- 검색(retrieval)과 독해(reading)를 통해 질문에 대한 답을 도출하는 task
-
HW: AI Stage (NVIDIA V100 32GB)
-
기술: Python, PyTorch, HuggingFace
-
협업: Git(GitHub), Notion, Slack
-
모니터링: WandB
- Read data from CSV
- Random multi-passage negative sampling
- Domain- or Task-adaptive pre-training
- retrieval에 BM25 적용
- 모델 탐색 및 실험
- sweep, 앙상블 구현
- Dense passage retrieval
- Prompt learning
- Add BiLSTM layer
- 외부 데이터 수집
- [UNK] 토큰 처리 실험
- k-fold를 이용한 학습 안되는 부분 재학습
- hugging face 모델들 가져와서 실험
| 실험 | PLM | top k | EM (Public) | F1 (Public) |
|---|---|---|---|---|
| Baseline (TF/IDF) | klue/bert-base | 10 | 35.42 | 48.41 |
| 4.1.1. bm25 기본값 실험 | klue/bert-base | 20 | 33.33 | 45.77 |
| 4.1.1. bm25 기본값 실험 | Kdogs/klue-finetuned-squard_kor_v1 | 20 | 34.58 | 45.34 |
| 4.1.1. bm25 use bert word piece tokenizer | Kdogs/klue-finetuned-squard_kor_v1 | 10 | 49.17 | 60.67 |
| 4.1.1. bm25 use bert word piece tokenizer | Kdogs/klue-finetuned-squard_kor_v1 | 20 | 46.25 | 56.81 |
| 실험 | PLM | 세부사항 | EM (Public) | F1 (Public) | EM (Eval) | F1 (Eval) |
|---|---|---|---|---|---|---|
| Baseline | klue/bert-base | base | 35.42 | 48.41 | 55.833 | 41.721 |
| 4.2.1 학습이 잘 안되는 Valid Dataset 재학습 | klue/bert-base | base+학습 안되는 부분 | 30.42 | 42.61 | 51.72 | 38.84 |
| 4.2.2. Negative Sampling in Reader | klue/roberta-large | 3 random passages | 59.58 | 70.70 | 66.250 | 74.289 |
| 4.2.3. Adaptive Pre-Training | klue/roberta-large | lr: 3e-5 / top k: 20 / bm25 | 61.67 | 72.21 | 67.500 | 77.404 |
| 4.2.4. 외부데이터 수집 | klue/roberta-large | ETRI_MRC_v1 / top k: 20 / bm25 | 60.42 | 72.35 | 68.333 | 76.248 |
| 4.2.4. 외부데이터 수집 | klue/roberta-large | KorQuAD 1.0 / top k: 20 / bm25 | 53.33 | 67 | 70 | 77.493 |
| 4.2.4. 외부데이터 수집 | klue/roberta-large | ko_wiki_v1_squad / top k: 20 / bm25 | 54.58 | 67.98 | 69.583 | 78.077 |
