![]()
A server application designed to control GPU fan speeds based on temperature readings and machine learning. This is able to dynamically adjust fan speeds to optimize hardware performance and longevity, especially when you are using a GPU that is not supported by the vendor for fan control, like using customer level GPU on a enterprise level server.
Table of Contents
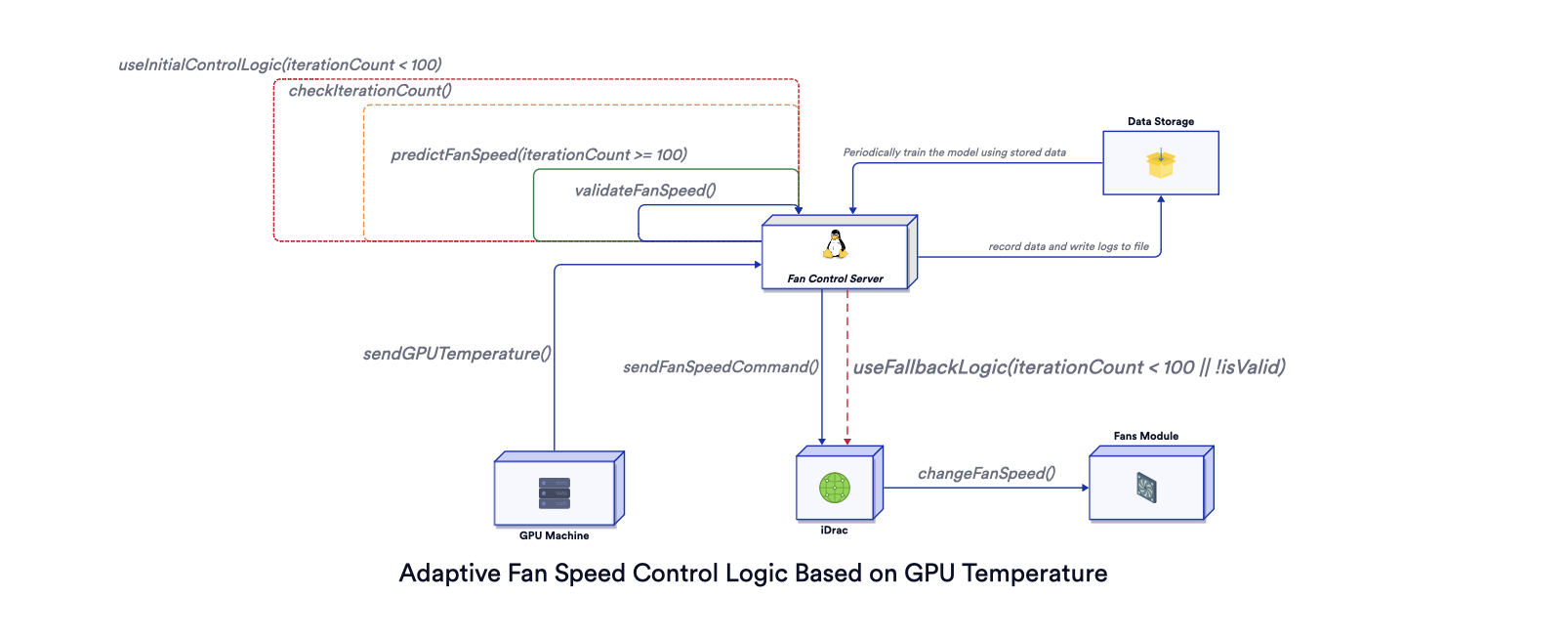
Quiet Cool is a server application designed to control GPU fan speeds based on temperature readings. It dynamically adjusts fan speeds to optimize hardware performance and longevity. Below is a figure that shows how it works and you can find the live version here. Source code for the figure is available here.
The script in this project will take over the fan control of your homelab server. Brace yourself for a wild ride! Just remember, with great power comes great responsibility... and the potential for some seriously cool airflow. But hey, I must warn you, this operation is like riding a rollercoaster blindfolded. It's a risky adventure that could leave your hardware feeling a bit shaken, not stirred. So, buckle up, hold on tight, and use this script at your own risk. I take no responsibility for any unexpected fan-induced windstorms or hardware mishaps. Happy fan-controlling! 🌪️💨
- Dynamic Fan Speed Control: Adjusts GPU fan speeds in real-time based on temperature data.
