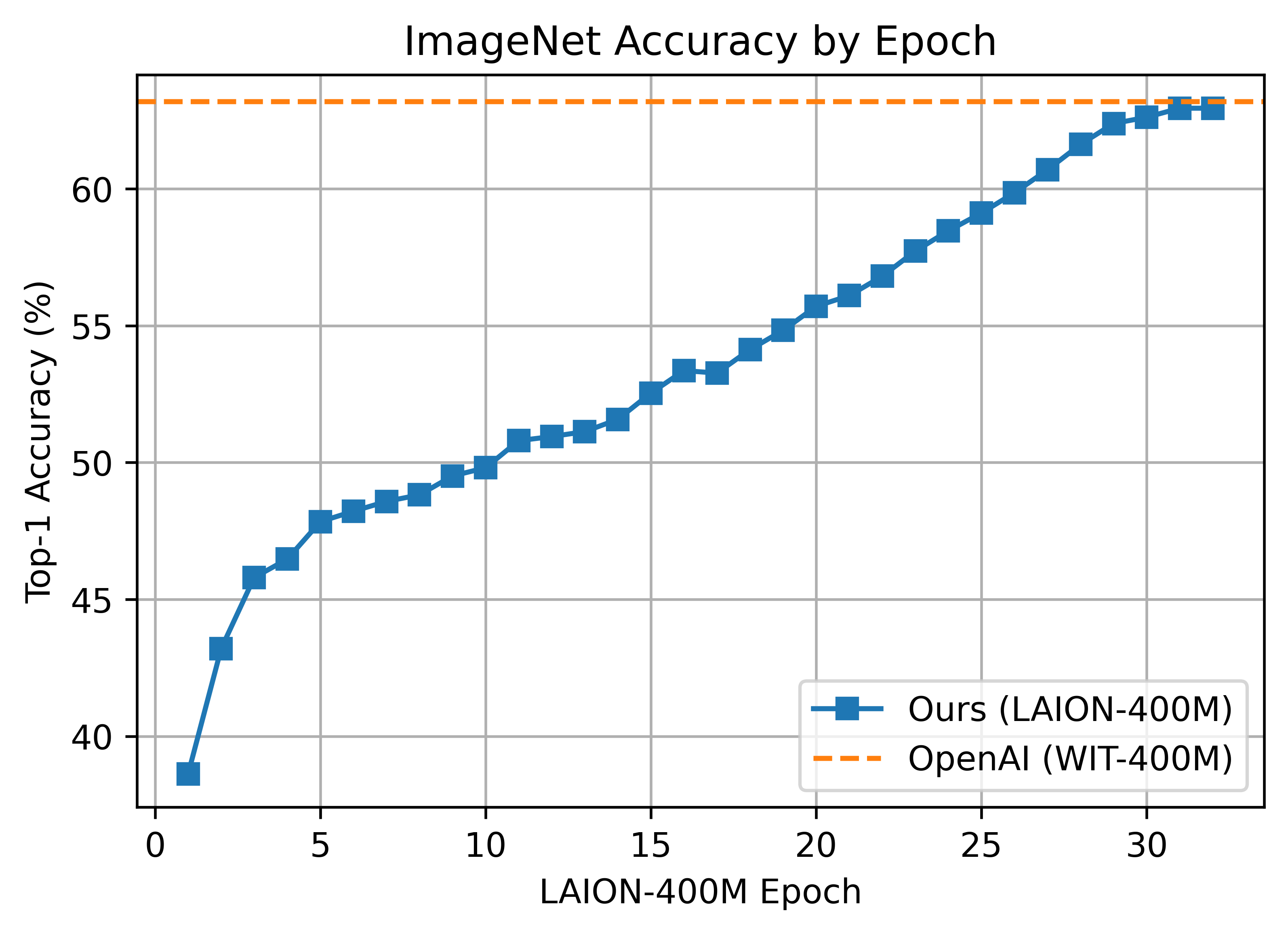
Zero-shot comparison (courtesy of Andreas Fürst)
ViT-B/32 was trained with 128 A100 (40 GB) GPUs for ~36 hours, 4600 GPU-hours. The per-GPU batch size was 256 for a global batch size of 32768. 256 is much lower than it could have been (~320-384) due to being sized initially before moving to 'local' contrastive loss.
The B/16 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 67.07.