| 4.2.4. 외부데이터 수집 | klue/roberta-large | ETRI_MRC_v1 / 물음표 있는 데이터만 추가 / top k: 20 / bm25 | 55.42 | 66.58 | 69.167 | 76.385 |
| 4.2.5. [UNK] 토큰 처리 | klue/roberta-large | 341개 단어 vocab에 추가 / top k: 20 / bm25 | 53.75 | 63.77 | 69.583 | 77.741 |
| 4.2.5. [UNK] 토큰 처리 | klue/roberta-large | escape() vocab에 추가 / top k: 20 / bm25 | 60.42 | 70.18 | 69.167 | 77.261 |
| 4.2.6. Prompt Learning | klue/roberta-large | top k: 20 / bm25 | 60.83 | 72.24 | 70.83 | 79.19 |
| 4.2.7. BiLSTM layer 추가 | klue/roberta-large | lr: 1e-5 / top k: 20 / bm25 | 54.17 | 67.76 | 69.58 | 77 |
| 4.2.8. Model Selection | klue/roberta-large | top k: 20 / bm25 | 62.50 | 71.24 | 70.41 | 79.25 |
| 4.2.8. Model Selection | wooy0ng/korquad1-klue-roberta-large | top k: 50 / bm25 | 61.67 | 71.65 | 68.33 | 77.585 |
| 4.2.8. Model Selection | snunlp/KR-ELECTRA-discriminator | top k: 10 / bm25 | 40.42 | 54.87 | 57.91 | 67.02 |
| 4.2.8. Model Selection | inhee/8_roberta-large_train_korquad-1_2_aihubf | top k: 10 / bm25 | 60.00 | 69.88 | 72.91 | 80.32 |
| 4.2.8. Model Selection | nlpotato/roberta_large_origin_added_korquad | top k: 10 / bm25 | 55.00 | 66.46 | 71.82 | 79.53 |
| 방법 | EM (Public) | F1 (Public) |
|---|---|---|
| 하드 보팅 | 67.08 | 74.9 |
| 소프트 보팅 | 65.42 | 73.28 |
| 하드 보팅 + weight | 70.00 | 77.39 |
| 소프트 보팅 + weight | 68.75 | 76.6 |
- Retriever: TF-IDF
- Reader(PLM): klue/bert-base
[Data information]
- KLUE - MRC (only from Wikipedia source)
- Train: 3,952; Eval: 240; Test: 600
[Token lengths]
-
context, question, answer_text의 토큰 길이 확인
-
context (train, eval)
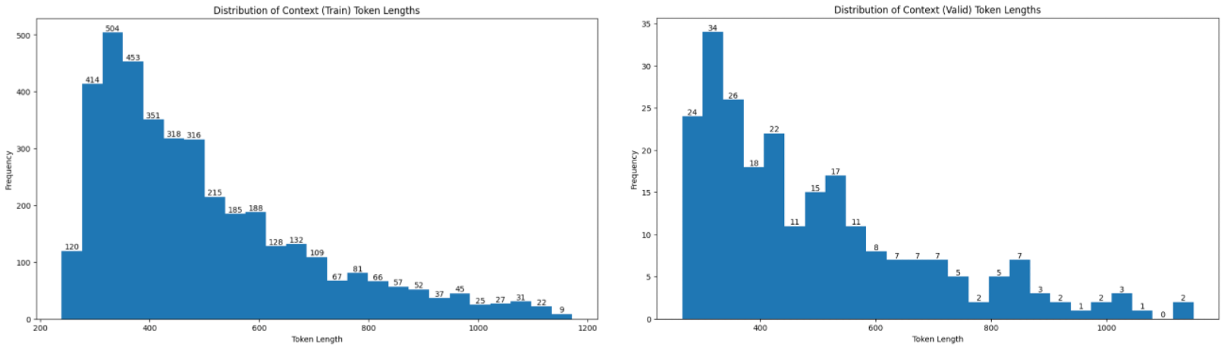
- Histogram으로 확인 시 train과 eval에서 큰 차이 없으며 왼쪽으로 편포된 형태
- 평균적으로 450~500 토큰 정도이나, 최소 약 250 토큰, 최대 1200 토큰까지 존재
-
question (train, eval, test)

