A set of artificial intelligences playing Survaillant game.
![]()
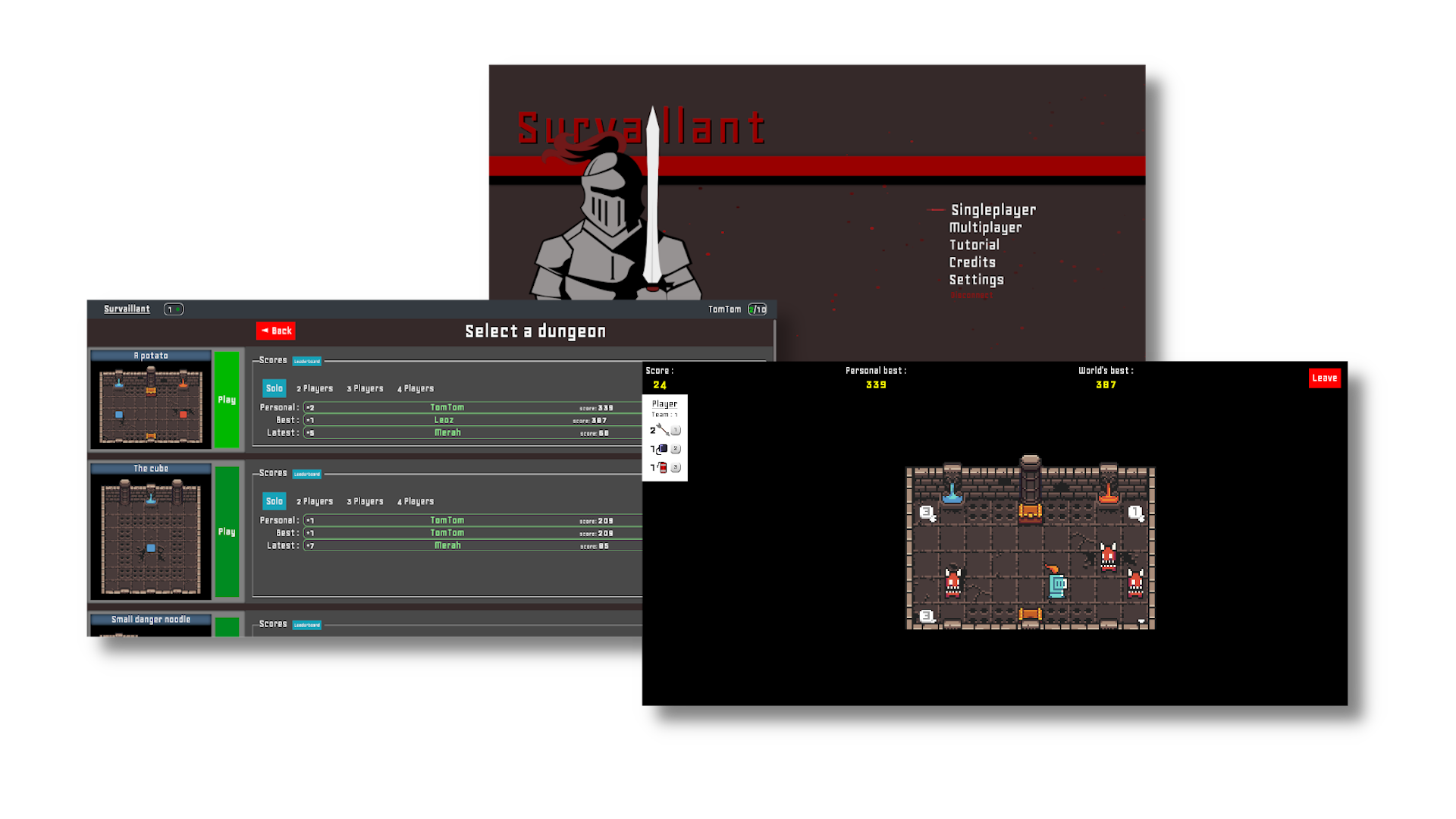
Survaillant is a reflexion and strategy game playable in solo, PVP or COOP. The goal is to stay alive as long as possible in a dungeon where monsters move only when you move.