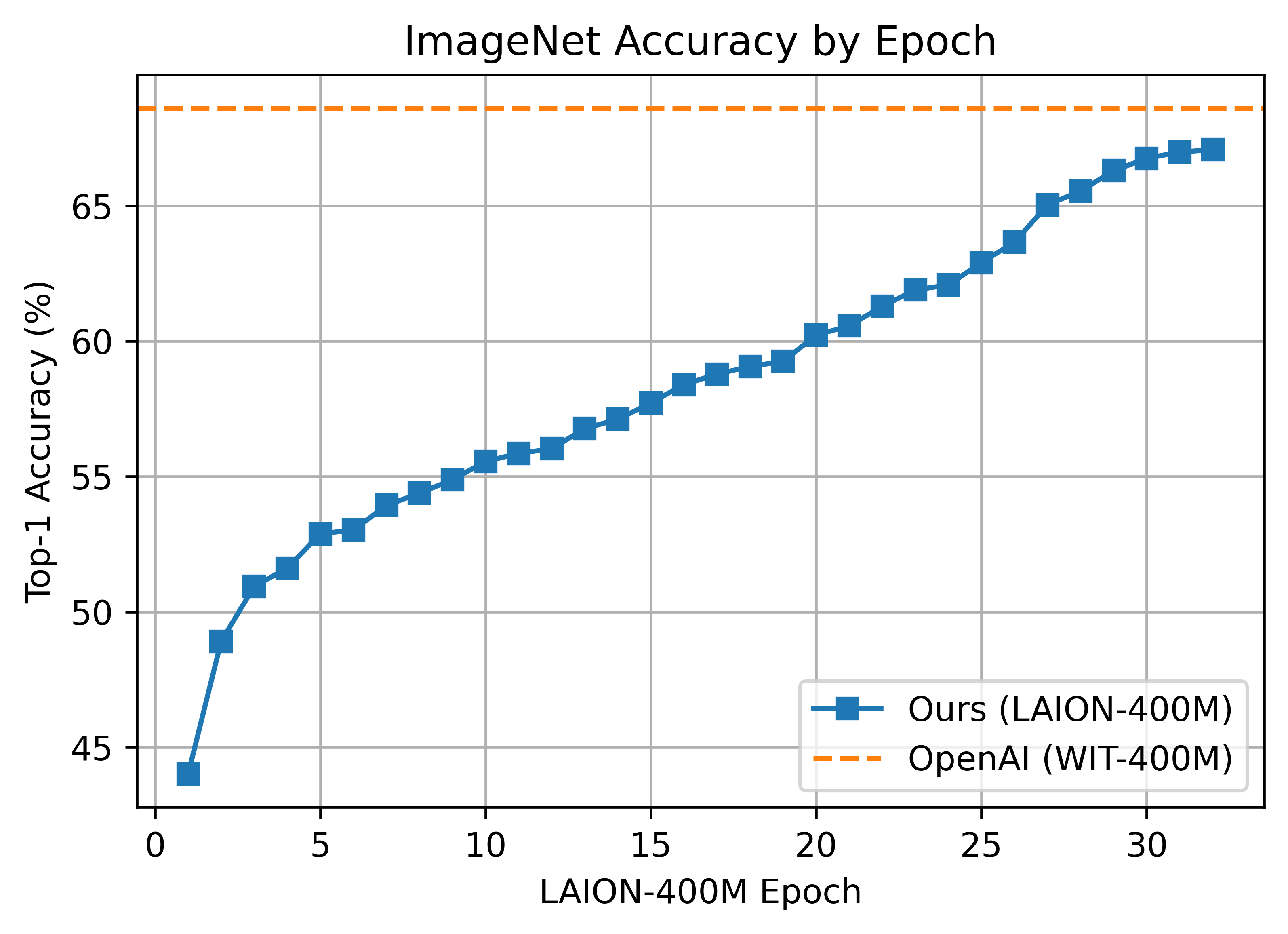
This was the first major train session using the updated webdataset 0.2.x code. A bug was found that prevented shards from being shuffled properly between nodes/workers each epoch. This was fixed part way through training (epoch 26) but likely had an impact.
ViT-B/16 was trained with 176 A100 (40 GB) GPUS for ~61 hours, 10700 GPU-hours. Batch size per GPU was 192 for a global batch size of 33792.
The B/16+ 240x240 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 69.21.