- 모두 정규 분포 형태를 띠며 평균적으로 16 토큰 정도의 길이
- train에 35 이상의 outliers가 극소수 존재하는 것을 제외하면 최대 30~35 토큰 정도
-
answer (train, eval)
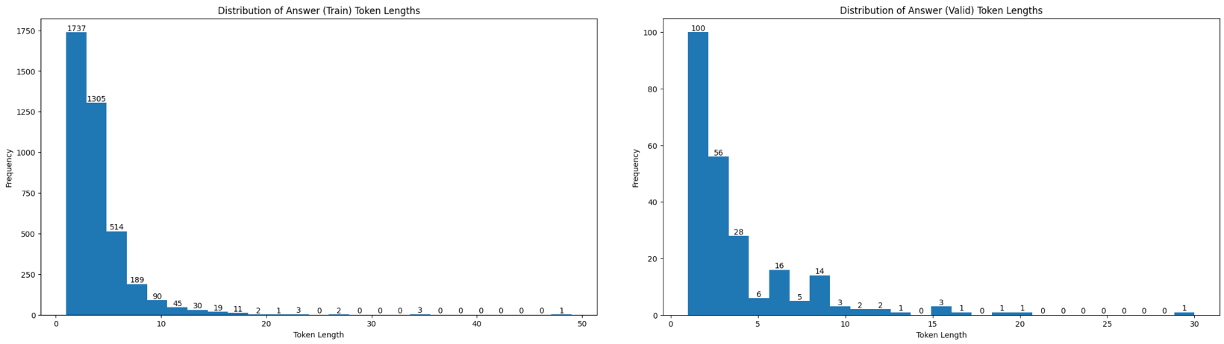
- 평균적으로 3~4 토큰이나, 최대 30 토큰을 넘어가는 정답들도 존재(대사 인용 등으로 추정)



[Answer start positions]
-
context의 길이(글자 기준) 대비 answer_start의 비율 (train, eval)
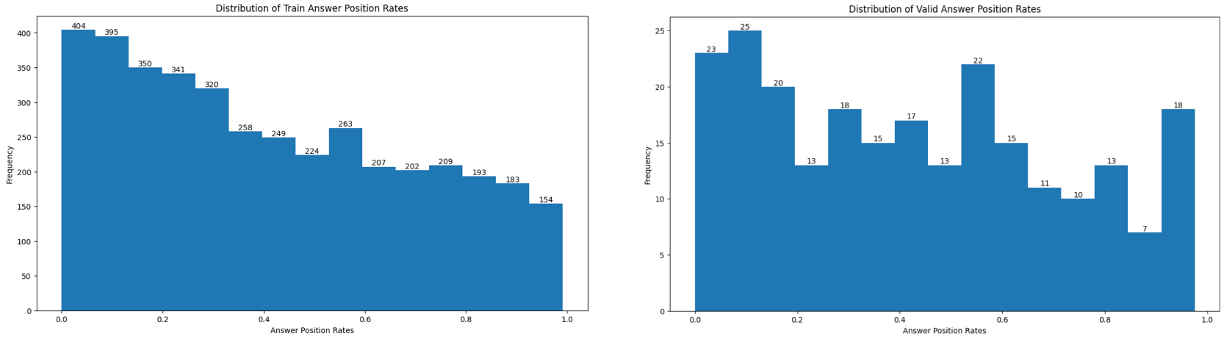
- 데이터 개수에 따라 조금 편차가 있는 것으로 추정 되나, train과 eval에서 약간 다른 결과 도출
- train의 경우 정답이 초반부에 훨씬 높은 비율로 분포하며, eval의 경우 train에 비해 편차가 크지 않고 중/말단부에도 적지 않게 분포하는 것을 확인

[Answer inclusion]
-
context내 answer_text의 출현 빈도 (train, eval)
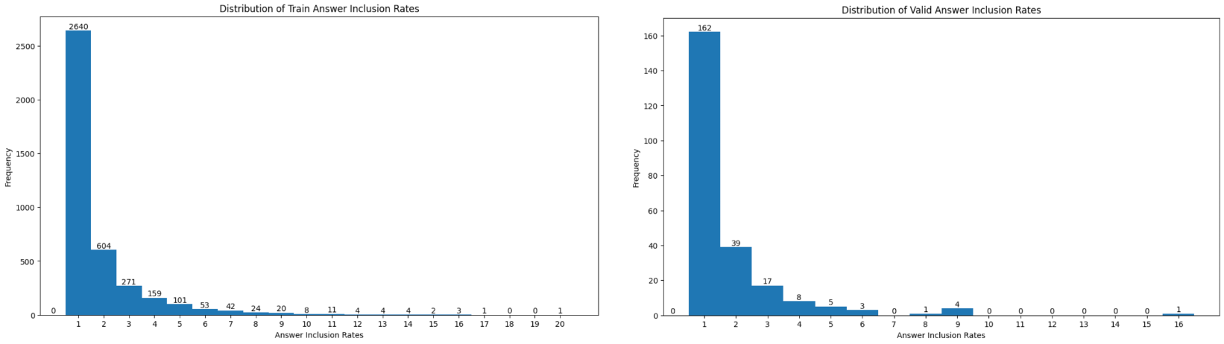
- 예상했던 결과이나 역시 1번 등장하는 경우가 가장 많았음
- 아마 크라우드 소싱 가이드라인에 문서의 주요 주제와 관련된 문제를 내지 말도록 지시되어 있지 않았나 추측

[Evaluation (without Retrieval, only with Reader)]
- EM: 55.8333 / F1: 66.3662
[Evaluation (with Retrieval)]
- EM: 35.4167 / F1: 41.7212
[Public]
- EM: 35.42 / F1: 48.41
[동기]
- retrieval의 성능을 높이기 위해 base로 사용되던 TF/IDF보다 개선된 bm25를 사용
[과정 및 결과]
-
TF/IDF는 단어가 얼마나 반복되는지, 얼마나 자주 사용되는 단어인지를 계산에 사용
$$\text{Score}(D,Q) = \displaystyle\sum_{\text{term}\in Q}\text{TF-IDF}(\text{term},Q) *\text{TF-IDF}(\text{term},D)$$ -
bm25는 TF-IDF 의 개념을 바탕으로, 문서의 길이까지 고려하여 점수를 매김
$$\text{Score}(D,Q) = \sum_{\text{term} \in Q} \text{IDF}(\text{term}) \cdot \frac{\text{TF-IDF}(\text{term}, D) \cdot (k_1+1)}{\text{TF-IDF}(\text{term},D) + k_1 \cdot (1-b+b \cdot \frac{|D|}{\text{avgdl}})}$$ -
rank_bm25 라이브러리 [1] 사용
-
라이브러리의 기본값은 공백 단위로 문서를 토크나이징
- TF-IDF 보다 성능 하락
-
이를 개선하기 위해 bert의 word piece 토크나이저를 사용해 토크나이징
- TF-IDF 보다 public exact match 44 → 49 개선
[retrieve 성능 비교]
-
eval dataset(240개) 사용, 질문에 대한 top k 문서 안에 실제 정답 지문이 있는지 계산
클래스 bm25Okapi bm25Plus bm25Plus top k 10 10 20 accuracy 89.1 89.5 93.3 클래스 bm25Okapi bm25Okapi bm25Okapi top k 3 5 7 accuracy 78.3 83.5 86.6 -