Survaillant is very inspired by the mobile game Rust Bucket, but implement some unique multi-player features, and it is web hosted, you can play it HERE.
For this project, we are focussing on creating an AI that can play the game using reinforcement neural networks.
The artificial intelligences are based on a neural network trained with reinforcement learning.
The trained network takes the map in input (the values/shape of the input depends on the training environment, please refer to the training environment section) and returns the probability to select: left or right or up or down.
We have developed a training framework that allows multiple contexts of training. A training environment is defined by:
- A reward policy
- A state generator
Furthermore, we can train a network only on one map or on a list of maps where a map will be randomly selected for each game.
Indeed, we have to reward the AI for each decision that it makes. We define 4 consequences of a decision:
- Bad movement (the decision leads to an invalid movement of the player, e.g: movement that will cause an out of bounds)
- Moved (the decision represents a valid movement)
- Game over (the decision leads to a game over)
- Kill (the decision will kill a monster)
We have defined 4 policies: the bandit, neutral, score-based, and doom slayer.
Bandit is a policy that penalized a game over (-5) and bad movements (-1) but the game isn't considered as done in case of bad movement
unlike game over. If the AI moves or kills a monster, we reward it with +1.
Its identifier is bandit in script arguments.
Neutral is a policy that uses the same rules as the real game. It penalizes a game over and bad movements with -5
and in both cases, the game is done. If the AI moves or kills a monster, we reward it with +1.
Its identifier is neutral in script arguments.
It's a policy based on neutral (apply the same rewards) but the reward for movements and kills
is the delta between the current in-game score and the last in-game score. Its identifier is score_based in script arguments.
It's a policy based on neutral (apply the same rewards) but a kill is rewarded with +5.
Its identifier is doom_slayer in script arguments.
A network takes in input a tensor, so we need to define a function to transform the game's state into a tensor. We have defined two representations of the map: flashlight mode, normal mode.

In normal mode, the network takes in input the whole map and the map should be smaller or equal to the input shape of the network. The main downside of this mode is that the network will have more issues to play on a map larger than the map used for training.

In flashlight mode, the network takes in input the surrounding of the player (e.g: only 8 squares around it if the radius is 1). With this mode, the network can play on any map easily, but it has less information about further entities on the map.
The tensor is a 3D-array, so we use the first two dimensions to define the position of an entity and the last to represent multiple entities that are in the same position (e.g: a player can be on a spawning trap) or to separate them to add meaning for entities that are on the same level (here level is the term to define the position of an entity on the last dimension).
In the summary mode, monsters and players are on the same level and other elements are on another level. Every entity and its states are represented with a unique value.
In the real mode, monsters and players are on the same level and other elements are on another level. Every entity are represented only if they are visible with a unique value. Monster spawns and chest spawns are represented with the same values.
In exhaustive mode, walls are on a level, players are on a level, monsters are on a level, and spawning entities are on a level. For spawning entities, they aren't represented unless they would kill the player if he steps on them.
lint: a script used to perform code static analysis and code format checklint:fix: a script used to fix formatting issues in codeexample:random: a script used to run games with random actionsvalidate: a script used to validate a trained network on multiple maps
Scripts related to network training are explained in Modules section.
Each module defines a network trained with a specific model. Models used are based on examples given by Keras library.
A module defining a network that plays the game using a Deep Q Learning model. You can train a network with:
npm run dqn:train
Please refer to the documentation of the script for more information about its parameters (cmd: npm run dqn:train -- -h).
A module defining a network that plays the game using a Proximal Policy Optimization model. You can train a network with:
npm run ppo:train
Please refer to the documentation of the script for more information about its parameters (cmd: npm run ppo:train -- -h).
You can either train networks created from scratch or existing ones.
A module defining a network that plays the game using a Deep Deterministic Policy Gradient model. You can train a network with:
npm run ddpg:train
Please refer to the documentation of the script for more information about its parameters (cmd: npm run ddpg:train -- -h).
You can either train networks created from scratch or existing ones.
- NodeJS (16.13.0 and above)