This model is the same depth as the B/16, but increases the
- vision width from 768 -> 896
- text width from 512 -> 640
- the resolution 224x224 -> 240x240 (196 -> 225 tokens)
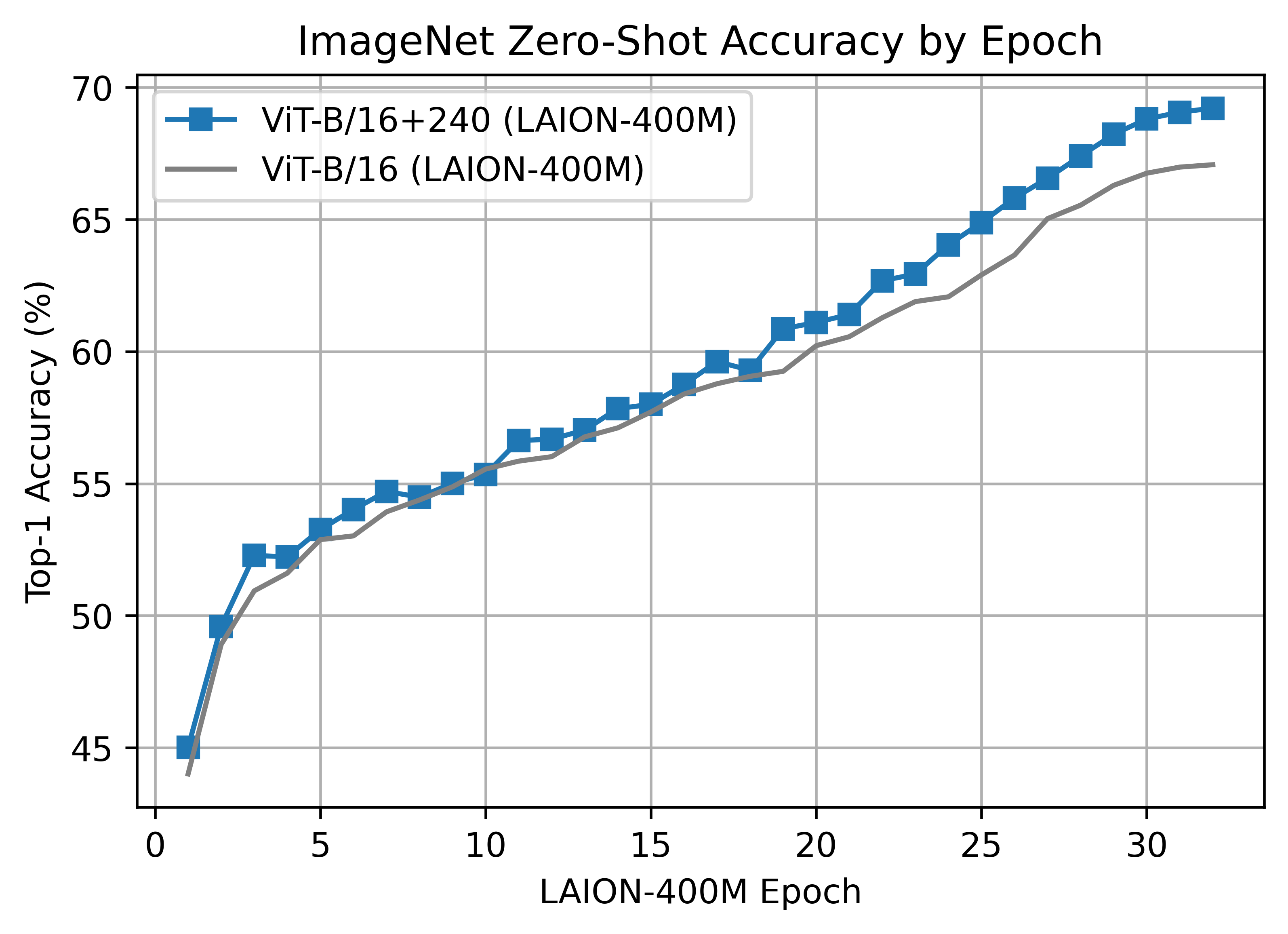
Unlike the B/16 run above, this model was a clean run with no dataset shuffling issues.
ViT-B/16+ was trained with 224 A100 (40 GB) GPUS for ~61 hours, 13620 GPU-hours. Batch size per GPU was 160 for a global batch size of 35840.
The L/14 LAION-400M training reached a top-1 ImageNet-1k zero-shot validation score of 72.77.