top k가 클수록 정답을 포함하는 경우가 많아짐
-
하지만 reader와의 결합 결과 k=10~20이 가장 성능이 높았음
[동기 및 방법론]
- Passage encoder와 Query encoder를 각각 학습하고, 두 encoder output 내적 값을 관계도로 계산 [2]
- 이 때 Negative Sampling을 이용해 학습
- 한 Query에 대해 Positive passage 1개, Negative passages 3개를 묶고, positive passage를 ground truth로 하는 Negative Log Likelihood Loss로 학습
- 한 batch에서 negative sampling을 수행하는 in-batch negative sampling도 적용
[결과]
- 두 encoder를 각각 학습하고, 검증을 위해 학습 데이터에 존재하는 query를 모델 input으로 사용
- 학습에 이용한 데이터이므로 top-5 passage 내에 ground truth passage가 존재하기를 기대했으나, 전혀 추출하지 못 하는 것을 발견
- In-batch negative sampling을 적용해도 같은 결과
[고찰]
- Random으로 negative passage를 가져오게 되어 학습이 어려웠다고 판단
- BM25 또는 TF-IDF로 유사한 passage를 negative passage로 학습했다면, 좀 더 좋은 결과가 있었을 것으로 예상
[동기 및 방법론]
- BM25 Plus만 사용하지 않고, 동일 모듈 내 BM25 Okapi를 같이 사용해 각각 retriever에서 top K/2 추출
- 다양한 retriever에서 추출한 context가 retrieval 성능을 더 높일 것으로 예상
[결과]
- BM25 Plus에서 10개, BM25 Okapi에서 10개 retrieval 후 concat
- EM: 62.5 (Best 동일) / F1: 71.81 (Best 대비 0.57 상승)
[고찰]
- 중복 context 제거 과정을 수행하지 않아 중복이 많았을 것
- 결국 retrieval 추이가 비슷해 큰 성능 향상을 기대할 순 없었다고 예상

- 학습이 안되는 부분을 한 번 더 학습시키면 그에 대한 EM score가 오르지 않을까 생각하여 진행
- Original 데이터를 다섯 부분으로 나누기(K-fold)
- K-fold를 적용하여 train 시켜 각 부분에서 학습이 안되는 부분 추출
- 추출한 데이터를 기존 original 데이터에 붙여 증강시키고 증강된 데이터를 Retrain
[결과]
- 재학습하는 과정에서 과적합 문제가 생겨서 그런지 EM score가 떨어짐.
- Public (with retrieval)
- EM : 30.42 (Base 대비 2.08점 하락) / F1: 42.61 (Base대비 1.67점 하락)
[동기 및 방법론]
- Retriever-reader의 2-stage 모델은 검색된 k개의 passage를 하나로 concat한 후, 그 안에서 하나의 answer span을 추측하는 extraction-based approach
- 그러나 reader 모델은 해당 question에 대한 답변이 반드시 존재하는 단일 context에서 answer span을 찾는 학습만을 수행 → Reader에도 효과적인 학습을 돕는 negative sample이 더 필요하지 않을까?
- 만약 reader 모델 자체에서 애초에 여러 passages가 concat된 다중 context에서 answer span을 찾는 학습을 수행한다면 어떨까?