- REST API: Provides an API endpoint for remote temperature data reception and fan speed control.
- Logging and Monitoring: Logs detailed information about temperature readings, fan speed adjustments, and system errors.
- Dell PowerEdge R720: A server with a GPU passed through to an ubuntu 22.04 VM.
The initial control logic is defined as a mathematical function:
After the initial 100 iterations using the above control logic, a machine learning model is used to predict the optimal fan speed. The model is trained using a custom loss function designed to balance fan noise and GPU temperature, penalizing the model when noise exceeds residential standards or the GPU temperature is too high.
The custom loss function (L) used during training is defined as follows:
L = MSE(f_pred, f_true) + (1/n) * sum( P_noise(n_i) + P_temp(t_i) for i=1 to n)
Where:
f_predis the predicted fan speed.f_trueis the actual fan speed.P_noise(n_i)is the penalty for noise, defined as:
P_noise(n_i) =
• 200 if n_i < 0.5
• 1 otherwise
P_temp(t_i)is the penalty for temperature, defined as:
P_temp(t_i) =
• 200 if t_i < 50°C
• 1 otherwise
-
$P_\text{temp}(t_i)$ is the penalty for temperature, defined as:
n_iis the predicted noise level in dB.t_iis the predicted temperature in °C.nis the number of predictions.
- Python 3.6+
-
- flask
-
- numpy
-
- pandas
-
- tensorflow (up to what you have on the machine that runs the flask server)
nvidia-smicommand-line utility on your GPU-Passed-Through machinecurlcommand-line utility on your GPU-Passed-Through machine to post GPU temperature to the fan control flask server.
- Clone the Repository
git clone https://github.com/yourusername/quiet-cool.git
cd quiet-cool- Set Up Python Environment
You really should use a virtual environment to avoid conflicts with other Python projects. Here's how to set up a virtual environment using venv:
python3 -m venv venv
source venv/bin/activate
pip install -r requirements.txt- Run the Server
python fan_control_server.pyUse the script monitor_gpu_temp.sh to send GPU temperatures to the server:
#!/bin/bash
# monitor_gpu_temp.sh: Script to monitor GPU temperature and send it to a remote machine
REMOTE_ADDRESS="http://your_flask_server:23333" # Replace with your remote machine's address
get_gpu_temp() {
nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader,nounits
}
while true; do
TEMP=$(get_gpu_temp)
echo "GPU Temperature: $TEMP°C"
curl -X POST -d "temperature=$TEMP" $REMOTE_ADDRESS/gpu-temperature
sleep 10
donePOST /gpu-temperature
- Request:
temperature- current GPU temperature. - Response:
200 OK- fan speed adjusted.
- Remodel the noise level calculation to include more factors by diving deeper into the specifics of the fan module.
- [⏳] Research on the possiblity of using different fan speed control modes. E.g. quiet mode, performance mode, responsive mode, etc.
- Start the frontend user interface development to allow user to modify settings and add some observability to the user interface. (I just kick started node.js courses and let's see how long it will take.)
- Support more Machines.
The current noise level calculation is based on a simplified model and may not accurately reflect the actual noise produced by the fan module, resulting in suboptimal fan speed adjustments. Ideally, the noise level should be calculated using the actual fan speed retrieved from iDRAC and the specifications of the fans. However, as I am not an acoustic engineer, I will temporarily assume that this calculation is sufficient until I find a better solution. Any suggestions are welcome.
Currently, the penalization of noise and temperature is based on a simplified quadratic function. However, this approach may not accurately capture the real-world impact of noise and temperature on user experience and hardware longevity. At the moment, my focus is on timely adjustments, which is why the penalization is set to be somewhat aggressive. In future versions, I plan to refine these models based on more detailed research and valuable user feedback.
Contributions are welcome. Please open an issue to discuss proposed changes or improvements.
This project is available under the MIT License. See LICENSE.md for more details.
For any questions or collaborations, feel free to reach out via email:
- T.X : 📧 Email: tingrubato@outlook.com