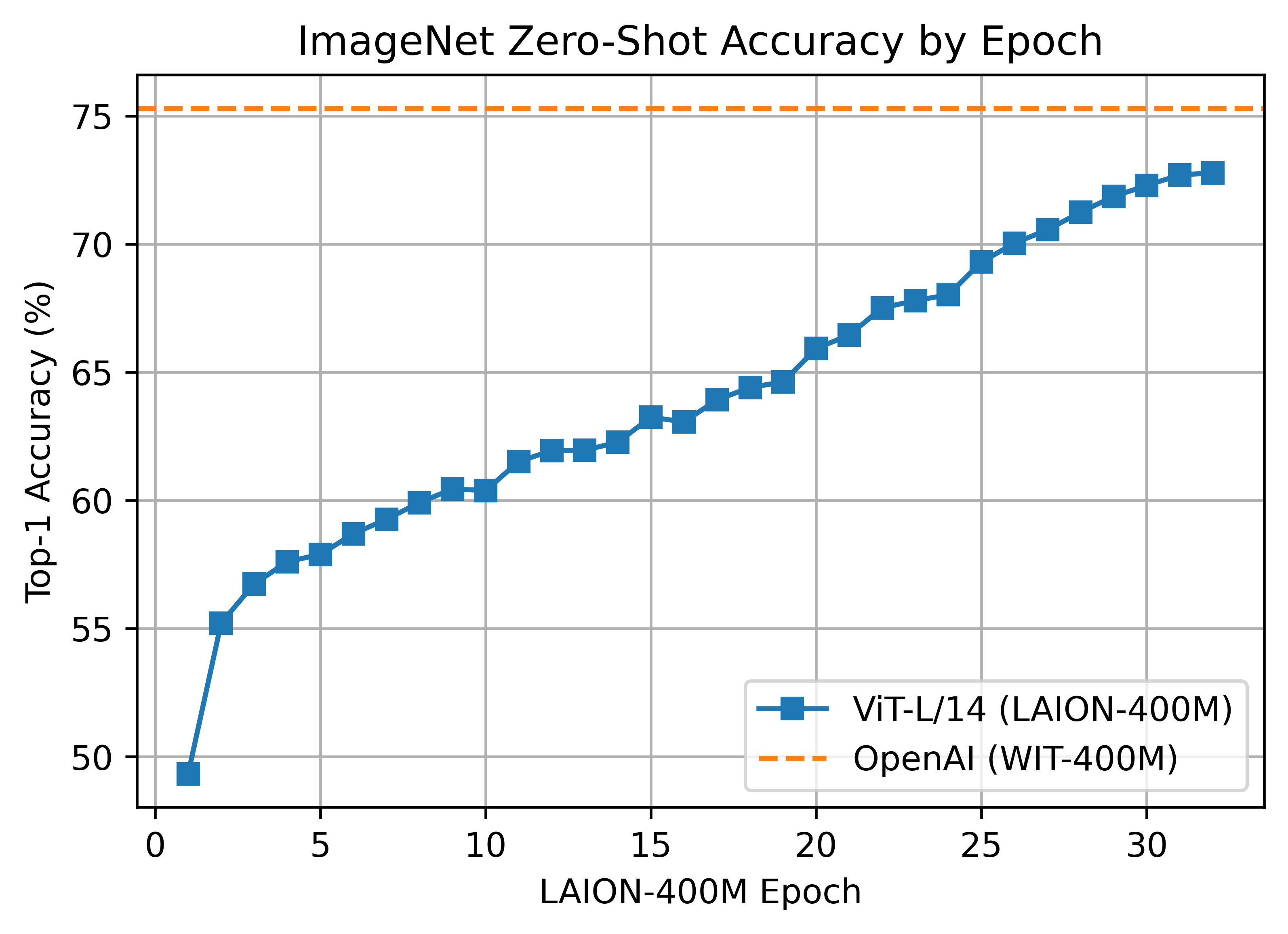
ViT-L/14 was trained with 400 A100 (40 GB) GPUS for ~127 hours, 50800 GPU-hours. Batch size per GPU was 96 for a global batch size of 38400. Grad checkpointing was enabled.
A ~2B sample subset of LAION-5B with english captions (https://huggingface.co/datasets/laion/laion2B-en)
A ViT-B/32 trained on LAION-2B, reaching a top-1 ImageNet-1k zero-shot accuracy of 65.62%.