- wikipedia_documents의 text 중 문단 단위 passage를 임의 선택하여 train과 eval 데이터의 context에 임의 순서로 추가(answer_start도 마찬가지로 변경)
- 어떤 의미에서 sparse-embedding-based retrieval 과정에서 하지 못한 negative sampling을 reader 단에서 수행하는 것이라 볼 수도 있을 듯
[결과]
-
3-passage with baseline model → klue/bert-base + TF-IDF
-
Validation (without retrieval, only reader)
EM: 59.583 (Baseline 대비 3.750점 상승) F1: 67.202 (Baseline 대비 0.836점 상승)
-
Public (with retrieval)
EM: 34.17 (Baseline 대비 1.25점 하락) F1: 46.50 (Baseline 대비 1.91점 하락)
-
-
3-passage with best model → klue/roberta-large + BM25
-
Validation (without retrieval, only reader)
EM: 66.250 (Best 대비 4.167점 하락) F1: 74.289 (Best 대비 4.968점 하락)
-
Public (with retrieval)
EM: 59.58 (Best 대비 2.92점 하락) F1: 70.07 (Best 대비 1.17점 하락)
-
[고찰]
-
가설에서 결과가 가장 많이 벗어났던 실험 중 하나
-
기반이 되는 reader의 성능이 좋을 수록 multi-passage 내 정답 탐색 능력이 좋을 것
⇒ klue/bert-base에서는 reader eval 성능이 큰 폭으로 상승했으나, 오히려 klue/roberta-large에서 더 큰 폭으로 하락함
-
Reader의 성능이 상승하면, retrieval을 포함하여 inference 했을 때 당연히 top-k passages 내 정답 탐색 능력이 상승할 것
⇒ klue/bert-base에서 reader eval metric이 모두 상승하였으나, public에서 모두 1점 이상 하락
-
-
결과 분석 및 (시도하지 못한) 향후 수정 방향
- 원래는 3-passage 성능이 좋은 경우 10-passage를 실험해보려 했으나, 3-passage 성능이 좋지 못해 중단. 그러나 2-passage부터 차근히 실험했어야 했음 ⇒ 1~5 passages의 성능 비교 필요
- Random passages의 negative가 너무 강했던 것으로 추정. 즉, 유사한 passages가 top-k로 주어졌을 때 sharpness가 감퇴한 듯 ⇒ wikipedia_documents 내 임의 선택이 아닌 top-k passages 내 순위별 선택 필요
[동기 및 방법론]
- Reader의 train과 eval 데이터에는 정답 passage가 이미 주어져있지만, test 데이터의 retrieval 범위가 되는 wikipedia_documents의 크기가 train 데이터보다 너무나 방대함 (중복 제외 약 20배 차이)
- 역대 대회 중 처음으로 corpus 데이터가 주어졌는데, 이걸 활용할 방법이 없을까?
- wikipedia_documents 자체를 PLM에 추가적으로 MLM pretraining (RobertaForMaskedLM 사용)
- LineByLineTextDataset을 이용해 개행 문자를 기준으로 데이터를 분리했으며, block_size는 기존 PLM의 max_seq_length와 동일한 384로 설정
- 온전한 본문 텍스트를 담은 문장만 담도록 정제: 한글 최소 1글자 포함, 영어/한글/숫자/한자로 시작, 정제되지 않은 HTML 및 문서 메타데이터 제거, in-line 개행 및 불필요 공백 제거, 50글자 이상 등
- 일종의 domain- 또는 task-adaptive pretraining (DAPT 또는 TAPT) [3]이며, 둘 중 하나로 분류하기에는 wikipedia_documents가 domain 데이터이면서 동시에 task dataset의 상위 집합이기 때문에 그냥 adaptive PT로 서술
[결과]
- Pretraining
- masked_accuracy: 72.89 (%) (기존 PLM 대비 5.13점 상승)
- Inference
-
Validation (without retrieval, only reader)
EM: 67.500 (기존 PLM 대비 2.910점 하락) F1: 77.404 (기존 PLM 대비 1.846점 하락)
-
Public (with retrieval)
EM: 61.67 (기존 PLM 대비 0.83점 하락) F1: 72.21 (기존 PLM 대비 0.97점 상승)
-
[고찰]
- 가설이 맞다면 validation 과정의 metric도 상승했어야 하지만, 작지 않은 점수차로 성능이 하락한 것을 확인
- 아마 기존 PLM(klue/roberta-large)과 비교했을 때, 학습 데이터의 구조적 측면이 변경되었을 수 있음. 본 학습에서 사용된 데이터는 여러 정제 조건을 거친 line-by-line의 데이터이나, 실제 PLM의 MLM 학습 시에는 더 큰 단위의 텍스트(e.g., document 단위)를 일괄적으로 학습했을 가능성이 높음. 즉, PLM 입장에서 데이터 퀄리티가 저하된 것으로 생각됨
- [UNK] 처리되는 단어는 많이 없었지만, Wikipedia 문서 특유의 많은 고유명사 및 고어의 등장은 효율적인 학습에 굉장히 좋지 않은 요소였다고 생각됨. 정제 조건 또한 매우 간소화하여 주관적 판단으로 설정하였고, 데이터 자체도 셔플되어 loader에 들어갔기 때문에 문맥 파악에 어려움이 있었을 것이라 생각됨
[동기]
- 기존 학습 데이터셋은 3,952 개의 샘플을 가짐
- klue mrc 학습 데이터셋은 17,555 개의 샘플을 가짐
- 따라서 데이터의 수를 늘려 성능을 올릴 수 있다고 판단
- klue mrc는 사용을 하지 못했기에 외부 데이터셋 사용
[방법론]
- 사용한 데이터셋은 다음과 같음
- ETRI_MRC_v1 [4]
- ETRI에서 Exobrain에 학습시키기 위해 사용한 데이터셋
- 10,000개의 샘플을 가짐
- KorQuAD 1.0 [5]
- LG CNS에서 개발한 MRC 데이터셋
- 60,407개의 샘플을 가짐
- ko_wiki_v1_squad [6]
- AI Hub 일반상식 데이터셋
- 104,220개의 샘플을 가짐
- ETRI_MRC_v1 [4]
[결과]
-
ETRI_MRC_v1
- Validation (without retrieval, only reader)
- EM: 68.333 (Best 대비 2.084점 하락) F1: 76.248 (Best 대비 3.009점 하락) 70.417 79.257
- Public (with retrieval)
- EM: 60.42 (Best 대비 2.08점 하락) F1: 72.35 (Best 대비 1.11점 상승)
- Validation (without retrieval, only reader)
-
KorQuAD 1.0
- Validation (without retrieval, only reader)
- EM: 70 (Best 대비 0.417점 하락) F1: 77.493 (Best 대비 1.764점 하락)
- Public (with retrieval)
- EM: 53.33 (Best 대비 12.17점 하락) F1: 67 (Best 대비 4.24점 하락)
- Validation (without retrieval, only reader)
-
ko_wiki_v1_squad
- Validation (without retrieval, only reader)
- EM: 69.583 (Best 대비 0.834점 하락) F1: 78.077 (Best 대비 1.180점 하락)
- Public (with retrieval)
- EM: 54.58 (Best 대비 7.92점 하락) F1: 67.98 (Best 대비 3.26점 하락)
- Validation (without retrieval, only reader)
[고찰]
-
검증된 외부데이터셋을 추가했음에도 기존 학습데이터셋보다 성능이 떨어짐
-
제일 성능 하락이 적었던 데이터셋은 ETRI_MRC_v1
-
성능을 올릴 여지가 보였기에 이 데이터셋을 살펴보던 중 question 열의 원소 마지막에 물음표가 붙지 않은 데이터도 있음을 발견
-
기존 학습 데이터 샘플은 3950 / 3952 (99%)으로 대부분 물음표가 마지막에 붙음
-
이를 제거한 데이터 샘플들만 추가한 추가 실험 진행
[방법론]
- 10,000개의 샘플 중 question 열의 원소 마지막에 물음표가 붙지 않은 데이터를 제외한 7,417 샘플을 기존 학습 데이터에 추가
[결과]
- Validation (without retrieval, only reader)
- EM: 69.167 (Best 대비 1.250점 하락) / F1: 76.385 (Best 대비 2.872점 하락)
- Public (with retrieval)
- EM: 55.42 (Best 대비 7.08점 하락) / F1: 66.58 (Best 대비 4.66점 하락)
[고찰]
- 물음표가 있고 없고의 형식이 성능에 영향을 줄 수 있다고 판단
- 특히 이번 태스크의 경우 물음표가 없는 데이터를 추가하는게 오히려 성능이 더 높음
- 일반화 측면에서 도움이 되었을 것이라 판단. 또한 test 데이터에도 물음표가 없는 데이터가 있을 가능성 확인
[동기]
- \n의 \을 비롯해 [UNK] 토큰으로 처리하는 단어가 전체 샘플 3952 개 중 3732 개에서 발견
- [UNK] 토큰은 정보의 손실을 발생
- 따라서 이를 처리
[방법론]
- [UNK] 토큰으로 처리된 단어 중 한문을 포함한 외국어를 제거
- 이후 3개 이상 나온 341개의 단어를 vocab에 추가
[결과]
- Validation (without retrieval, only reader)