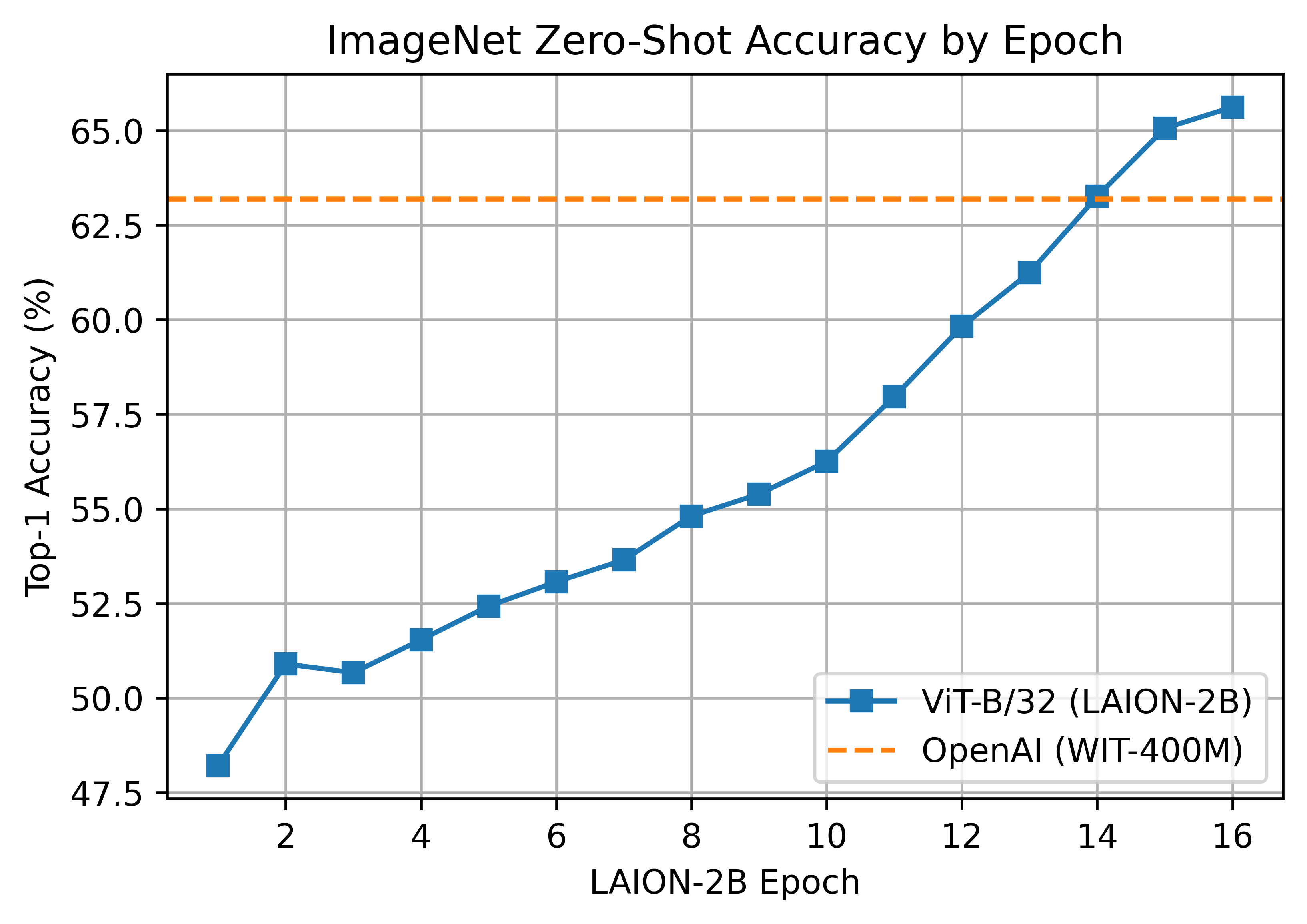
ViT-B/32 was trained with 112 A100 (40 GB) GPUs. The per-GPU batch size was 416 for a global batch size of 46592. Compute generously provided by stability.ai.
A second iteration of B/32 was trained on stability.ai cluster with a larger global batch size and learning rate, hitting 66.6% top-1. See https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K
A ViT-L/14 with a 75.3% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K
These weights use a different dataset mean and std than others. Instead of using the OpenAI mean & std, inception style normalization [-1, 1] is used via a mean and std of [0.5, 0.5, 0.5]. This is handled automatically if using open_clip.create_model_and_transforms from pretrained weights.
A ViT-H/14 with a 78.0% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K
A ViT-g/14 with a 76.6% top-1 ImageNet-1k zero-shot was trained on JUWELS Booster. See model details here https://huggingface.co/laion/CLIP-ViT-g-14-laion2B-s12B-b42K
This model was trained with a shorted schedule than other LAION-2B models with 12B samples seen instead of 32+B. It matches LAION-400M training in samples seen. Many zero-shot results are lower as a result, but despite this it performs very well in some OOD zero-shot and retrieval tasks.