- EM: 69.583 (Best 대비 0.834점 하락) / F1: 77.741 (Best 대비 1.516점 하락)
- Public (with retrieval)
- EM: 53.75 (Best 대비 8.45점 하락) / F1: 63.77 (Best 대비 7.47점 하락)
- Private (with retrieval)
- EM: 53.06 (Best 대비 4.16점 하락) / F1: 63.5700 (Best 대비 6.10점 하락)
[고찰]
-
[UNK] 토큰을 처리한게 성능 하락으로 이어짐
-
사전학습을 진행할 때 사용되지 않은 단어였기 때문에 파인튜닝 단계에서 오히려 성능이 하락했다고 판단
-
빈도수가 제일 높은 이스케이프 문자만 처리해주면 사전학습 과정에서도 충분히 학습이 가능하다고 판단
-
이를 위한 추가 실험 진행
[방법론]
- 이스케이프 문자()에 대해서만 vocab에 추가
[결과]
- Validation (without retrieval, only reader)
- EM: 69.167 (Best 대비 1.250점 하락) / F1: 77.261 (Best 대비 1.996점 하락)
- Public (with retrieval)
- EM: 60.42 (Best 대비 2.08점 하락) / F1: 70.18 (Best 대비 0.06점 하락)
- Private (with retrieval)
- EM: 60.2800 (Best 대비 3.06점 상승) / F1: 71.7300 (Best 대비 2.06점 상승)
[고찰]
- private에서 성능이 상승함
- \ 빈도수는 22,810임에 반해 다른 [UNK] 토큰으로 처리되는 단어의 최대 빈도수는 318이었음
- 빈도수가 낮은 단어의 [UNK] 처리는 오히려 성능 하락으로 이어짐
- 최대 빈도수만 처리하는 것이 그 외의 것들도 같이 처리하는 것보다 효과적임
[동기 및 방법론]
- Retrieval 성능에 비해 Reader 성능이 많이 낮은 것으로 판단
- Reader가 context를 더 잘 이해할 수 있도록 question에 부가적인 prompt를 추가 후 학습
[결과]
- Question 앞에 title 추가
- 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은? → [Title] 미국 상원 [Title] 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은?
- EM: 60.83 (Best 대비 1.67 하락) / F1: 72.24 (Best 대비 1.00 상승)
- Question 형식 변경
- 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은? → 주어진 질문에 올바른 정답을 지문에서 찾아 줘: 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은?
- EM: 57.92 (Best 대비 4.58 하락) / F1: 69.93 (Best 대비 1.31 하락)
- Question의 noun, verb만 추출해 추가, 구분 가능한 special token(@@@) 추가
- 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은? → 대통령을 포함한 미국의 행정부 견제권을 갖는 국가 기관은? @@@ 대통령 포함 미국 행정부 견제 갖는 국가 기관 @@@
- EM: 55 (Best 대비 7.25 하락) / F1: 65.97 (Best 대비 5.27 하락)
[고찰]
- 질문에만 추가적인 정보를 부여하면, 더 질문을 잘 이해하고 본문에서 답을 추출하리라 예상
- 질문을 잘 이해한 것과 이를 문단에서 추출하는 것은 별개의 문제로 판단
[동기 및 방법론]
- HuggingFace QuestionAnswering Model 마지막 layer에 BiLSTM layer를 추가
- 기존 일반 fully-connected layer 보다 BiLSTM layer가 추가되면 더 문맥을 잘 이해할 것으로 예상
[결과]
- 마지막 layer에 BiLSTM 추가
- EM: 52.92 (Best 대비 9.58 하락) / F1: 64.63 (Best 대비 6.61 하락)
- 기존에 xaiver initialization 추가 및 학습률 낮춰서 진행
- EM: 54.17 (Best 대비 8.33 하락) / F1: 67.76 (Best 대비 3.48 하락)
[고찰]
- 과정이 순탄하지 않았다. 많은 부분을 수정해야 했고, 그 과정에서 무언가 잘못 건드렸을 수도 있다고 생각
- 모델이 복잡해지면서 일반화 성능이 떨어지지 않았을까 예상
-
klue/bert-base [7, 8]
- base line에 제공된 모델
- EM (public): 35
-
Kdogs/klue-finetuned-squad-kor-v1 [10]
- klue/bert-base 모델에 squad-kor-v1 데이터를 fine tuning한 모델
- EM (public): 45
-
klue/roberta-large [12]
- EM (public): 62.5
-
nlpotato/roberta_large_origin_added_korquad [14]
- EM (public): 55.0
-
wooy0ng/korquad1-klue-roberta-large [9]
- klue/roberta-large 모델에 korquad1 데이터를 fine tuning한 모델
- EM (public): 61.6
-
snunlp/KR-ELECTRA-discriminator [11]
- EM (public): 40
-
inhee/8_roberta-large_train_korquad-1_2_aihubf [13]
- EM (public): 60
- inference의 출력 중 예측 값인 predictions.json을 사용해 하드 보팅
- em 62.5 → 67
- 동률일 때 가중치를 부여해 선택하는 방식
- 성능 동일
- inference 출력 중 각 질문에 따라 예측한 20개의 정답과 확률이 저장된 nbest_predictions.json을 사용해 소프트 보팅
- em 62.5 → 65.4
- 앞선 대회보다 어려운 점이 많았지만 포기하지 않고 끝까지 구현하려고 노력했다는 점
- 성능이 하락했을 때 거기서 끝나는 것이 아닌 원인 분석과 추가 실험이라는 고찰의 과정을 통해 유효한 지식을 확장해나간 점
- 개선사항이기도 하나 여러 기법을 시도했지만 성능 향상으로 이어지지 않았다는 점. 즉 아직은 배울 것이 많고 인사이트를 늘려야 한다는 점
- 실험을 진행할 때 확실히 진행하는 이유와 진행 중간 과정들은 조금 더 체계적으로 발전했으나, 그 사후 처리가 미흡했던 점. 이번처럼 public과 private의 간극이 있는 경우에 당장의 실험에 성능이 조금 떨어졌더라도 깊게 파보면 돌파구가 나올 수도 있다고 느낌
- klue/roberta-large 모델은 [UNK] 토큰을 처리하고 개행 문자를 제거했을 때보다 pretraining을 거쳤던 환경에서 더 좋은 성능을 보임. 이를 통해 pretraining 환경을 잘 유지하며 파인튜닝하는 것이 성능 향상으로 이어짐을 알게 됨
- transformers 라이브러리를 깊게 공부해볼 수 있었음
- rank_bm25: https://github.com/dorianbrown/rank_bm25
- Karpukhin, V., Oğuz, B., Min, S., Lewis, P., Wu, L., Edunov, S., ... & Yih, W. T. (2020). Dense passage retrieval for open-domain question answering.
- Gururangan, S., Marasović, A., Swayamdipta, S., Lo, K., Beltagy, I., Downey, D., & Smith, N. A. (2020). Don't stop pretraining: Adapt language models to domains and tasks. arXiv preprint arXiv:2004.10964.
- ETRI_MRC_v1: https://aiopen.etri.re.kr/corpusModel
- KorQuAD 1.0: https://korquad.github.io/KorQuad 1.0/
- ko_wiki_v1_squad: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=106
- Park, S., Moon, J., Kim, S., Cho, W. I., Han, J., Park, J., ... & Cho, K. (2021). Klue: Korean language understanding evaluation. arXiv preprint arXiv:2105.09680.
- klue/bert-base: https://huggingface.co/klue/bert-base
- wooy0ng/korquad1-klue-roberta-large: https://huggingface.co/wooy0ng/korquad1-klue-roberta-large
- Kdogs/klue-finetuned-squad-kor-v1: https://huggingface.co/Kdogs/klue-finetuned-squad_kor_v1
- snunlp/KR-ELECTRA-discriminator: https://huggingface.co/snunlp/KR-ELECTRA-discriminator
- klue/roberta-large: https://huggingface.co/klue/roberta-large
- inhee/8_roberta-large_train_korquad-1_2_aihubf: https://huggingface.co/inhee/8_roberta-large_train_korquad-1_2_aihubf
- nlpotato/roberta_large_origin_added_korquad: https://huggingface.co/nlpotato/roberta_large_origin_added_korquad