A ViT-B/32 with roberta base encoder with a 61.7% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k This is the first openclip model using a HF text tower. It has better performance on a range of tasks compared to the standard text encoder, see metrics
A ViT-B/32 with xlm roberta base encoder with a 62.33% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-xlm-roberta-base-laion5B-s13B-b90k This is the first openclip model trained on the full laion5B dataset; hence the first multilingual clip trained with openclip. It has better performance on a range of tasks compared to the standard text encoder, see metrics A preliminary multilingual evaluation was run: 43% on imagenet1k italian (vs 21% for english B/32), 37% for imagenet1k japanese (vs 1% for english B/32 and 50% for B/16 clip japanese). It shows the multilingual property is indeed there as expected. Larger models will get even better performance.
A ViT-H/14 with xlm roberta large encoder with a 77.0% (vs 78% for the english equivalent) top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-H-14-frozen-xlm-roberta-large-laion5B-s13B-b90k
This model was trained following the LiT methodology: the image tower was frozen (initialized from english openclip ViT-H/14), the text tower was initialized from xlm roberta large and unfrozen. This reduced training cost by a 3x factor.
See full english metrics
On zero shot classification on imagenet with translated prompts this model reaches:
- 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
- 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
- 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
Below are checkpoints of models trained on YFCC-15M, along with their zero-shot top-1 accuracies on ImageNet and ImageNetV2. These models were trained using 8 GPUs and the same hyperparameters described in the "Sample running code" section, with the exception of lr=5e-4 and epochs=32.
- ResNet-50 (32.7% / 27.9%)
- ResNet-101 (34.8% / 30.0%)
- ResNet-50 (36.45%)
We offer a simple model interface to instantiate both pre-trained and untrained models.
NOTE: Many existing checkpoints use the QuickGELU activation from the original OpenAI models. This activation is actually less efficient than native torch.nn.GELU in recent versions of PyTorch. The model defaults are now nn.GELU, so one should use model definitions with -quickgelu postfix for the OpenCLIP pretrained weights. All OpenAI pretrained weights will always default to QuickGELU. One can also use the non -quickgelu model definitions with pretrained weights using QuickGELU but there will be an accuracy drop, for fine-tune that will likely vanish for longer runs.
Future trained models will use nn.GELU.
>>> import open_clip
>>> open_clip.list_pretrained()
[('RN50', 'openai'),
('RN50', 'yfcc15m'),
('RN50', 'cc12m'),
('RN50-quickgelu', 'openai'),
('RN50-quickgelu', 'yfcc15m'),
('RN50-quickgelu', 'cc12m'),
('RN101', 'openai'),
('RN101', 'yfcc15m'),
('RN101-quickgelu', 'openai'),
('RN101-quickgelu', 'yfcc15m'),
('RN50x4', 'openai'),
('RN50x16', 'openai'),
('RN50x64', 'openai'),
('ViT-B-32', 'openai'),
('ViT-B-32', 'laion400m_e31'),
('ViT-B-32', 'laion400m_e32'),
('ViT-B-32', 'laion2b_e16'),
('ViT-B-32', 'laion2b_s34b_b79k'),
('ViT-B-32-quickgelu', 'openai'),
('ViT-B-32-quickgelu', 'laion400m_e31'),
('ViT-B-32-quickgelu', 'laion400m_e32'),
('ViT-B-16', 'openai'),
('ViT-B-16', 'laion400m_e31'),
('ViT-B-16', 'laion400m_e32'),
('ViT-B-16-plus-240', 'laion400m_e31'),
('ViT-B-16-plus-240', 'laion400m_e32'),
('ViT-L-14', 'openai'),
('ViT-L-14', 'laion400m_e31'),
('ViT-L-14', 'laion400m_e32'),
('ViT-L-14', 'laion2b_s32b_b82k'),
('ViT-L-14-336', 'openai'),
('ViT-H-14', 'laion2b_s32b_b79k'),
('ViT-g-14', 'laion2b_s12b_b42k'),
('roberta-ViT-B-32', 'laion2b_s12b_b32k'),
('xlm-roberta-base-ViT-B-32', 'laion5b_s13b_b90k'),
('xlm-roberta-large-ViT-H-14', 'frozen_laion5b_s13b_b90k'),]
>>> model, train_transform, eval_transform = open_clip.create_model_and_transforms('ViT-B-32', pretrained='laion2b_s34b_b79k')To simulate larger batches use --accum-freq k. If per gpu batch size, --batch-size, is m, then the effective batch size will be k * m * num_gpus.
When increasing --accum-freq from its default of 1, samples/s will remain approximately constant (batch size will double, as will time-per-batch). It is recommended to use other features to reduce batch size such as --grad-checkpointing --local-loss --gather-with-grad before increasing --accum-freq. --accum-freq can be used in addition to these features.
Instead of 1 forward pass per example, there are now 2 forward passes per-example. However, the first is done with torch.no_grad.
There is some additional GPU memory required --- the features and data from all m batches are stored in memory.
There are also m loss computations instead of the usual 1.
For more information see Cui et al. (https://arxiv.org/abs/2112.09331) or Pham et al. (https://arxiv.org/abs/2111.10050).
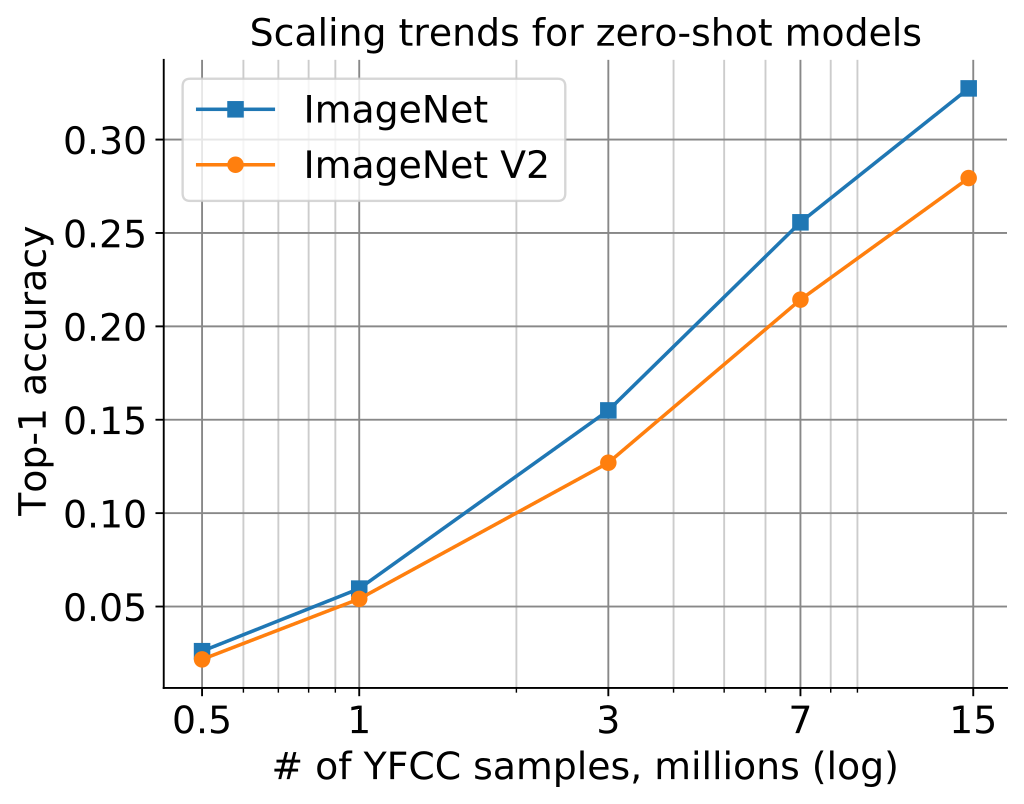
The plot below shows how zero-shot performance of CLIP models varies as we scale the number of samples used for training. Zero-shot performance increases steadily for both ImageNet and ImageNetV2, and is far from saturated at ~15M samples.
TL;DR: CLIP models have high effective robustness, even at small scales.
CLIP models are particularly intriguing because they are more robust to natural distribution shifts (see Section 3.3 in the CLIP paper). This phenomena is illustrated by the figure below, with ImageNet accuracy on the x-axis and ImageNetV2 (a reproduction of the ImageNet validation set with distribution shift) accuracy on the y-axis. Standard training denotes training on the ImageNet train set and the CLIP zero-shot models are shown as stars.
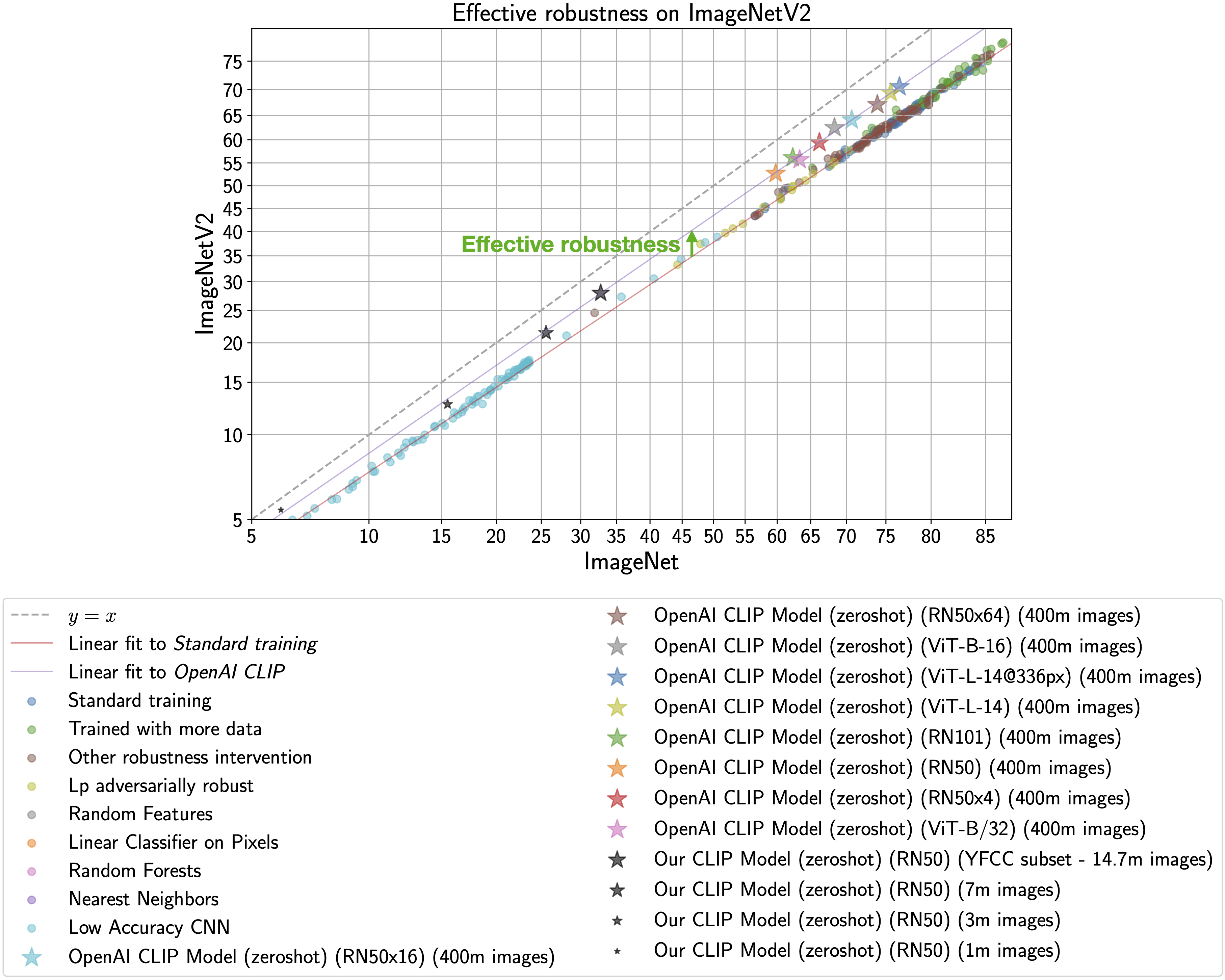
As observed by Taori et al., 2020 and Miller et al., 2021, the in-distribution and out-of-distribution accuracies of models trained on ImageNet follow a predictable linear trend (the red line in the above plot). Effective robustness quantifies robustness as accuracy beyond this baseline, i.e., how far a model lies above the red line. Ideally a model would not suffer from distribution shift and fall on the y = x line (trained human labelers are within a percentage point of the y = x line).
Even though the CLIP models trained with this codebase achieve much lower accuracy than those trained by OpenAI, our models still lie on the same trend of improved effective robustness (the purple line). Therefore, we can study what makes CLIP robust without requiring industrial-scale compute.
For more information on effective robustness, please see:
To know more about the factors that contribute to CLIP's robustness refer to Fang et al., 2022.
We gratefully acknowledge the Gauss Centre for Supercomputing e.V. (www.gauss-centre.eu) for funding this part of work by providing computing time through the John von Neumann Institute for Computing (NIC) on the GCS Supercomputer JUWELS Booster at Jülich Supercomputing Centre (JSC).
Current development of this repository is led by Ross Wightman, Cade Gordon, and Vaishaal Shankar.
The original version of this repository is from a group of researchers at UW, Google, Stanford, Amazon, Columbia, and Berkeley.
Gabriel Ilharco*, Mitchell Wortsman*, Nicholas Carlini, Rohan Taori, Achal Dave, Vaishaal Shankar, John Miller, Hongseok Namkoong, Hannaneh Hajishirzi, Ali Farhadi, Ludwig Schmidt
Special thanks to Jong Wook Kim and Alec Radford for help with reproducing CLIP!
If you found this repository useful, please consider citing:
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}